Tout a commencé ŕ écrire cet article est trčs embrouillée, parce que la recherche en ligne « ŕ la fin ce qui est arrivé de l'entrée ŕ l'affichage de la page URL », vous pouvez rechercher beaucoup d'informations. Cette question est fondamentale et doit interroger des questions, entrevue Février, bien que ce processus ce qui est arrivé savoir, mais quand l'intervieweur a demandé d'aller étape par étape, beaucoup de détails sont moins claires.
Le but de cet article est de faire un résumé et l'expansion des connaissances ŕ travers ce qui est arrivé aprčs ętre entré dans l'URL. Ainsi, l'article peut ętre trčs compliqué.
L'ensemble du processus est probablement la façon suivante:
1, entrez l'adresse
Lorsque nous avons commencé ŕ entrer l'URL dans le navigateur, le navigateur a effectivement été dans le match intelligent peut avoir ŕ l'URL, il sera de l'histoire, des signets et d'autres endroits, trouver la chaîne qui a été saisie peut correspondre ŕ l'URL, puis donner des conseils intelligents afin que vous puissiez compléter l'adresse url. Pour le navigateur google chrome, il les impressions de pages męme mis du cache directement, qui est, vous ne appuyez sur Entrée, la page est sorti.
2, navigateur Trouver l'adresse IP du nom de domaine
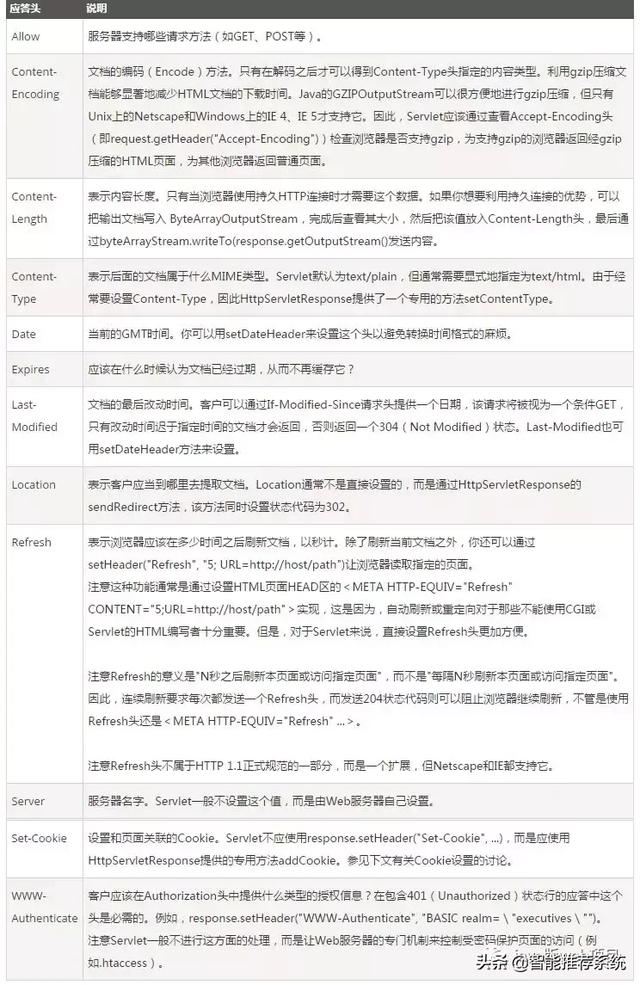
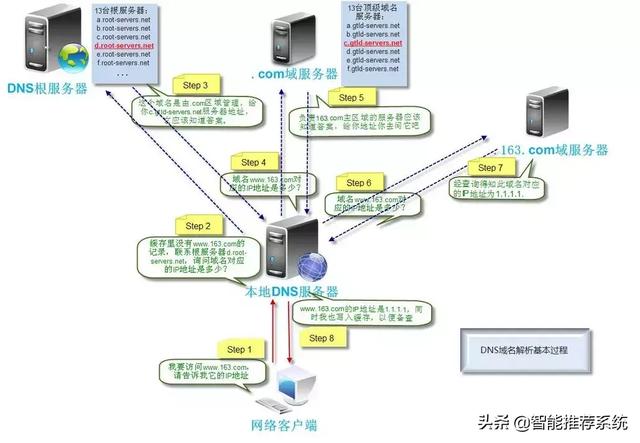
1, une fois initié la demande, le navigateur premičre chose ŕ faire est de résoudre ce nom de domaine, en général, le navigateur vérifie d'abord le disque dur local du fichier hosts pour voir oů il n'y a pas de rčgle et le nom de domaine correspondant, le cas échéant, sur la hôtes fichier directement dans l'adresse IP.
