Lei Note du réseau Feng: Cet article est une compilation du blog de la technologie de groupe de Lei Feng, le titre original Intuitivement Comprendre Convolutions pour Deep apprentissage, auteur Irhum Shafkat.
Traduction | Zhipeng Relecture Zhao Pengfei | Dixiu Chuan finition | Jiang Fan

Ces derničres années, avec l'émergence d'un cadre puissant d'apprentissage profond, pour construire un réseau de neurones convolution devient trčs facile ŕ apprendre dans le modčle de profondeur, ou męme une seule ligne de code peut ętre complété.
Mais il faut comprendre convolution, en particulier pour la premičre fois le contact avec convolution réseau de neurones, il noyaux de convolution concept souvent confus, les filtres, et d'autres canaux et leur architecture d'empilage tel. Cependant convolution est un concept puissant et hautement évolutive, dans cet article, nous allons progressivement briser les principes de fonctionnement de convolution, son niveau liaisons réseau connecté pleinement, et d'explorer comment construire une solide hiérarchie visuelle, ce qui rend image haute performance caractéristique d'extraction.
2 convolution dimensions: opérateur
2 convolution dimensionnelle est une opération assez simple: depuis le début du noyau de convolution, qui est une petite matrice de poids. Le noyau de convolution ŕ deux dimensions sur les données d'entrée « glissement » de certains éléments de la multiplication de la matrice d'entrée en cours, puis les résultats sont résumés dans un seul pixel de sortie.
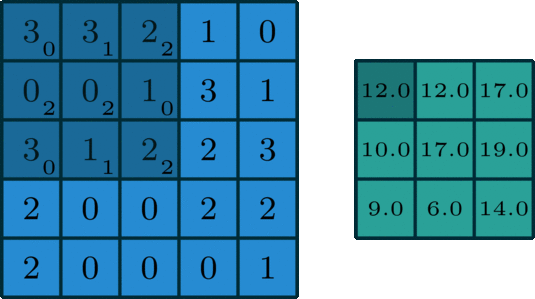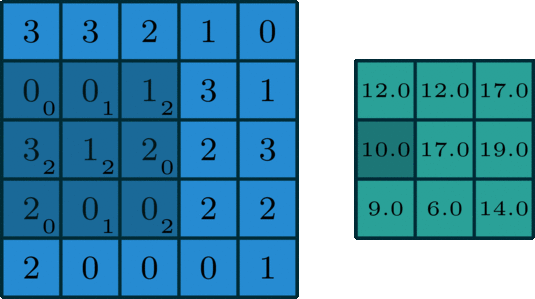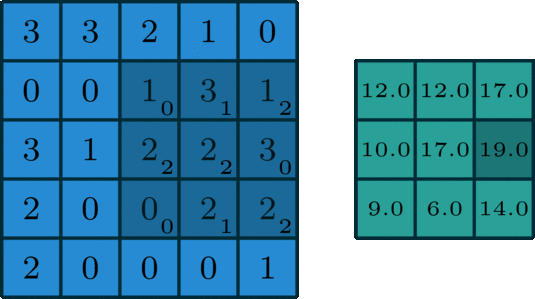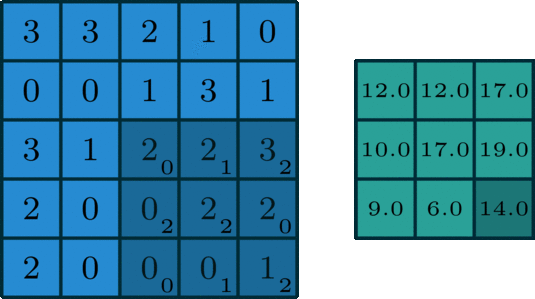
Une norme convolutif
Ce processus est répété noyau de convolution savoir traverser toute l'image, une matrice ŕ deux dimensions dans une autre matrice ŕ deux dimensions. Dans lequel la sortie et l'entrée pondérée sensiblement dans la męme position sur les données (poids du noyau de convolution est une valeur elle-męme)
Si les données d'entrée entrent dans cette « zone ŕ peu prčs semblable », détermine directement les données de sortie aprčs que le noyau de convolution. Cela signifie que la taille du noyau de convolution détermine directement la quantité de convergence (ou plusieurs) fonction d'entrée lors de la création de nouvelles fonctionnalités.
Ceci est tout ŕ fait contraire ŕ la couche entičrement connecté. Dans l'exemple ci-dessus, nous vous proposons entrée est de 5 * 5 = 25, les données de sortie est égal ŕ 3 * 3 = 9. Si l'on utilise une norme entičrement connecté couche, elle produira un 25 * 9 = 225 paramčtre matrice de poids chaque sortie est la somme pondérée de toutes les données d'entrée. opération de Convolution nous permet de réaliser cette transformation avec seulement neuf paramčtres, caractéristiques de chaque sortie ne sont pas « voir » chaque fonction d'entrée, mais juste « voir » la fonction d'entrée d'environ au męme endroit. S'il vous plaît noter car il est essentiel pour nous plus tard dans la discussion.
Certaines techniques couramment utilisées
Avant de continuer ŕ introduire convolution de réseau de neurones, la couche de convolution décrit deux techniques couramment utilisées: Rembourrage et Strides
-
Padding: Si vous voyez l'animation ci-dessus, vous remarquerez que dans le processus de convolution noyaux diapositive, le bord est essentiellement « coupé » out, comportera 5 * 5 transformation de la matrice est caractérisée par 3 * 3 matrice. Pixels sur le bord de l'éternité est pas au centre du noyau de convolution, parce que rien du noyau peut s'étendre au-delŕ des bords. Ce n'est pas idéal parce que nous voulons souvent la taille de la sortie est égale ŕ l'entrée.

