Lei Note du réseau Feng: Cet article paru ŕ l'origine sur le site anglais « visiion informatique pour les nuls », traducteur pierre rouge, traducteur publié ŕ l'origine Blog personnel Lei Feng réseau autorisé.
I. INTRODUCTION
Dans cet article, nous allons discuter de la soi-disant « malédiction de la dimensionnalité », et explique lors de la conception d'un classificateur est pourquoi il est si important. Dans les sections qui suivent, je vais vous expliquer ce concept intuitif, et ŕ travers l'exemple d'une dimension en raison de la catastrophe provoquée par surajustement ŕ expliquer.
Prenons un exemple, nous avons quelques images, chaque image dépeint un chaton ou un chiot. Nous avons essayé de construire un classificateur pour identifier automatiquement l'image est un chat ou un chien. Pour ce faire, nous avons d'abord besoin de considérer les chats de caractéristiques quantitatives et les chiens, donc algorithme de classificateur pour tirer parti de ces caractéristiques pour classer les images. Par exemple, on peut se caractériser par la couleur du chat et de chien identification de la fourrure, qui, différentes images de la mesure rouge, le degré de mesure vert, bleu, la conception d'un classificateur linéaire simple:
Si 0,5 * rouge + 0,3 * vert + bleu 0,2 * > 0,6:
chat retour;
autre:
chien retour;
Rouge, vert, bleu et la couleur que nous appelons caractéristiques Caractéristiques, mais seulement l'utilisation de ces trois caractéristiques, ne peuvent pas obtenir un classificateur parfait. Par conséquent, nous pouvons ajouter plus de fonctionnalités pour décrire l'image. Par exemple, la densité de bord moyenne calcul de gradient d'image ou les directions x et y. Il y a maintenant un total de cinq caractéristiques pour construire notre classificateur.
Pour obtenir de meilleurs résultats de classification, nous pouvons ajouter plus de fonctionnalités, telles que la couleur, la texture et la diffusion des informations statistiques. Peut-ętre que nous pouvons obtenir des centaines de fonctionnalités, mais l'effet deviendra plus classificateurs d'accord? La réponse est un peu frustrant: non! En fait, le nombre de caractéristiques plus d'une certaine valeur, l'effet de classificateur a diminué. La figure 1 montre cette tendance, qui est la « malédiction de la dimensionnalité. »

Figure 1. Avec l'augmentation des dimensions, les performances du classificateur;. Dimension augmentée aprčs une certaine valeur, les baisses de performances de classification
La section suivante explique pourquoi nous produisons cette courbe et de discuter de la façon d'empęcher que cela se produise.
En second lieu, la malédiction de la dimensionnalité et surajustement
Dans le cas des chats et des chiens avant l'introduction, nous supposons qu'il ya un nombre infini d'images de chats et de chiens, cependant, en raison du temps et de traitement des limitations de puissance, nous ne recevons que 10 images (photo d'un chat ou d'un chien dans l'image). Notre but ultime est de construire un classificateur basé sur ces 10 images, vous pouvez corriger pour un nombre illimité d'images en dehors des 10 échantillons correctement classés.
Maintenant, nous allons utiliser simple classificateur linéaire pour essayer d'obtenir un bon classificateur. Si une seule caractéristique, comme le rouge en utilisant le niveau moyen d'image de rouge.

2. caractéristiques individuelles FIG des échantillons de formation classés inefficaces
La figure 2 montre l'utilisation d'une fonction et non seulement obtenir un meilleur résultat de classification. Par conséquent, nous pensons ajouter une seconde fonction: le niveau moyen de vert des images vert.