2, il n'y a pas si l'adresse IP correspondante se trouvent dans le fichier hosts local, le navigateur envoie une requęte DNS au serveur DNS local. Le serveur DNS local habituellement votre fournisseur de serveur d'accčs au réseau, tels que China Telecom, China Mobile.
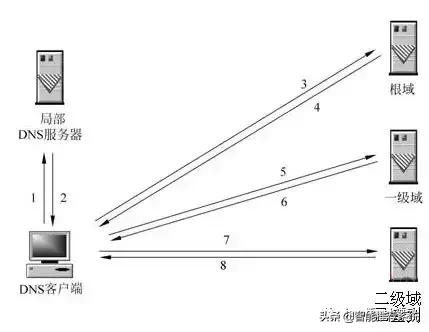
3, l'URL de requęte que vous avez saisi la requęte DNS aprčs avoir atteint un serveur DNS local, le serveur DNS local interroge d'abord son dossier de cache, ce disque s'il y a un cache, vous pouvez retourner les résultats directement, ce processus est une façon de requętes récursives. Sinon, le serveur DNS local doit interroger les serveurs racine DNS.
4, le serveur DNS racine n'enregistre pas la correspondance spécifique entre les noms de domaine et les adresses IP, mais pour indiquer au serveur DNS local, vous pouvez aller ŕ la recherche sur le serveur de domaine et l'adresse du serveur de domaine donné. Ce processus est un processus itératif.
5, le serveur DNS local continue d'envoyer une demande au domaine du serveur, dans ce cas, l'objet est .com serveur de domaine. .com serveur de domaine aprčs avoir reçu la demande, il ne reviendra pas ŕ la correspondance directe entre les noms de domaine et les adresses IP, mais pour indiquer au serveur DNS local, l'adresse du serveur de résolution de votre nom de domaine.
6. Enfin, le serveur DNS local envoie une requęte pour résoudre un serveur de noms de domaine, vous pouvez recevoir une correspondance entre les noms de domaine et les adresses IP, non seulement au serveur DNS local retour d'adresse IP ŕ l'ordinateur de l'utilisateur, mais aussi pour préserver la relation de correspondance cache, afin de préparer la prochaine requęte d'autres utilisateurs, vous pouvez retourner les résultats directement, accélérer l'accčs au réseau.
image parfaite ci-dessous explique ce processus:
l'expansion des connaissances:
1) Qu'est-ce que DNS?
DNS (Domain Name System, DNS), une base de données distribuée comme un autre nom de carte et les adresses IP sur Internet, permettent aux utilisateurs d'accéder plus facilement ŕ Internet, sans avoir ŕ se rappeler le numéro IP de chaînes peuvent ętre lues directement par une machine. Par son nom d'hôte, le nom d'hôte correspondant ŕ l'adresse IP finalement obtenue est appelée un processus de résolution de noms de domaine (ou la résolution de nom d'hôte).
parler populaire, nous sommes plus habitués ŕ se rappeler le nom d'un site, comme www.baidu.com, plutôt que de se souvenir de son adresse IP, tels que: 167.23.10.2. Et rappelez-vous mieux ŕ l'adresse IP de l'ordinateur du site, plutôt que de www.baidu.com et d'autres liens. Parce que, DNS est équivalent ŕ un annuaire téléphonique, par exemple, vous ętes ŕ la recherche www.baidu.com nom de domaine, alors je feuillette mon livre de téléphone, je sais, oh, c'est le téléphone (ip) est 167.23.10.2.
2) requętes DNS de deux façons: une des requętes récursives, et des requętes itératives
1, la résolution récursive
Lorsque le serveur DNS local lui-męme ne peut pas répondre ŕ des requętes DNS client, il a besoin d'interroger d'autres serveurs DNS. Ensuite, il y a deux façons, de maničre récursive, comme indiqué sur la figure. Le serveur DNS local responsable de leurs propres requętes ŕ d'autres serveurs DNS, il est généralement premiers serveurs de domaine racine du nom de domaine requęte, puis requęte un niveau plus bas des serveurs de noms de domaine racine. Les résultats de la requęte résultant au serveur DNS local, puis renvoyés par le serveur DNS local au client.

