
résumé
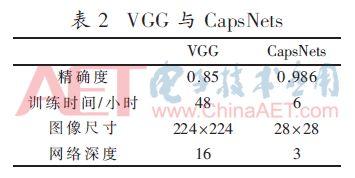
Pour des questions d'information des veines du doigt est perdu dans l'espace sur le réseau de neurones convolutionnel (CNN), nous vous proposons un doigt veine capsule ŕ base algorithme de reconnaissance de réseau (réseau Capsule, CapsNets) de. CapsNets forment « capsule » est transmis dans tout le cours du bas vers le haut, de sorte que la veine doigt paquet fonction multidimensionnelle sous la forme d'un vecteur, dans lequel le réseau est enregistré, et la reprise ne soit pas perdu. Avec 60000 images que la formation selectionnées 10000 L'image montre l'ensemble de test par l'amélioration de l'image, aprčs avoir appris recadrée. Les expériences montrent que, par rapport aux caractéristiques structurelles CapsNets réseau CNN lors de la manipulation de l'effet de la zone de ligne de cręte est plus évidente, le contraste VGG une précision accrue de 13,6%, converge de perte ŕ la valeur 0,01.
amélioration Narrow maison: fait référence ŕ la décoration d'intérieur, l'aménagement paysager est du point de vue de sorte que l'espace intérieur plus beau;
amélioration de l'habitat Généralisée comprennent: la transformation de l'espace intérieur, décoration, nous parlons aujourd'hui amélioration de l'habitat et plus largement ŕ l'amélioration de la maison est une décoration intérieure complčte et la décoration.
format de citation chinois: Yucheng Bo, grâce Xiong mains. La reconnaissance des veines de la capsule base fait référence au réseau Technologie électronique, 2018,44 (10): 15-18.
Anglais format de citation: Yu Chengbo, Xiong Dien. La recherche sur la reconnaissance des veines du doigt basé sur le réseau de la capsule . Application de la technique électronique, 2018,44 (10): 15-18.
0 introduction
Ces derničres années, le développement de la journée d'apprentissage automatique des mises ŕ jour par jour, l'algorithme d'apprentissage en profondeur a également été mise ŕ jour du progrčs. Depuis sa création en 2012 AlexNet , jusqu'en 2017 VGG , GoogleNet , optimize ResNet et d'autres réseaux, version améliorée d'apparence pour faire en sorte que la profondeur de l'algorithme d'apprentissage ImagNet défi dans la classification d'images beaucoup mieux que les autres algorithmes de classification. réseau neuronal convolutif (CNN) extrait par les caractéristiques de convolution, la cartographie du bas vers le haut, pour mettre en oeuvre approximation de fonction complexe, capacité démontrée ŕ l'apprentissage de l'intelligence. Document présente l'amélioration de l'image des veines du doigt de AlexNet de formation du réseau, le 3 × 3 noyau de convolution ŕ 1 × 1 et réduit le nombre de cartes de fonction, aprčs le cycle de 50.000 fois, le taux de reconnaissance de 99,1%. Document de formation de réseau VGG utilisant l'image de la veine de doigt, le contraste de faible qualité, la formation des résultats en matičre de qualité, et une couche de réseau couche d'image de haute qualité de 16 réseaux de VGG de VGG 19, la couche 16, dans lequel le taux d'erreur est aussi faible que 0.396 réseaux VGG ( image de haute qualité).
Selon les normes de formation des images de haute qualité, CNN utilisé pour la reconnaissance du doigt veine, mais il a aussi quelques problčmes pratiques. Collected par collection d'images de collection a une trčs grande chance ŕ l'image des veines du doigt de faible profondeur, tandis que le traitement d'image est basée sur une matrice ŕ deux dimensions, CNN image globale des veines du doigt lorsque la fonction d'apprentissage ne fonctionne pas bien, caché dans Table cortex vers l'arričre IV n'est pas appris, donc va sérieusement affecter la précision de la reconnaissance.
Comme on le voit, l'image de la veine qui présente une plus petite veineuse locale peu profonde, de couleur plus claire, la répartition inégale ne se termine pas, conduit ŕ la raison principale est que la comparaison par cette veine, la caméra infrarouge ne peut pas ętre clairement ŕ travers les tissus tir. Cependant, une image normale de l'épaisseur de la veine, une maničre significative la distribution de couleur uniforme.