Certaines opérations de remplissage
Rembourrage a des moyens trčs intelligents pour résoudre ce problčme: avec des pixels de « faux » supplémentaires (généralement une valeur de 0, si souvent utilisé le terme « zéro padding ») de bord rempli. Ainsi, lorsque le noyau de convolution peut permettre un coulissement pixel de bord brut en son centre, tout en prolongeant au-delŕ du bord du pixel factice, résultant en entrée et en sortie de la męme taille.
Striding: Lors de l'exécution couche de convolution, on généralement souhaitable que la taille d'entrée de la sortie est plus faible. Il est courant dans le réseau neuronal convolutif, ce qui réduit le nombre de canaux augmente dans les męmes dimensions spatiales. Une méthode consiste ŕ utiliser la couche mise en commun (par exemple, 2 x 2, pris chaque moyen de grille / mi-hauteur des dimensions de l'espace). Une autre méthode consiste ŕ utiliser Franchir:

Une opération de convolution de l'étape 2 de
idée Stride est de changer le noyau de convolution étape de déplacement des pixels sauter. Enjambée est un noyau de convolution représente une distance est glissée au-dessus de chaque pixel de l'une, est la glissičre en une étape la plus élémentaire en tant que mode de convolution standard. 2 est représenté par un noyau de convolution de foulée déplacer l'étape 2, pour sauter les pixels adjacents, l'image originale est réduite ŕ 1/2. Enjambée 3 est représenté par le noyau de convolution est une étape de déplacement 3, en sautant deux pixels adjacents, l'image est réduite ŕ 1/3 de l'original
De plus en plus nouvelle structure de réseau, tel que ResNet, a complčtement abandonné la couche de mise en commun. Lorsque la nécessité d'une méthode de réduction de l'image sera utilisée Stride.
Multi-canaux Version
Bien sűr, l'image de la figure comporte un seul canal d'entrée. En fait, la majeure partie de l'image d'entrée est un 3 canaux, le numéro de canal augmentera seulement la profondeur de votre réseau. Le canal sera généralement considéré comme une image entičre, mettant l'accent sur tous ses éléments et ne pas se concentrer sur un côté de leurs différences.

La plupart du temps, nous traitons l'image ŕ trois canaux de RBG (Crédit: André Mouton)

Filtre: un ensemble de noyaux de convolution
Les deux sont essentiellement la différence entre les termes: que dans le cas du canal 1 et le filtre du noyau est équivalent ŕ deux termes, en général, ils sont différents. Chaque filtre est en fait un ensemble de noyau de convolution, chaque couche de canal d'entrée comporte un noyau de convolution, et est unique.
des couches de chaque convolution de sortie du filtre un seul canal, ils sont mis en oeuvre comme suit:
Chaque filtre ŕ noyau de convolution sur un canal d'entrée respectif « coulisse », chaque résultat de calcul est générée. D'autres noyaux que le noyau peut avoir un poids plus important ŕ certains des canaux d'entrée est supérieur ŕ un certain noyau d'accentuation (par exemple, le filtre ŕ noyau de convolution de canal rouge peut avoir un poids plus important que les autres canaux du noyau de convolution, par conséquent, la réaction des caractéristiques de canal rouge mieux que d'autres canaux).