2, la résolution itérative
Lorsque le serveur DNS local lui-męme ne peut pas répondre ŕ DNS interroge le client, il peut également ętre résolu au moyen d'une requęte itérative, comme le montre. Le serveur DNS local n'est pas leur propre requęte ŕ d'autres serveurs DNS, mais pour ętre en mesure de résoudre d'autres serveurs DNS dans l'adresse IP du nom de domaine au programme client DNS, le programme client avant de poursuivre la requęte DNS au serveur DNS, jusqu'ŕ ce que les résultats de la requęte jusqu'ŕ présent. En d'autres termes, la résolution itérative seulement vous aider ŕ trouver le serveur concerné uniquement, et ne vous aidera pas ŕ mener une enquęte. Par exemple: baidu.com adresse ip du serveur 192.168.4.5 ici, vous allez le vérifier, je suis plus occupé, ne peut vous aider ŕ ętre ici.
3) Nom DNS de domaine organisation spatiale
Nous avons en ce qui concerne les serveurs DNS racine, domaine serveur DNS ŕ l'avant, ce sont l'organisation de l'espace de noms de domaine DNS. Le tableau ci-dessous décrit l'espace de noms cinq catégories en fonction de leurs fonctions utilisées pour décrire le nom de domaine DNS, un nom et un exemple de chaque type de

(Pirates)
4) l'équilibrage de charge DNS
Lorsqu'un site a assez d'utilisateurs lorsque chaque demande si les ressources sont situées au-dessus de la męme machine, la machine peut sauter ŕ tout moment. L'approche est d'utiliser la technologie d'équilibrage de charge DNS, son principe est l'adresse IP du serveur DNS pour configurer plusieurs adresses IP avec un nom d'hôte, réponse ŕ la requęte DNS, serveur DNS interroge DNS pour chaque document enregistré dans l'hôte afin de retourner un rapport d'analyse différents, l'accčs client dirigé vers des machines différentes, de sorte que différents clients d'accéder ŕ des serveurs différents pour atteindre des fins d'équilibrage de charge, par exemple en fonction de la quantité de charge de chaque machine, la machine de l'utilisateur la distance géographique et ainsi de suite.
3, le navigateur envoie une requęte HTTP au serveur Web
Aprčs le nom de domaine pour obtenir l'adresse IP correspondante, le navigateur sera un port aléatoire (1024 < port < 65535) au serveur d'applications Web (couramment utilisés httpd, nginx, etc.) initie une demande de connexion TCP sur le port 80. Aprčs la demande de connexion arrive sur le côté serveur (le milieu par les différents dispositifs de routage, ŕ l'exception du LAN), dans la carte, alors le noyau dans une pile de protocole TCP / IP (pour identifier la solution de paquets de requęte de connexion, une couche de couche de peau), il est également possible de passer par le filtre Netfilter pare-feu (partie du module du noyau), et enfin atteindre le programme WEB, et, finalement, pour établir une connexion TCP / IP.
connexion TCP comme indiqué:
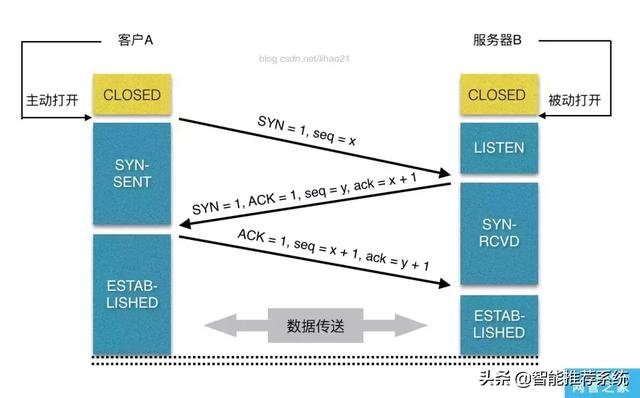
Aprčs avoir établi une connexion TCP, lancer une requęte http. Un en-tęte typique de requęte HTTP ont généralement besoin d'inclure la méthode de requęte, tels que GET ou POST, etc., il n'y a pas PUT commun et SUPPR, HEAD, OPTION et méthode TRACE, le navigateur général ne peut ętre lancé requęte GET ou POST.