Figure 3. L'ajout d'une seconde caractéristique linéaire est toujours pas divisé, ŕ savoir l'absence d'une ligne peut ętre complčtement séparé des chats et des chiens.
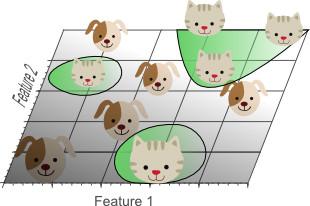
Enfin, nous avons décidé d'ajouter un troisičme élément: le niveau moyen de l'image bleue pour obtenir un espace de représentation en trois dimensions:

Figure 4. Une troisičme caractéristique augmente pour atteindre un linéairement séparables, ŕ savoir, les chats et les chiens il y a un plan complčtement séparé.
Dans l'espace de représentation en trois dimensions, nous pouvons trouver un plan sera complčtement séparé des chats et des chiens. Cela signifie qu'une combinaison linéaire de trois caractéristiques peuvent ętre mieux classés 10 échantillons de formation.

Figure 5. Les autres caractéristiques, le plus de chances d'atteindre la classification correcte
Les exemples ci-dessus semble prouver l'augmentation du nombre de fonctions jusqu'ŕ ce que les meilleurs résultats de la classification, la meilleure méthode pour la construction d'un classificateur. Cependant, avant que la figure 1, nous croyons que n'est pas le cas. Nous devons faire attention ŕ un problčme: Avec l'augmentation des dimensions de fonction, la densité des échantillons dans la formation de l'espace caractéristique est de savoir comment diminuer de façon exponentielle?
1D dans l'espace (fig. 2), 101D échantillons d'apprentissage couvrir complčtement l'espace de caractéristiques, dans lequel la largeur de l'espace de cinq. Ainsi, l'échantillon 1D est une densité ŕ 10/2 = 5. Dans l'espace 2D (Fig. 3), est également un 10 échantillons de formation, il forme la zone de l'espace caractéristique 2D est 5x5 = 25. Ainsi, la densité de l'échantillon 2D ŕ 10/25 = 0,4. Dans lequel le dernier espace dans l'espace 3D, composé de 10 échantillons d'apprentissage est 5x5x5 = 125, par conséquent, la densité d'échantillonnage 3D est 10/125 = 0,08.
Si nous continuons d'ajouter des fonctionnalités, augmenter les caractéristiques générales des dimensions spatiales, et deviennent de plus en plus rares. En raison de la faible densité, nous trouvons qu'il est plus facile d'obtenir une classification hyperplane. En effet, comme le nombre de fonctionnalités deviennent infinies, la possibilité d'échantillons de formation, au mieux, du mauvais côté de l'hyperplan deviendra infiniment petit. Cependant, si nous classons les résultats de la projection de grande dimension ŕ un faible espace tridimensionnel, il y aura un sérieux problčme:
6. Les résultats de fonction figure dans trop surajustement. Classificateur apprentissage des caractéristiques anormales des données d'échantillons excessives (bruit), mais pas une bonne capacité de généralisation de nouvelles données.
La figure 6 montre les résultats de la classification ŕ l'air 3D projection de l'espace de fonction 2D. les données d'échantillon en 3D est linéairement séparable, mais pas en 2D. En fait, l'ajout d'une troisičme dimension pour obtenir les meilleurs résultats de la classification des classificateurs linéaires, non-linéaires équivaut ŕ utiliser un espace de caractéristiques de faible dimension. Par conséquent, le classificateur apprentissage du bruit anormal et les données de formation, ainsi que les données correspondent aux résultats extérieurs de l'échantillon ne sont pas satisfaisants, męme pauvres.
Ce concept est appelé surajustement, il est une conséquence directe des dimensions de la catastrophe. La figure 7 montre une vue en plan d'un classificateur linéaire ŕ deux dimensions classés seulement par deux caractéristiques.
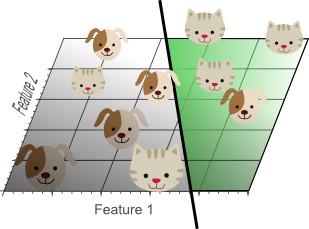
Figure 7. Bien que pas correctement classé tous les échantillons de formation, mais la généralisation du classificateur est meilleur que 5.
Bien que la figure 7 simple classificateur linéaire est inférieure ŕ la figure 5 l'effet de la classification non linéaire, mais la capacité de généralisation du classificateur de. La figure 7. En effet, l'échantillon classification des données ne sont pas un bruit anormal et aussi apprendre. D'autre part, utiliser moins de fonctionnalités, les dimensions de la catastrophe peut ętre évitée, il ne semble pas le phénomčne de surajustement les échantillons de formation.
La figure 8 illustre le contenu des différentes façons ci-dessus. Supposons que nous utilisons un classificateur caractéristique est formé, la plage de valeurs de caractéristique 1D définie entre 0 et 1, et la valeur caractéristique correspondante de chaque chats et les chiens sont uniques. Si nous voulons que l'échantillon de formation de valeur caractéristique ont représenté 20% de la plage de valeurs des caractéristiques, le nombre d'échantillons de formation atteindra 20% de l'échantillon global. Maintenant, si l'augmentation de la deuxičme caractéristique, qui est, de droit ŕ planaires espace de représentation 2D, dans ce cas, si vous voulez couvrir la gamme de valeur caractéristique de 20%, le nombre d'échantillons de formation devrait atteindre 45% de l'échantillon total (0,4500,2 = 0,45). Dans l'espace 3D, si vous voulez couvrir la plage de valeur caractéristique de 20%, il est nécessaire d'atteindre le nombre d'échantillons de formation de 58% de l'échantillon total (0.580.58 * 0,58 = 0,2).