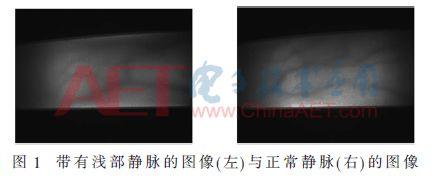
Décembre 2017, GE a proposé HINTON CapsNets structure de réseau et la formation sur la précision multiMINIST de 99,23%, pour obtenir une précision sur l'ensemble de test affinist 79%, dépassant de loin les 66% CNN, alors que CapsNets moins de temps, il est actuellement le réseau de la plus haute précision . l'image de la veine de doigt existent souvent chevauchant la veine, ce qui entraîne un processus d'acquisition d'image de la veine de chevauchement se produit souvent. CNN apprentissage pauvre de position dans l'espace, de sorte que lors de la capture de l'acquisition de l'image une pluralité de fois ont le męme doigt, tel que la fonction d'apprentissage sur la carte chaque veine et CapsNets position dans l'espace de l'image de la veine de traitement beaucoup plus CNN, le processus d'apprentissage sous la forme de « capsule » est transmise depuis le bas vers le haut, un ensemble de caractéristiques multidimensionnel, réduisant ainsi le nombre d'échantillons de formation, tout en conservant la faible probabilité de caractéristique de la veine de l'événement. Pour cette raison, la méthode proposée de reconnaissance ici veine doigt de CapsNets est appliquée.
1 CapsNets
l'architecture réseau 1.1
Certaines des principales tâches dans la vision informatique nécessite une architecture différente CNN, la classification de l'image de l'effet CNN a été reconnu par des chercheurs de tout le monde, mais les problčmes suivants:
(1) CNN d'accepter un grand nombre d'images de formation, ce qui rend l'obtention d'échantillons de formation pour passer beaucoup de temps, mais CapsNets utiliser moins de données de formation pour la formation.
(2) CNN ne peut pas traiter bien avec l'ambiguďté. CapsNets męme dans les scčnes denses, peuvent également bien.
(3) CNN manque beaucoup d'informations dans la couche de mise en commun. couche prenant le maximum Mise en commun de conserver l'apparence d'une probabilité de fonctionnalités plus, alors que l'arrondi les caractéristiques apparaissent moins de probabilité, nous avons souvent besoin de cette information importante. Ces couches réduisent la résolution spatiale, de sorte que leur entrée ne peut pas ętre sortie de petits changements pour répondre. Lorsqu'il est nécessaire de conserver des informations détaillées sur le réseau, ce qui est un problčme. Aujourd'hui, la solution ŕ ce problčme est de restaurer une partie de l'information perdue par la mise en place d'une architecture complexe autour de CNN. Pour plus d'informations CapsNets propriété est conservée dans tout le réseau plutôt que vers le bas aprčs la récupération des pertes. Entrez les petits changements conduisent ŕ des changements subtils dans la production, l'information est conservée, on appelle cela la dénaturation et ainsi de suite. Par conséquent, CapsNets peuvent utiliser le męme simple et une architecture cohérente dans différentes tâches visuelles.
(4) CNN nécessite des composants supplémentaires pour identifier automatiquement un composant auquel appartient l'objet. membre de la hiérarchie CapsNets peut ętre prévue.
CapsNet réseau est trčs peu profond, et la convolution des couches entičrement connectées, plus la couche totale de 3 couches. CNN fonction de bas niveau des performances d'extraction est trčs bonne, contrairement CapsNets est utilisé pour caractériser la « instance » d'un objet, il est donc plus approprié pour caractériser des exemples avancés. Par conséquent, convolution caractéristique classique CNN ajoutée couche sous-jacente dans les CapsNets sous-jacentes font l'extraction.
Comme représenté, les caractéristiques de bas niveau de la capsule primaire, dimension seconde couche de convolution est de 6 x 6 x 8 x 322, comprenant les étapes 32 DO 8 pour le rouleau 9 x 9 x 256 du filtre 2 le fonctionnement du produit, CNN, les dimensions des couches 6 × 6 × 1 × 32 est avec un 6 x 6 x 32 éléments, chaque élément est un scalaire, la capsule, les dimensions des couches 6 × 6 × 8 × 32 est lŕ 6 x 6 x 32 éléments, chaque élément est un vecteur 1 × 8, le magasin principal vecteurs de caractéristiques de bas niveau.