Http client initie une requęte au serveur, il y aura un certain nombre de demandes d'information, l'information de demande se compose de trois parties:
| Méthode de requęte protocole / version URI
| En-tęte de la demande (demande en-tęte)
| Demande corps:
Voici un exemple d'une requęte HTTP complčte:
GET / sample.jspHTTP / 1.1Accept: image / gif.image / jpeg, * / * Accept-Language: fr-cn
Connexion: Keep-Alive
Hôte: localhost
User-Agent: Mozila / 4.0 (compatible; MSIE5.01; Fenętre NT5.0)
Accept-Encoding: gzip, dégonfler
nom d'utilisateur et mot de passe = Jinqiao = 1234
Remarque: Aprčs le dernier en-tęte de requęte est une ligne vide, envoi retour chariot et saut de ligne, serveur de notification n'a plus la tęte de la requęte suivante.
(1) une premičre demande de ligne est "méthode proposée URL / Version": GET / sample.jsp HTTP / 1.1
(2) en-tęte de la demande (demande en-tęte)
tęte de demande contient un certain nombre d'environnements clients connexes et corps de la demande d'informations utiles. Par exemple, l'en-tęte de requęte peut déclarer la langue utilisée par le navigateur, la longueur du corps de la demande, et autres.
Accepter: image / gif.image / jpeg * / *.
Accept-Language: zh-CN
Connexion: Keep-Alive
Hôte: localhost
User-Agent: Mozila / 4.0 (compatible: MSIE5.01: Windows NT5.0)
Accept-Encoding: gzip, dégonfler.
(3) corps de la demande
tęte de demande et la demande est une ligne vide entre le texte, cette ligne est importante car elle indique que l'en-tęte de demande est terminée, la prochaine est le corps de la demande. Le corps de la requęte peut contenir des soumissions des clients de la requęte:
nom d'utilisateur et mot de passe = Jinqiao = 1234
4, la réponse du serveur de redirection permanente
Serveur au navigateur en réponse ŕ une 301 réponse de redirection permanente, de sorte que le navigateur accčde au « » plutôt que « ».
Pourquoi doit rediriger serveur au lieu d'envoyer directement les utilisateurs de contenu Web veulent le voir? L'une des raisons en rapport avec le classement des moteurs de recherche. Si une page a deux adresses, comme et les moteurs de recherche penseront qu'ils sont deux sites, ce qui entraîne une réduction de chaque liens de recherche sont de réduire classement. Les 301 moteurs de recherche de redirection permanente savent ce que cela signifie, de sorte que la visite abordera le www et non www aller dans le męme classement. Il y a une adresse différente provoquera une mauvaise cache conviviale lorsqu'une page a plusieurs noms, il peut apparaître plusieurs fois dans le cache.
Accroître les connaissances
1) la différence entre 301 et 302.
301 et 302 codes d'état indiquent la redirection, ce navigateur ŕ obtenir ce code d'état renvoyé par le serveur passera automatiquement ŕ une nouvelle adresse URL, l'adresse peut ętre obtenue (de l'utilisateur de voir la réponse en-tęte Emplacement l'effet qu'il a tapé dans l'adresse un moment dans une autre adresse B) - c'est un dénominateur commun.
Leur différence est. A 301 représente l'ancienne ressource d'adresse a été définitivement supprimée (cette ressource ne peut pas ętre visité), URL aprčs les moteurs de recherche rampent en męme temps le nouveau contenu échangera également l'ancienne URL de redirection ;
Une ressource 302 représente l'ancienne adresse encore (encore accčs), ce n'est une redirection temporaire de l'ancienne adresse de sauter A ŕ l'adresse B, Les moteurs de recherche vont parcourir le nouveau contenu et enregistrer l'ancienne URL. SEO302 mieux que 301
2) raisons Redirect:
(1) l'ajustement du site (comme le changement de la structure de répertoire de page);
(2) est déplacé vers une nouvelle page d'adressage;
(3) changer l'extension de la page (par exemple besoin d'application pour changer .html ou .php .shtml).
Dans ce cas, sinon, redirect les favoris de l'utilisateur ou la recherche des bases de données du moteur ne permettent l'accčs ŕ l'ancien client d'adresse reçoit une page d'erreur 404, la perte de trafic en vain aussi un multiple site de domaine enregistré aussi besoin de rediriger les utilisateurs d'accéder ŕ ces noms de domaine sauter automatiquement vers le site principal et ainsi de suite.
3) quand le sauter 301 ou 302?
Lorsqu'un site ou une page 24-48 heures temporairement déplacés vers un nouvel emplacement, cette fois-ci devrait ętre 302 sauts, 301 sauts et l'utilisation du site est la scčne avant d'un besoin de raison d'ętre enlevé au large, puis aller ŕ le nouvel accčs d'adresse est permanente.
termes clairs: l'utilisation de scénarios sur les 301 sauts comme suit:
1, ne veulent pas renouveler le nom de domaine expiré (ou trouver un nom de domaine d'un site plus approprié), veulent changer le nom de domaine.
