Li Lin ŕ partir du bas de la non-Temple en retrait
Qubit produit | Numéro public QbitAI
Les humains ont une capacité trčs puissante: supplément de cerveau.

Ce yeux humains photo, un petit morceau de maculage brun le coin inférieur gauche est un vrai cheval - cette position et scčnes, bien sűr, surfe elle!
Mais pour la plupart de l'algorithme, il y a les vues de deux personnes, deux personnes, qui sait ce que le coin inférieur gauche de ce groupe est chose, qui sait ce que les deux d'entre eux dans le sec ~ ~ it ~
Un document CVPR 2018 fraîchement cuits Au-delŕ de Visual itératives Raisonnement Convolutions , Ils essaient de « supplément de cerveau » humain ŕ la capacité de l'algorithme.
Cerveau remplira algorithme
L'étude réalisée par l'Université Carnegie Mellon (CMU) et Google ont co auteurs Facebook chercheur Chen Xinlei (thčse de doctorat a été achevée avant sa remise des diplômes), Li Jia Google et Li Feifei, et Chenxin Lei mentor Abhinav Gupta.
Ils ont étudié la capacité « supplément de cerveau », selon les documents officiels arguments académiques plus rigoureux, il est un espace de raisonnement visuel et sémantique. Avec cette capacité, l'ordinateur sera en mesure d'identifier plus précisément les objets dans une image.

Par exemple, face ŕ un tel scénario, il n'y a pas de place algorithme de raisonnement sémantique ne peut compter que sur la forme du contour du véhicule pour l'identifier est une voiture ou en bus, dans les fenętres ci-dessus, ne reconnaissent que ceux qui ne sont pas obscurci.
Avec le raisonnement spatial, et trois fenętres dans une rangée a été obscurci les objets qui vivent localement, seront considérés comme une fenętre, avec le raisonnement sémantique, Tongshen ci-dessus est également éclairée carton jaune du bus, il sera reconnu comme un autobus scolaire , le raisonnement spatial et sémantique ensemble, l'algorithme peut reconnaître les fenętres de la voiture que l'ombre vague, en fait, est personnel.
look Let ŕ des exemples plus spécifiques de:

Par exemple, sur la carte, « souris » bleu foncé marqué est pas du réseau de neurones ordinaire, et cette nouvelle approche fera le cerveau peut reconnaître dehors. Il est trčs vague dans la figure, la résolution est trčs faible, on peut en déduire en fonction des objets environnants.

La machine ŕ laver selon la fig., Peut ętre déduite de détergent bleu profond rainure marqué.
Aussi une image, le cerveau remplira les algorithmes qui reconnaissent des objets, plus encore que le réseau de neurones moyenne. Autrement dit, il est la capacité de chaque bloc d'objets et mieux identifiés ŕ partir de l'image.
Les auteurs ont utilisé une trčs « hors de la boîte et reconnaissance d'objets » tâche de classification des secteurs du papier, au cerveau font de cet algorithme sous RAN:
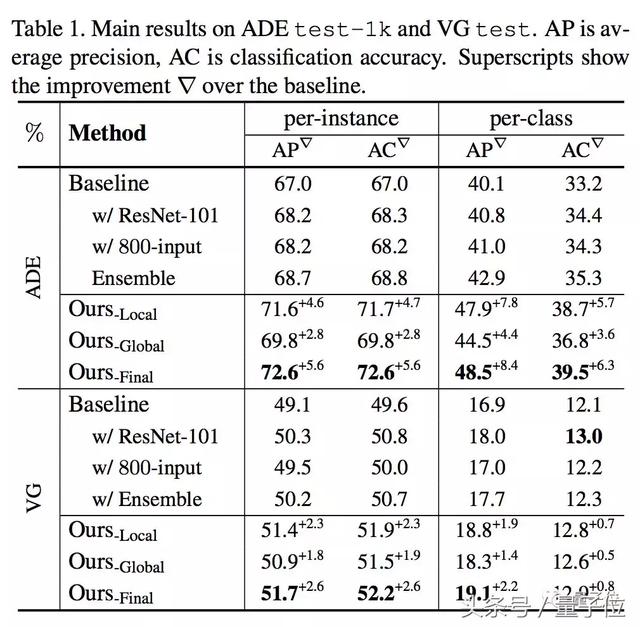
Par rapport au réseau neuronal convolutif classique, les données de modčle définies sur le ADE, chaque groupe moyen pour améliorer la précision de 8,4%, tout en augmentant le réseau ne peut améliorer la profondeur d'environ 1%. Le jeu de données COCO, ce modčle peut améliorer la précision de 3,7%.
Comment faire?
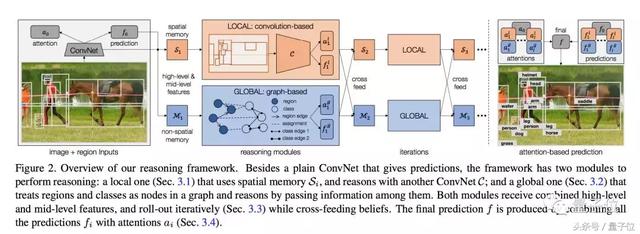
Ils sont convolution ordinaire réseau de neurones, associé ŕ un cadre de raisonnement visuel qui se compose de deux modules de base: un module local, savoir avant d'utiliser la mémoire spatiale pour stocker, l'inférence de réseau de neurones ŕ convolution; une est globale module, sur la base de la figure raisonnement, et la région de cette classe en tant que noeuds dans le graphe, par un raisonnement pour transmettre des informations entre eux.
Dans le détail, le module global a trois composantes, la connaissance de mappage de la catégorie ŕ un noeud, ŕ un noeud dans la zone d'image, la relation spatiale entre la région figures région limite, et une allocation de région pour la classe attribuée FIG.
En fin de compte, tous les modules chacun des mécanismes de prévision et de l'attention itération combinés pour obtenir les résultats des prévisions finales.
Faits saillants Failed
Bien sűr, quand il y a des échecs.