Figure 8. Nombre d'échantillons d'apprentissage couvrant la plage de valeurs caractéristiques ŕ 20% de l'augmentation de la dimension désirée en croissance exponentielle
En d'autres termes, si le nombre d'échantillons de formation disponibles sont fixes, donc si l'augmentation des dimensions de fonction, puis se produit sur-raccord. D'autre part, si l'augmentation des dimensions de fonction afin de couvrir la męme gamme de valeur caractéristique, pour éviter surajustement, le nombre d'échantillons de formation serait nécessaire une croissance exponentielle.
Dans l'exemple ci-dessus, nous montrons les dimensions de la catastrophe provoquera l'amincissement des données de formation. Plus les fonctions utilisées, les données deviendront plus rares, classificateur résultant a classé le pire effet. Dimensions catastrophe se traduira par une répartition inégale de l'espace de recherche sparsity de données. En fait, autour de l'origine des données (dans le centre de l'hypercube) que les données ŕ l'angle de l'espace de recherche est beaucoup plus rare. Ceci peut ętre expliqué par l'exemple suivant:
Imaginons un carré unitaire représente l'espace de caractéristiques 2D, une valeur moyenne de l'espace de caractéristiques dans le centre de la place de l'unité, ŕ tous les points de la distance de l'unité centrale constitue un cercle inscrit carré. Au coin de l'échantillon de formation espace de recherche ne tombe pas dans le cercle unité plus proche du centre, et ces échantillons en raison des valeurs caractéristiques trčs différentes (distribution échantillon dans le coin de la place), tout difficile ŕ classer. Par conséquent, si le cercle inscrit dans la plupart des échantillons tombent dans l'unité, il sera plus facilement classé. Figure 9:

9. échantillons de formation FIG qui se situent en dehors du cercle de l'unité se trouve au coin de l'espace de représentation, l'espace situé dans le centre que le plus difficile de classer les échantillons.
Une question intéressante est quand on ajoute la dimension de l'espace de représentation, avec un carré (hypercube) de changement de volume, circulaire (hypersphčre) est de savoir comment changer le volume? Peu importe comment les changements dans les dimensions, le volume de l'hypercube est 1, le changement de rayon de l'hypersphčre de volume avec des dimensions de 0,5 d est la suivante:

. La figure 10 montre avec la dimension de plus en plus d, le volume de la façon dont les changements hypersphčre:

10. La figure dimension D est grande, le volume de l'hypersphčre ŕ zéro
Cela indique que les dimensions deviennent plus grandes, le volume ultra-sphčre tend vers zéro, alors que le volume de hypercube est constante. Cette découverte surprenante contre-intuitive explique en partie le problčme dans la catastrophe de dimension de classification: dans l'espace de grande dimension, la majeure partie de la distribution des données de formation est définie comme l'espace de représentation, ŕ l'angle de l'hypercube. Comme indiqué précédemment, l'échantillon ŕ l'angle de l'espace de représentation est plus difficile d'échantillons correctement Classifier que la balle sur le corps. 11 sont de l'exemple 2D, 3D et de visualisation 8D hypercube (2 ^ 8 = 256 d'angle) démontre cette conclusion.
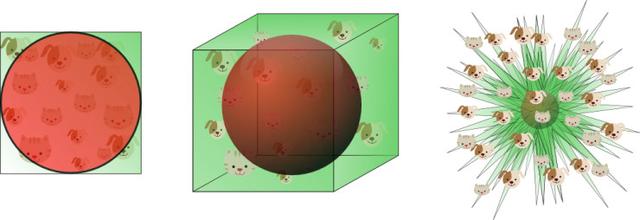
Figure 11. Avec des dimensions de plus en plus, la plupart de la quantité de données distribuées dans les coins
Pour l'hypersphčre 8 dimensions, environ 98% de l'ensemble de données 256 dans ses coins. En conséquence, lorsque la dimension de l'espace caractéristique devient infinie, la différence maximale entre le rapport minimum ŕ celui-ci, ŕ partir du point échantillon de la distance euclidienne minimale au centre de gravité de la distance euclidienne proche de zéro:
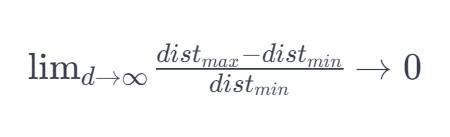
Ainsi, la mesure de distance dans un espace de grande dimension devient progressivement inefficace. Étant donné que le classement de ceux-ci est basée sur la mesure de la distance (par exemple la distance euclidienne, la distance de Mahalanobis, distance de Manhattan), l'espace caractéristique de faible dimension moins plus facilement classé. De męme, dans la distribution gaussienne espace dimensionnelle devient queue plate et plus.
Troisičmement, comment éviter la malédiction de la dimensionnalité
Comme la figure 1 montre les dimensions deviennent trčs grandes, les performances du classificateur diminue. La question est ce qui est moyen « important »? Comment éviter surajustement? Malheureusement, des problčmes de classification, il n'y a pas de rčgle fixe pour indiquer le nombre de caractéristiques ŕ utiliser. En effet, en fonction du nombre d'échantillons de formation, la limite de décision de la complexité et de l'utilisation du classificateur qui.
En théorie, si un nombre infini d'échantillons de formation, les dimensions de la catastrophe ne se produira pas, nous pouvons utiliser un nombre illimité de fonctionnalités pour obtenir un classificateur parfait. Les données moins de formation, les fonctions utilisées seront moins. Si les échantillons de formation N couvrant la gamme de l'espace de fonction 1D, puis en 2D, il est nécessaire de couvrir les męmes données de densité NN, également en 3D, il faut des données NN * N. C'est, que la dimension augmente, le nombre d'échantillons de formation augmente avec les exigences de l'indice.
De plus, les limites classificateur décision non linéaire (tels que les réseaux de neurones, classificateurs KNN, arbres de décision, etc.), mais une bonne capacité de classification des résultats de généralisation est pauvre et sujette ŕ surajustement. Par conséquent, lors de l'utilisation de ces classificateurs, la dimension ne peut pas ętre trop élevé. Si une bonne généralisation classificateurs de capacité (par exemple, classificateur bayésien, classificateur linéaire), plus de fonctionnalités peuvent ętre utilisées, parce que le modčle de classification est pas compliqué. La figure 6 représente la dimension de grande correspond simples de classification ŕ la position du classificateur complexe de l'espace.