Le résultat de chaque canal de traitement est coule ensuite ensemble pour former un canal. Filtres de noyau de convolution génčrent chacun un canal de sortie respectif, et enfin l'ensemble du filtre produit un canal de sortie totale.

Le dernier terme: parti pris. rôle polariser est d'augmenter ici le terme de polarisation pour chaque sortie de filtre pour produire un canal de sortie finale.

Autre nombre brut de filtres et le filtre unique Chengdu męme: chaque filtre en utilisant un ensemble différent de terme de polarisation de noyau de convolution et le scalaire ayant la procédure ci-dessus pour traiter les données d'entrée, pour générer un canal de sortie final. Ils ont ensuite été réunis ensemble pour produire la sortie totale, dans lequel le nombre de canaux de sortie est le nombre de filtres. Avant que les données de sortie de convolution dans une autre couche, généralement aussi la fonction d'activation non linéaire. Pour terminer l'opération ci-dessus est répétée pour construire un réseau.
2 convolution dimensions: Intuition
Convolution est encore transformation linéaire
Męme avec la couche de convolution de mécanisme, il est encore difficile avec le feed-forward de liaison standard de réseau, mais il n'explique pas pourquoi la convolution sera étendue au domaine du traitement des données d'image, et une bonne performance ŕ cet égard.
Supposons que nous ayons une entrée d'un 4 × 4, nous devons convertir en un tableau 2 × 2. Si l'on utilise le réseau de précompensation, nous allons d'abord convertir l'entrée en une longueur de 4 x 4 pour les vecteurs 16 et 16 possčde une entrée 4 d'entrée et de la couche dense connexion de sortie. Cette couche peut imaginer une matrice de poids W:
En résumé, il y a 64 paramčtres.
En dépit de l'opération de convolution semble d'abord étrange, mais il est encore une transformation linéaire, il y a une matrice de transformation équivalente. Si on entre une taille de 4 × 4 K 3 aprčs transformation nucléaire est appliquée pour obtenir la sortie de la 2 × 2, la matrice de transformation équivalente est:
Il y a neuf paramčtres
(Note: Bien que la transformation de la matrice ci-dessus est équivalente ŕ une matrice, mais l'opération proprement dite est généralement trčs différente comme une multiplication de matrice réalisée )
Circonvolution, dans son ensemble, continue d'ętre une transformation linéaire, mais en męme temps, cela est un autre type de transformation. Une matrice ŕ 64 éléments, seuls neuf paramčtres sont réutilisés. Chaque noeud ne peut voir le nombre de sortie (import nucléaire interne) entrées spécifiques. Aucune interaction avec d'autres entrées, parce que le poids est réglé sur 0.
L'opération de convolution est considérée comme une matrice de poids a priori est trčs utile. Dans cet article, je les paramčtres réseau prédéfinis. Par exemple, lorsque vous utilisez le modčle pré-formé pour faire la classification d'images, ŕ condition que les paramčtres du réseau ŕ l'aide de pré-formation, comme une caractéristique d'une liaison de couche dense extracteur.
Dites En ce sens, il y a deux intuition est pourquoi il est trčs efficace (par rapport ŕ leur remplacement). La migration pour en savoir plus efficace que les commandes d'initialisation aléatoire de grandeur, parce que vous avez seulement besoin d'optimiser les paramčtres de la couche finale de entičrement connecté, ce qui signifie que vous pouvez avoir des performances exceptionnelles, chaque classe quelques images douzaine.
Ici, vous n'avez pas besoin d'optimiser tous les paramčtres 64, parce que nous allons dont la plupart est fixé ŕ 0 (et toujours maintenir cette valeur), la part restante est convertie en paramčtres qui conduisent en fait seulement neuf paramčtres ŕ optimiser. Cette efficacité est importante, lorsque le réel dans 224 × 224 × 3784 l'image de la conversion entrée temps MNIST, il y aura 150.000 entrées. vue de la couche dense de l'entrée divisée par deux ŕ 75000, ce qui nécessite encore paramčtre 10 milliards. En revanche, ResNet-50 un total de seulement 2000 l'argument 5.000.000.
Ainsi, certains des paramčtres fixes ŕ 0, les paramčtres de liaison pour améliorer l'efficacité, mais avec autre étude de la migration, l'étude de la migration, nous savons a priori n'est pas bon, car il dépend d'un grand nombre d'images, comment pouvons-nous savoir ce qui est bon ou mauvais il?
La réponse se trouve dans la combinaison des caractéristiques, en face du paramčtre est un paramčtre ŕ apprendre.
localité
Au début de cet article, nous examinons les questions suivantes:
-
noyau de convolution ŕ partir de seulement une petite région locale de pixels pour former une composition de sortie. En d'autres termes, les caractéristiques de sortie seulement « voir » les caractéristiques d'entrée d'une petite région.
-
le noyau de convolution est appliquée ŕ l'ensemble de l'image, pour générer une matrice de sortie.
Donc, avec l'arričre-propagation est venu tout de noeuds classifiés du réseau, le noyau de convolution a une tâche intéressante d'apprendre des poids de l'entrée locale, les caractéristiques de génération. En outre, étant donné que le noyau de convolution lui-męme est appliquée ŕ l'ensemble de l'image, dans lequel le noyau de convolution doit ętre suffisamment générale pour apprendre, il peut ętre de toute partie de l'image.
Si tel était tout autre type de données, par exemple, l'installation APP de données ventilées, ce qui serait une catastrophe, car le nombre de vos applications installées et les types d'applications sont contiguës, ne signifie pas qu'ils ont quelque chose ŕ voir avec l'application installée date et l'heure que les communes « caractéristiques locales, partagées. » Bien sűr, ils peuvent avoir une des caractéristiques de haut niveau potentiels se trouvent (par exemple. Les gens ont le plus besoin est ce que les applications), mais assez ne nous donne pas des raisons de croire que deux des deux premiers paramčtres et paramčtres complčtement męme. Ces quatre peut ętre une séquence (constante), et est toujours valide!
Cependant, le pixel est toujours dans un ordre cohérent d'apparition, et les pixels influence prčs de l'autre. Par exemple, si un pixel ŕ proximité de tous les pixels sont rouges, alors le pixel est susceptible de rouge aussi. S'il y a un écart, ce qui est une anomalie intéressante, il peut ętre transformé en fonction, tous ces écarts peuvent ętre détectés en comparant avec les pixels environnants.
L'idée est en fait la base pour un grand nombre des premičres vision par ordinateur des méthodes d'extraction de caractéristiques. Par exemple, pour la détection de bord, on peut utiliser le filtre de détection de bord Sobel, qui est un coeur, et une norme de convolution processus de fonctionnement mono-canal ayant comme paramčtres fixes:

convolution de détection de bord vertical
Pour pas de bord de la matrice (par exemple fond de ciel), la plupart des pixels sont de la męme valeur, la sortie du noyau de convolution est égale ŕ zéro ŕ ces points. Pour les matrices de bords verticaux, bords gauche et droit des pixels sont différents, les résultats du noyau de convolution est non nulle, révélant ainsi le bord. Dans la détection d'anomalie zone locale, un noyau de convolution d'agir uniquement sur une matrice 3 × 3, mais lorsqu'il est appliqué ŕ l'image entičre, mais aussi assez pour détecter une caractéristique particuličre de l'image ŕ une position quelconque dans la portée globale ,!
Ainsi, la différence essentielle que nous faisons dans l'étude approfondie de cette question est de se demander: l'énergie nucléaire est utile pour apprendre? Pour les couches initiales de la base de pixels d'origine, on peut raisonnablement attendre détecteur de caractéristiques ayant des caractéristiques de niveau relativement bas, comme des lignes secondaires.
Etude approfondie et la recherche accent est mis sur l'ensemble de la branche du interprétabilité du réseau de neurones. L'un des outils les plus puissants pour cette branche est caractérisée en utilisant une méthode d'optimisation pour visualiser . L'idée de base est simple: ŕ l'image optimize (en utilisant généralement l'initialisation du bruit aléatoire) pour activer le filtre, le rendre aussi fort. Ceci est en effet trčs simple: si le bord est complčtement rempli d'image optimisée, qui est le filtre lui-męme et des preuves solides que trouver d'activation. Avec cela, nous pouvons jeter un regard dans l'étude de filtre, les résultats sont stupéfiants:

De GoogLeNet une troisičme caractéristique du canal convolutif différente couche de visualisation, il est ŕ noter, męme lorsqu'ils détectent différents types de pointe, ils sont encore trčs bas détecteur de bord.

