Avec la popularité de l'architecture micro-services, divisions de services sur différentes dimensions, une demande ont souvent besoin d'impliquer plusieurs services. applications Internet construites sur un autre ensemble de modules logiciels, des modules logiciels, il peut ętre mis au point par des équipes différentes, peuvent ętre mises en uvre en utilisant différents langages de programmation, il est possible tissu en milliers de serveurs ŕ travers plusieurs données différentes centre. Nous avons donc besoin d'une aide ŕ comprendre le comportement du systčme, des outils d'analyse des problčmes de performance, de sorte que le cas d'échec de localiser rapidement et de résoudre les problčmes.

composante de surveillance de lien complet se pose dans ce contexte du problčme. Le plus célčbre est des documents publics Google Dapper Google mentionnés. Vous voulez comprendre le comportement des systčmes distribués dans ce contexte, il est nécessaire de surveiller les applications ŕ travers différentes actions associées entre différents serveurs.
Par conséquent, l'architecture micro-services dans les systčmes complexes, presque toutes les demandes de fin avant sont distribués pour former un lien d'appel de service complexe. Vous pouvez demander une chaîne d'appel complet comme indiqué ci-dessous:

Ainsi, dans l'échelle de l'entreprise augmente, et le nombre croissant de services et de fréquents changements de circonstances, face ŕ un lien d'appel complexe apportera une série de questions:
- Comment trouver rapidement le problčme?
- Comment déterminer la portée de l'échec?
- Comment trier le service et le caractčre raisonnable de la confiance dépend?
- Comment analyser le lien en temps réel les problčmes de performance et de la planification des capacités?
En męme temps, nous sommes préoccupés par les indicateurs de performance au cours du traitement des demandes de chaque appel, comme: Throughput (TPS), le temps de réponse et la journalisation des erreurs.
- Certains topologie calculée composant correspondant, la plate-forme, le dispositif physique en fonction du débit en temps réel.
- Temps de réponse, temps de réponse, y compris le temps de réponse global de chaque appel et de service et ainsi de suite.
- enregistrement d'Erreurs, le rendement par unité de temps en fonction des temps d'exception de services statistiques.
performance lien complet affichage surveillance de la dimension ŕ la dimension locale des indicateurs sera appliquée sur toutes les informations la performance chaîne d'appel expression concentrée, peut facilement mesurer la performance globale et locale, et facile ŕ trouver la source du défaut produit, peut production considérablement raccourcir le temps de dépannage.
Avec l'outil de suivi complet de lien, nous avons pu réaliser:
- Demande de suivi des liens, la localisation rapide des défauts: Vous pouvez localiser rapidement les informations du journal d'erreur en appelant la chaîne de regroupement d'entreprises.
- Visualisation: les différentes étapes du temps et de l'analyse des performances.
- Optimisation dépendante: la disponibilité des différents aspects de l'appel, le cardage et l'optimisation des dépendances de service.
- L'analyse des données, optimiser le lien: l'utilisateur peut obtenir le chemin de comportement, analyse groupée utilisés dans de nombreux scénarios d'entreprise.
Comme mentionné ci-dessus, nous sélectionnons la composante surveillance lien complet qui cible l'exigent? Google Dapper a également mentionné, sont résumés comme suit:
1. Sonde de consommation de performance
APM affectent les composants du service devraient faire assez peu. appel de service Buried lui-męme apportera une perte de performance, qui ont besoin d'appeler le traçage ŕ faible perte, mais aussi par la configuration réelle du mode de fréquence d'échantillonnage, sélectionnez la partie de la demande d'analyser le chemin de la requęte. Dans un service hautement optimisé, męme un peu de perte sera trčs facile ŕ détecter, et peut forcer l'équipe de déploiement du systčme de suivi des services en ligne a dű fermer.
2. Code invasif
Qui est aussi un volet commercial, il devrait ętre peu ou pas d'intrusion d'intrusion que d'autres systčmes d'entreprise pour la transparence des consommateurs, réduire le fardeau des développeurs.
Pour les programmeurs ne demande pas besoin de savoir qu'il ya une telle chose comme un systčme de suivi. Si vous voulez un systčme de suivi prenne effet, il est nécessaire de compter sur les développeurs d'applications prendre l'initiative de coopérer, le systčme de suivi est trop fragile, souvent en raison du systčme de suivi de négligence ou d'un bogue utilisé dans les implants causent les problčmes de code d'application, ce n'est pas ce systčme de suivi pour répondre ŕ la demande de « déploiement omniprésent ».
3. Evolutivité
Un systčme de suivi bon appel doit prendre en charge le déploiement distribué, une bonne évolutivité. Plus le meilleur cours aux composants de soutien. Ou fournir plug-in API de développement pratique, pour certains il n'y a pas de suivi des composants, les développeurs d'applications peuvent également développer leurs propres moyens.
4. Analyse des données
Analyser les données plus rapide, analyse dimensionnelle, autant que possible. Systčme de suivi peut fournir des informations de retour assez rapide, vous pouvez faire une réponse rapide ŕ une situation anormale dans un environnement de production. Une analyse complčte, afin d'éviter le développement secondaire.
plein systčme général de contrôle des liens, peut ętre divisé en quatre blocs fonctionnels:
Et générer journal 1. Buried
Enterré dans le cadre du systčme d'information qui est le nud actuel, il peut ętre divisé en points enterré client, enterré points d'extrémité de service, ainsi que le point bi-enterré client et le serveur. Buried journal de temps de démarrage contient généralement le traceId suivant, spanId, appel, type de protocole, ip de l'appelant et le port, les demandes de nom de service, appelez le temps, le résultat de l'appel, des informations d'exception, etc., et peut ętre réservé pour le champ étendu pour l'étape suivante pour se préparer ŕ l'expansion;
- Non Cause frais généraux de performance: une valeur n'a pas été vérifiée, mais elle aura une incidence sur la performance des choses, il est difficile de promouvoir l'entreprise!
- Parce que le journal d'écriture, d'affaires QPS plus, l'impact des performances plus sévčres. Résolus par échantillonnage et le journal asynchrone.
2. collecte et enregistre les journaux
Le support principal distribué programme de collecte de journal, tout en augmentant MQ comme une mémoire tampon;
- Il y a un deamon journal pour faire de recueillir sur chaque machine, entreprise traite sa propre trace envoyé au démon, démon d'envoyer une collection Trace;
- collecteur multicellulaires pub similaire / sous architecture, équilibrage de charge;
- L'analyse en temps réel des données agrégées et le stockage hors ligne;
- analyse hors-ligne doit ętre agrégées ensemble pour connecter une chaîne d'appel du męme;
3. Analyse statistique et lien appel de données, et l'actualité
Suivi analyse de la chaîne d'appel: le męme TraceID de Span, triées par temps est la ligne de temps. ParentID consiste ŕ enchaîner la pile d'appel.
Jeter une exception ou un délai d'attente, impression TraceID dans le journal. requęte TraceID en utilisant la chaîne d'appel, le problčme de positionnement.
mesure dépendante:
- La forte dépendance: un appel direct n'a pas réussi ŕ interrompre le flux principal
- dépendant fortement: un lien pour appeler une forte probabilité d'une personne ŕ charge
- Souvent, il repose sur: un lien avec un appel ŕ compter le plus souvent
Analyse hors ligne: résumé de TraceID, par Span ID et appel ParentID restaurer les relations, sous forme d'analyse des liens.
Analyse en temps réel: analyse directe d'un journal unique, pas un résumé, la restructuration. Obtenez le QPS actuel, retard.
4. spectacle et aide ŕ la décision
3.1 Span
L'unité de base de travail, un appel de liaison (qui peut ętre pas RPC, DB restriction particuličre comme) pour créer une période, il est identifié par un ID 64 bits, uuid plus pratique, il existe d'autres données de portée telles que les informations de description, l'horodatage , l'information d'étiquette (Annotation) de paires de valeurs de clé, l'parent_id analogue, dans lequel la durée peut représenter un identifiant de source de liaison parent d'appel.