2, apparaît dans les résultats de la recherche du nom de domaine d'un moteur de recherche sans le www et le www nom de domaine et n'a pas inclus cette fois, vous pouvez utiliser une redirection 301 indique le moteur de recherche le nom de domaine qui est notre objectif.
3, l'espace d'instabilité du serveur, le temps pour l'espace.
5, le navigateur suit l'adresse de redirection
Maintenant, le navigateur connaît l'adresse correcte « » est accessible, il envoie une autre requęte http. Il n'y a pas quoi dire
6, le traitement de la demande au serveur
Aprčs de nombreuses étape précédente, nous allons enfin envoyer http demandes ŕ notre serveur ici, en fait, est déjŕ arrivée en face du serveur de redirection, le serveur est de savoir comment faire face ŕ notre demande?
De l'extrémité arričre de l'orifice fixe reçoit un début de paquet TCP, il faudrait traiter la connexion TCP, analyse le protocole HTTP, et en outre emballé comme HTTP objet d'appel selon le format de paquet, utilisé pour la partie supérieure.
Certains grands sites garderont votre demande au serveur proxy inverse, parce que lorsque le site a été visité par un trčs gros site plus lentement, un serveur ne suffit pas. Ainsi, la męme application déployée sur plusieurs serveurs, la demande de l'utilisateur d'attribuer un grand nombre de plusieurs machines de manutention. Dans ce cas, le client n'est pas directement accessible via le protocole HTTP d'un serveur d'applications Web, mais la premičre demande de Nginx, Nginx, puis demander un serveur d'application, puis renvoie les résultats au client, voici le rôle de Nginx inverse serveur proxy. Il apporte également un avantage, dans le cas oů l'un des serveurs accroché, aussi longtemps que il y a un autre serveur et en cours d'exécution, il ne sera pas affecter les utilisateurs.
Comme le montre:
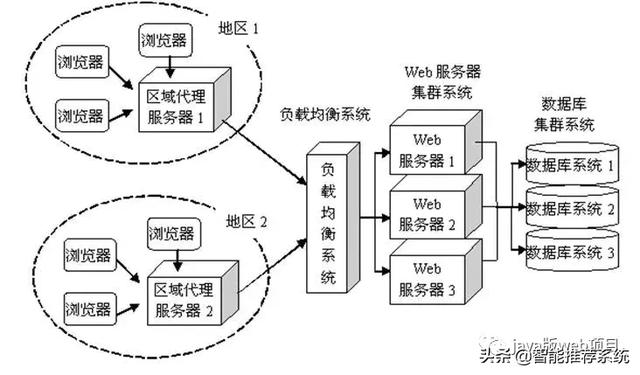
Par proxy inverse Nginx, nous sommes arrivés au serveur web, beaucoup de script côté serveur ŕ notre demande, l'accčs ŕ notre base de données, le besoin d'avoir accčs au contenu, etc., bien sűr, ce processus implique beaucoup de script d'opérations complexes. Parce que celui-ci ne connaissent pas, si celui-ci ne peut ętre introduit tant.
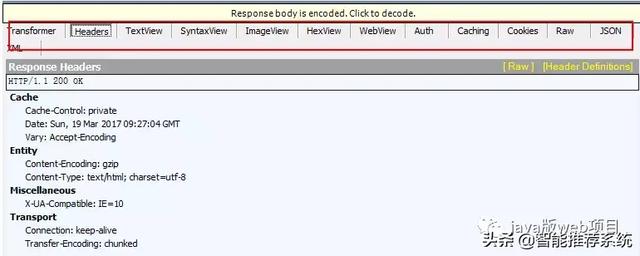
7, le serveur retourne une réponse HTTP
Aprčs les six étapes précédentes, le serveur reçoit une demande, nous traitons également notre demande, ŕ ce point, il renvoie les résultats de son traitement, qui est une réponse de HTPP de retour.
HTTP demande et la réponse HTTP est similaire, mais aussi la réponse HTTP se compose de trois parties, ŕ savoir:
ligne d'état l
tęte de réponse de l (tęte de réponse)
corps de la réponse de l
HTTP / 1.1200 OK
Date: 31 décembre 200523:59:59 GMT
Content-Type: text / html; charset = ISO-8859-1
Content-Length: 122