Caractérisé en ce canal 12 ŕ partir de la deuxičme et de la troisičme visualisation de convolution.
Il convient de noter que la chose importante est le résultat d'une convolution de l'image encore d'image. Fond de sortie de la matrice de pixels dans le coin supérieur gauche de la dépouille d'image. Ainsi, vous pouvez exécuter une autre couche de convolution (par exemple, deux ŕ gauche) au-dessus d'une autre pour extraire des caractéristiques plus profondes, que nous pouvons imaginer.
Cependant, peu importe la profondeur de notre détecteur de caractéristiques peut détecter, sans autre modification, ils peuvent encore ne fonctionne que sur une trčs petite image. Peu importe la profondeur de votre détecteur, vous ne pouvez pas ętre détecté ŕ partir du tableau 3 × 3 d'un visage humain. Tel est le concept d'expérience de domaine.
champ réceptif
Tous les choix de conception de base l'architecture CNN est entrée ŕ la fin de la taille du réseau devient de plus en plus petit depuis le début, alors que le nombre de canaux de plus en plus profond. Comme décrit précédemment, cette étape est souvent par des couches complčtes ou piscines. Localité détermine l'entrée de la couche de sortie voir couche précédente. champ récepteur détermine la région d'entrée d'origine vu du point de vue de l'ensemble de sortie de réseau.
Les bandes concept convolution est que nous traitons uniquement avec une distance fixe, tout en ignorant milieu de ceux-ci. D'un autre point de vue, nous ne gardons que la sortie ŕ une distance fixe, et enlever la partie restante de .

3 × 3 convolution, l'étape 2
Nous appliquons ensuite la sortie linéaire, et en fonction de la situation normale, la convolution se superpose une autre nouvelle couche. Ce qui est intéressant. Męme si nous avons la męme taille et la męme région locale nucléaire (3 × 3), une bande appliquée ŕ la sortie de convolution, aura un champ récepteur nucléaire plus:

En effet, les bandes de couche de sortie représente toujours la męme image. Il n'a pas été redimensionnée comme culture, le seul problčme est que la sortie de chaque pixel est une grande région (d'autres pixels ŕ ętre mis au rebut), la position grossičre « typique » ŕ partir de la męme entrée d'origine. Par conséquent, lorsque les noyaux de couche inférieure en cours d'exécution ŕ la sortie, il est effectivement en cours d'exécution sur le pixel recueillies ŕ partir d'une zone plus grande.
(Note: Si vous ętes familier avec l'expansion de convolution, note de convolution ci-dessus n'est pas l'expansion sont deux façons d'augmenter réceptifs convolution d'expansion de champ est une seule couche, ce qui se passe sur une convolution réguličre, rayures suivi. convolution, le cadre intermédiaire est non-linéaire)