Ainsi, surajustement que relativement peu de paramčtres et prévoir un espace de faible dimension dans une prévision ŕ plusieurs paramčtres dans les deux cas se sont produits dans l'espace de grande dimension. Par exemple, la fonction de densité gaussienne a deux paramčtres: la matrice de covariance. Dans l'espace 3D, la matrice de covariance est symétrique matrice 3x3, un total de six valeurs (trois valeurs des principales valeurs diagonales et non diagonaux 3), il y a trois moyenne, ensemble, un total de la revendication 9, l'argument; en 1D, la fonction de densité gaussienne ne nécessite que deux paramčtres (une moyenne, une variance), en fonction de densité gaussienne 2D nécessite cinq paramčtres (moyenne de deux, trois paramčtres de covariance). Nous pouvons voir que les dimensions ont augmenté, le nombre de paramčtres de maničre ŕ plat croître.
Dans l'article précédent nous avons constaté que si le nombre de paramčtres augmente, les paramčtres de la variance augmente (ŕ condition que l'erreur d'estimation et le nombre d'échantillons de formation restent inchangés). Cela signifie que si l'augmentation de la circonférence, l'augmentation de la variance des paramčtres estimés, conduisent ŕ une baisse de la qualité de l'estimation des paramčtres. Classificateur signifie une augmentation de la variance est apparu en forme.
Une autre question intéressante est: quelles sont les caractéristiques devraient ętre sélectionnés. S'il y a N caractéristiques, comment devrions-nous choisir fonction M? Une méthode consiste ŕ trouver le meilleur emplacement dans un graphique de performance. Cependant, étant donné qu'il est difficile de former et de tester toutes les combinaisons de fonctionnalités, donc il y a d'autres façons de trouver le meilleur choix. Ces méthodes sont appelées algorithme de fonction de sélection, les méthodes heuristiques souvent utilisées (par exemple l'algorithme glouton, la méthode la plus premičre ou similaire) pour trouver la combinaison optimale et le nombre de fonctions.
Une autre variante de procédé est caractérisé par la caractéristique suivante N M, une combinaison de caractéristique M ŕ partir de la fonction d'origine. De telles combinaisons linéaires ou non linéaires des caractéristiques d'origine pour réduire le problčme de l'optimisation de l'algorithme de dimensions est appelé extraction de caractéristiques. Une des techniques de réduction de dimensions connues sont analyse en composantes principales (l'APC), qui supprime la dimension hors de propos, la N linéaire combinaisons des caractéristiques originales. PCA essayer d'algorithme pour trouver linéaire basse sous-espace de dimension, pour maintenir la variance maximale des données d'origine. Cependant, les données ne représentent pas nécessairement les données de la variance maximale des informations classifiées les plus importantes.
Enfin, un outil trčs utile et sont testés pour éviter surajustement technique est la validation croisée. La validation croisée des données d'apprentissage d'origine en une pluralité de sous-ensembles d'échantillons de formation. Au cours de la formation classificateur, un sous-ensemble d'échantillons ont été utilisés pour tester la précision d'un classificateur, les autres échantillons utilisés pour l'estimation des paramčtres. Si les résultats sont en contradiction avec les résultats du sous-ensemble de la formation validation croisée des échantillons obtenus, il indique qu'un surajustement. Si l'échantillon de formation est limitée, alors k peut ętre utilisé pour plier ou ŕ gauche de validation croisée.
conclusions
Dans cet article, nous discutons de la sélection des caractéristiques, extraction de caractéristiques, validation croisée de l'importance et d'éviter la malédiction de la dimensionnalité en raison de surajustement. Un exemple simple de surajustement, nous passons en revue la dimension importante de l'impact de la catastrophe.
Lei Feng réseau de lecture connexe:
Vous vous rendez compte classement appris texte tensorflow (sur)
classement appris que vous réalisez texte (sous) avec tensorflow