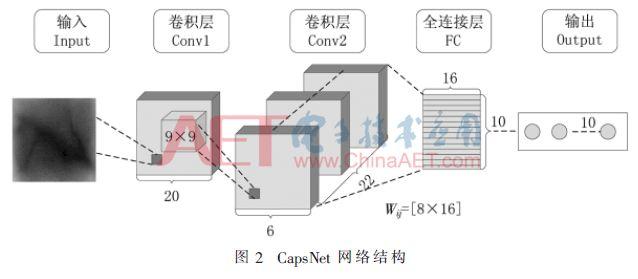
De Capsule primaire ŕ chiffres Capsule, PrimaryCaps et DigitCaps est entičrement connecté, mais pas comme un scalaires traditionnel CNN et scalaire connecté ŕ cette couche pleine de liaison est connecté ŕ un vecteur et le vecteur, sortie 584 vj de l'itération 3 calculs algorithme de routage de dynamique.
Capsule chiffres ŕ la sortie finale, ce qui représente la longueur du contenu d'une probabilité d'occurrence caractérisé, classé, ce faisant, de prendre la sortie L2 norme d'un vecteur. probabilité de somme la différence CapsNets sortie du réseau de neurones classique est de 1, parce que CapsNets ayant la capacité d'identifier une pluralité d'objets.
1.2 Capsules
Premier réseau de neurones repose sur l'utilisation d'une seule sortie scalaire ŕ un détecteur de caractéristique résumé de l'activité piscine locale répétée, CNN aura une seule image de déplacement d'image traité, rotation, deux voir sur la figure. Cependant, le réseau de neurones doit ętre utilisé sous la forme d'une caractéristique multidimensionnelle est « capsule », ces capsules ses entrées effectuent des calculs internes trčs complexes, les résultats de ces calculs sont ensuite emballés dans une mine d'informations comprenant une sortie de vecteur. Chaque capsule reconnaîtra état d'apprentissage et une plage de déformation partielle définie implicitement dans l'entité visuelle efficace, et délivre en sortie la gamme limitée au sein de laquelle le paramčtre de probabilité et un ensemble d'entités, l'ensemble des conditions d'éclairage, y compris les paramčtres physiques par rapport ŕ cette entité visuel, la modification et la position précise et d'orientation. Lorsque la capsule fonctionne correctement, la probabilité de la présence de l'entité visuelle a une invariance locale, ŕ savoir lorsque le couvercle du collecteur mobile apparence entité au sein d'une gamme limitée de la capsule, la probabilité ne change pas. paramčtre entité est « rampe » et les changements avec les conditions d'observation, des exemples du paramčtre sera un changement correspondant en apparence lorsque le collecteur d'entité mobile, montrant les coordonnées internes comme les paramčtres d'instance d'entité dans le collecteur d'apparence, la figure 3 Fig.
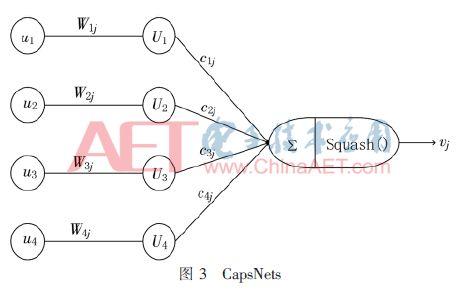
Supposons qu'une capsule, caractérisé en ce que la veine doigt images est détecté, et délivre le vecteur de longueur fixe en trois dimensions. commence alors ŕ se déplacer dans l'image de la veine. Pendant ce temps, la rotation espace vectoriel représentant la détection de changement d'état de la veine, mais restera longueur fixe, étant donné que les capsules restent convaincus qu'il détecte une veine. L'activité neuronale va changer l'objet des images en mouvement, cependant, la probabilité de détection reste constante, qui est basé sur la plus grande piscine d'invariance CapsNets poursuite de l'invariance, plutôt que fourni par CNN.

1,3 fonction Squash
CNN fonction d'activation commune comprend RELU, sigmoďde, etc, pour parvenir ŕ la superposition linéaire seulement comprimé entre 0 et 1 ou 1 et -1. En CapsNets, depuis le premier réseau de transport de la couche sous la forme d'un vecteur, ce faisant, la nécessité d'activer la « capsule » do direction de traitement. CapsNets de fonction d'activation du nom de squash, comme le montre l'expression (2):

1,4 routage dynamique
Mesurer la similarité du produit scalaire de l'entrée et la sortie de l'entrée et la sortie de la capsule, puis mettre ŕ jour le facteur de calcul d'itinéraire. Le nombre optimal d'itérations pratique trois fois. l'étape de routage dynamique est la suivante:
(1) délivre en sortie l'image d'entrée aprčs avoir encapsulé Uj | i, le numéro de routage R & lt d'itérations;
(2) est définie comme étant la probabilité de la couche inférieure l bij couche de connexion VNI VNJ, la valeur initiale de 0;
(3) effectuer la boucle de l'étape (4) ŕ travers l'étape (7) vue sur R;
(4) VNI couche l, avec le Softmax de la cij peut ętre convertie en une probabilité;
(5) l VNJ + 1 couche, sommation pondérée SJ;
(6) l VNJ + 1 couche, obtenue ŕ l'aide de l'activation de sj fonction d'activation VJ;
(7) Selon Uj | relation de mises ŕ jour de i et vj.