Par exemple, mettre une table de chevet pourrait télécommande il, l'algorithme et la convolution générale réseau de neurones en obtenir moins.
Apprendre Dieu (qui)
Quatre auteurs de ce document dans le secondaire et tertiaire comme vous sont trčs familiers avec les deux déesses Li Jia et Li Feifei vous, secteur maintenant cloud computing de Google. Deux de l'histoire et les réalisations, n'a probablement pas besoin d'un qubit dire ŕ nouveau.
Quatre pour Abhinav Gupta est professeur agrégé de sciences informatiques ŕ l'Université Carnegie Mellon, principalement dans l'étude de la façon de caractériser entre le monde visuel et le langage visuel, le comportement et la façon de contact entre l'objet et d'autres questions.
Un pour Chenxin Lei, est l'un des nombreux étudiants sera probablement adorer de Dieu une école modčle.
Le petit frčre en Février de cette année ŕ l'Université Carnegie Mellon (CMU) a obtenu un doctorat, il est maintenant chercheur Facebook Institut AI. En tant que premier cycle ŕ l'Université du Zhejiang, il a publié plus haut Papers AAAI, CVPR, CIKM attente.
Au cours de l'étude de doctorat, il a travaillé dans Microsoft Research, groupe Google VisCAM et Google Cloud interne de l'équipe AI.
Sa thčse de doctorat d'apprentissage visuel des connaissances, a étudié l'importance des images de fond dans un processus de compréhension de l'image du systčme de vision par ordinateur. Le présent document examine systématiquement la façon explicite l'apprentissage, évolutif automatisé informatique et implicite connaissance visuelle, ainsi que la connaissance de la façon d'utiliser le raisonnement visuel.
Ici, vous pouvez en apprendre systématiquement sur le culte de Dieu: http: //xinleic.xyz/
La chose la plus importante est
adresses Dissertation, bien sűr, essentiel ~ https: //www.arxiv-vanity.com/papers/1803.11189/
Et petit frčre adresse de thčse de doctorat: http: //xinleic.xyz/papers/thesis.pdf
- FIN -
recrutement sincčre
Qubits recrutent éditeur / journaliste, basé ŕ Zhongguancun de Beijing. Nous attendons de talent, des étudiants enthousiastes de nous rejoindre! Détails, s'il vous plaît interface de dialogue qubit numéro public (QbitAI), réponse mot "recrutement".
Qubit QbitAI · manchettes sur la signature de
' « suivre les nouvelles technologies AI dynamiques et de produits