Chaque grand visualisant convolution de canal ensemble de blocs, en augmentant progressivement la complexité de l'écran
Ceci permet l'expansion du champ récepteur des caractéristiques de convolution de la couche de niveau bas (côté ligne) et la caractéristique de niveau plus élevé (courbe, texture) combinaison, comme nous l'avons vu dans la couche comme mixed3a.
Suivie par la mise en commun / ŕ travers la couche, le réseau continue de créer un détecteur de niveau supérieur est une caractéristique des composants, (mode). Comme nous l'avons vu dans mixed4a.
Réseau, la taille de l'image répétée diminue, ce qui entraîne la convolution du cinquičme bloc, seule la taille de l'entrée 7 × 7, par rapport ŕ l'entrée 224 × 224. De ce point de vue, chaque pixel représente la matrice de 32 × 32 pixels, ce qui est assez grande.
Par rapport ŕ la couche précédente, une couche de ce qui précčde, l'activation d'un moyen de détection de limite, et ici, une caractéristique de haut niveau est activée sur un 7 × 7, par exemple des oiseaux.
L'ensemble du réseau ŕ partir d'un petit filtre (GoogLeNet 64), seule la détection des caractéristiques de faible niveau, le développement de filtres avec un grand nombre (1024 dans la convolution finale du réseau), chaque filtre est utilisé pour trouver une fonction de haut niveau spécifique . Aprčs couche de mise en commun est, chacun des 7 × 7 du tableau simplifié dans un pixel, chaque canal est un détecteur de caractéristique a une image entičre correspondant au champ réceptif.
Par rapport aux travaux réalisés antérieurement ŕ diffuser le réseau, oů la sortie surprenant. Avant un vecteur standard généré ŕ partir d'un ensemble abstrait de pixels dans l'image aux réseaux de communication, les données nécessite beaucoup de formation est difficile ŕ manipuler.
Circonvolution réseau de neurones, avec les prieurs qui lui sont imposées, en apprenant des détecteurs de caractéristiques ŕ faible niveau de départ, étape par étape l'expansion de son champ réceptif, l'apprentissage de l'intégration progressive de ces caractéristiques ŕ faible niveau et les caractéristiques de haut niveau, abstrait pas chaque pixel combiné, mais puissant concept de hiérarchie visuelle.
La détection d'objets par le premier niveau, et les utiliser pour détecter les caractéristiques de haut niveau, avec le niveau de développement visuel, et, finalement, ętre en mesure de détecter l'ensemble des concepts visuels, tels que des visages humains, les oiseaux, les arbres, etc., ce qui explique pourquoi ils sont si puissants, mais il peut effectivement utiliser des données d'image.
Enfin, une description de l'attaque contre
Avec la construction du réseau de neurones de convolution de hiérarchie visuelle, on peut raisonnablement supposer que leur systčme visuel similaire ŕ l'homme. Ils montrent une grande dans le traitement des images réelles, mais ils ont également échoué ŕ certains égards, cela suggčre fortement que leur systčme visuel humain et ne sont pas tout ŕ fait similaire. Le principal problčme: échantillon de confrontation , ces échantillons a été apporté des modifications spéciales conduit au modčle dupé.

Pour les humains, deux images sont évidemment panda, mais le modčle est pas le cas.
Si les humains peuvent remarquer ces cas conduisent ŕ l'échec du modčle a été falsifié, puis contre l'échantillon est pas un problčme. Le problčme est que ces modčles sont vulnérables ŕ l'échantillon, ces échantillons ont été légčrement modifiés, et apparemment ne tromperai pas tout ętre humain. Cela ouvre une porte, un petit échec comme un modčle pour les véhicules autonomes ŕ partir d'un large éventail d'applications aux soins de santé, il est trčs dangereux.
Robustesse contre les attaques est trčs domaine de recherche, beaucoup de papiers, et męme des problčmes de concurrence et des solutions amélioreront certainement l'architecture CNN pour le rendre plus sűr et plus fiable.
conclusion
Circonvolution réseau de neurones est de permettre aux applications de vision par ordinateur vont de simples ŕ des modčles complexes qui pilotent les produits et services de votre photothčque pour détecter les visages humains pour améliorer le diagnostic médical. Il pourrait ętre la clé pour aller de l'avant méthode de vision par ordinateur, ou une nouvelle percée peut ętre en vue.
Dans tous les cas, une chose est certaine: ils sont tous chose étonnante est au cur d'un grand nombre d'applications innovantes d'aujourd'hui, et le plus en profondeur la compréhension.
références
Un guide ŕ l'arithmétique de convolution pour l'apprentissage en profondeur (https://arxiv.org/abs/1603.07285)
CS231n convolutifs Neural Networks pour la reconnaissance visuelle - Convolutif Réseaux de Neurones (
Visualisation des fonctions - Comment les réseaux de neurones construire leur compréhension des images (de la note: les caractéristiques ont été produites ici visualisations avec la bibliothčque Lucid, une implémentation open source des techniques de cet article de revue) (https://distill.pub/2017/ fonctionnalité de visualisation /)
Attaquer Apprentissage avec les exemples accusatoires (https://blog.openai.com/adversarial-example-research/)
plus de ressources
fast.ai - Leçon 3: Améliorer votre image classificateur (
Conv Nets: une perspective modulaire (
Construire des modčles puissants de classification des images en utilisant trčs peu de données (https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html)

Lei Feng Lei Feng net net