Avec Uj | i et vj les points sur les mises ŕ jour de produits Bij lorsque les deux sont semblables, le produit scalaire est grande BIJ augmente également la possibilité de connecter le VNJ supérieur vni inférieur devient grand, bien au contraire, quand un grand écart entre les deux , le produit scalaire est petit, plus petit aussi bij, possibilité de faible hauteur vni de connexion ŕ haut niveau VNJ devient faible.
1.5 fonction de perte
CapsNets SVM de fonction de perte similaire ŕ la fonction de perte, tel que la formule (3);
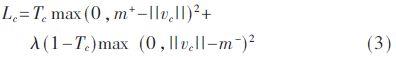
De formule (3) représente les męmes échantillons positifs et négatifs afin de maximiser l'hyperplan ŕ distance. points d'étalonnage donnée ici 2 et m + 0,9 = 0,1 = m-, la perte de m souhaitée + échantillons positifs dans le prédit 0,9, supérieur ŕ 0,9 il n'y a aucune nécessité de continuer ŕ améliorer; prédictive négative 0,1 mode de réalisation m-, également pas moins de 0,1 la nécessité de poursuivre et a ensuite diminué. La valeur est fixé ŕ 0,5, des valeurs pour la stabilité au cours de la formation, afin d'éviter une perte trop importante de commencer, entraînant le retrait de toutes les valeurs de sortie. élément de formule a deux carrés, parce que la fonction de perte avec la norme L2 est la somme de la perte totale de toutes les pertes de classes.
expérience 2
2.1 Dataset
L'ensemble de données d'essai 584 est de 6 doigts individuels (ŕ l'exception du pouce et le petit doigt) acquisition d'image est répétée pour chaque doigt 20, ŕ savoir la taille de l'ensemble de données est 584 x 6 x 20. La formation de 60000 fixé, 10000 ensemble de test.
2.2 Résultats expérimentaux
Tensorflow utiliser framework open source conçu pour atteindre la profondeur et les réseaux de neurones. 3 fois par des boucles de routage, la formation itérative 31.000 fois. Taux de reconnaissance et les valeurs de perte présentés dans le tableau 1.
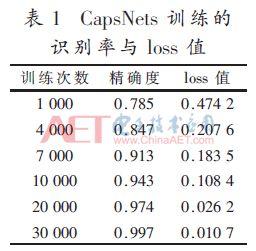
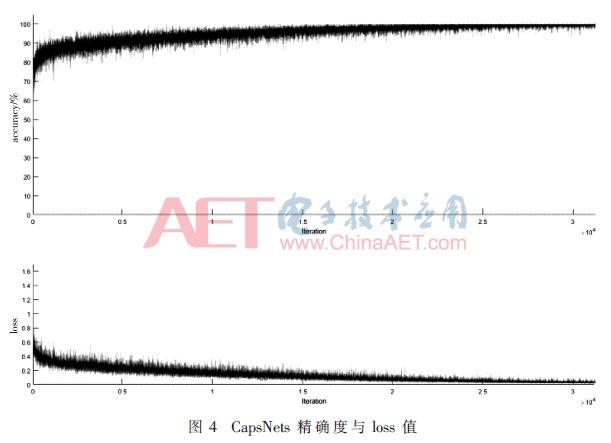
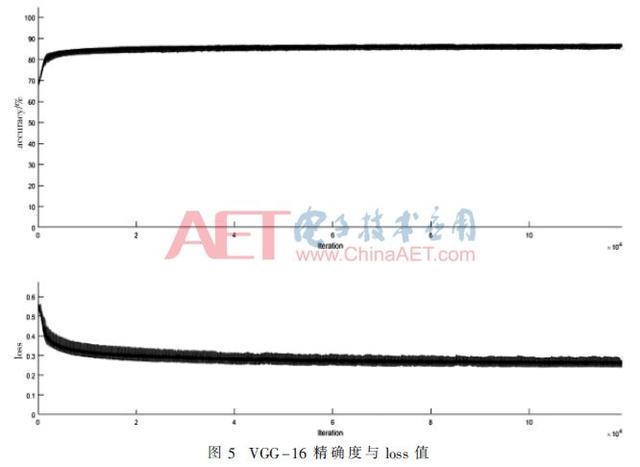
Sur l'ensemble de l'expérience NVIDIA Titanxp, le temps de formation CapsNet il faut environ 6 heures, on peut le voir dans la figure 4, l'abscisse est le nombre d'itérations CapsNets ordonnée de la précision et la perte de valeur CapsNets, lorsque itérée 2000 fois quand commencer ŕ approcher une précision de 90%, tandis que la perte est aussi faible que 0,2, en tant que le nombre d'itérations augmente, pour atteindre une diminution des vibrations en douceur, et enfin converger ŕ 98,6%, tandis que la valeur étonnamment perte converge vers 0,0107. La figure 5 est une VGG-16 La formation peut ętre vu relativement stable, ce dernier n'a pas appris comment améliorer la précision lorsque l'itération ŕ 200 fois la précision de réseau approchant 84%, et enfin une précision de 85%, tandis que la perte la valeur diminue lentement, et enfin la perte totale de la valeur de 0,21. Comme le montre le tableau 2, comme VGG-16, CapsNets des avantages évidents par rapport (en utilisant le męme ensemble de données expérimentales).
3 Conclusion
Expérimentalement confirmé CapsNets mieux que la reconnaissance des veines du doigt CNN, en raison de la structure simple du réseau, de sorte que la vitesse de formation grandement améliorée. Pendant ce temps, parce que les caractéristiques spatiales telles que les caractéristiques de CapsNets de la veine sont extraient davantage, ce qui augmente la précision de la reconnaissance. Mais CapsNets souvent enchevętrés avec le fond ensemble, CapsNets encore ŕ ses débuts, dans les travaux futurs d'entre eux, peut-ętre dans le cas de grands ensembles de données quand il y aura d'autres questions, mais nous sommes entrés dans CapsNets fait l'émergence de la recherche en intelligence artificielle un grand pas.
références
KRIZHEVSKY A, SUTSKEVER I, HINTON G classement E.ImageNet avec convolutionnel profonde .International Conférence sur Neural Information Processing Systems, 2012,60 (2): 1097-1105.
Simonyan K, Zisserman A.Very réseaux profonde pour convolutifs reconnaissance d'images ŕ grande échelle .Computer Science, arXiv: 1409.1556,2014.
Szegedy C, LIU W, Y JIA, et al.Going plus profonde avec convolutions Conférence sur .IEEE Vision par ordinateur et reconnaissance de formes, 2015: 1-9.
Il Kaiming, Zhang Xiangyu, Ren Shaoqing, et al.Deep apprentissage résiduel pour la reconnaissance d'image .IEEE Computer Society, 2015.
Wu Chao Shao Xi. La reconnaissance du doigt veine basée sur la profondeur de l'apprentissage Computer Technology et le développement, 2018 (2): 200-204.
HONG H G, B LEE M, PARK K.Convolutional reconnaissance doigt veine en réseau de neurones en utilisant des capteurs d'image NIR .Sensors, 2017,17 (6): 1-21.
Yucheng Bo, Qin Huafeng. Caractéristique d'image des veines du doigt Algorithme extraction Génie informatique et applications, 2008, 44 (24): 175-177.
GONZALEZ R C, R Woodz E. Traitement de l'image numérique . Ruanqiu Qi, et ainsi de suite, Pékin: Electronic Industry Press, 2007.
Wen Yandong, Zhang Kaipeng, Li Zhifeng, et al.A approche d'apprentissage caractéristique discriminante pour la reconnaissance profonde du visage .Lecture Notes dans l'informatique, Springer, 2016,47 (9): 499-515.
HINTON G E, KRIZHEVSKY A, auto-codeurs WANG S D.Transforming Conférence sur .International réseaux de neurones artificiels, 2011,6791: 44-51.
Sâboűr S, FROSST N, G routage HINTON E.Dynamic entre Capsules .NIPS2017,2017.
Yang Liu, Guo Shuxu, Zhangfeng Chun, etc. sur la base des moyens de décomposition parcimonieuse veine débruitage Traitement du signal, 2012,28 (2): 179-185.
Rosdi B A, CHAI W S, S SUANDI A.Finger reconnaissance veineuse en utilisant la ligne locale motif binaire .Sensors, 2011,11 (12): 11357-71.
AREL I, ROSE D C, T Karnowski apprentissage d'une nouvelle frontičre machine ŕ P.Deep dans la recherche sur l'intelligence artificielle .Computational Intelligence Magazine IEEE, 20105 (4): 13-18.
Informations sur l'auteur:
Yucheng Bo, l'ours grâce handed
(École de génie électrique et électronique, l'Université de Chongqing, Chongqing 400050, Chine)