La figure illustre la portée est en quelque sorte dans un grand processus de suivi. Les noms de portée enregistré dapper, et chaque ID de portée et l'ID de parent, de reconstruire la relation entre la durée différente au cours d'une piste. Si la durée est pas un ID parent est appelé durée de racine. Tous durée sont accrochés sur une piste particuličre, partager aussi un identifiant de suivi.
Structure de données Span :
Span de type struct { TraceID int64 // utilisé pour identifier un identifiant de demande complčte chaîne nom ID int64 // L'appel en cours span_id ParentID // int64 appel haut span_id du service parent_id de service supérieur est nul Annotation Annotation // pour le timbre marquage bool débogage }3,2 Trace
SIMILAR Span ensemble structure d'arbre Représentant une piste complčte, commence par une requęte au serveur, le serveur renvoie une fin de la réponse, du temps piste appel rpc ŕ chaque fois il y a un trace_id d'identification unique. Par exemple: un grand stockage de données distribuées, vous exécutez une trace sur votre premičre demande de la composition.

Chaque note de couleur une durée marquée, un lien est identifié de maničre unique par TraceId informations de requęte identifiant Span initiée. Le noeud de l'arbre est l'unité de base de la structure entičre, et chaque noeud est ŕ son tour une référence ŕ la durée . durée représente la connexion entre le noeud et sa durée parent une relation directe. Alors que la durée dans le fichier journal représente tout simplement le début et la durée de l'heure de fin, leur structure d'arbre entier est relativement indépendante.
3.3 Annotation
Annotation, la demande d'enregistrement d'une information liée ŕ la manifestation particuličre (par exemple le temps), il y aura une pluralité de durée d'annotation décrit annotations . composent habituellement de quatre notes des informations:
(1) cs : Démarrer client, représente client envoie une demande (2) sr : Recevoir le serveur, représente le serveur reçoit la demande (3) ss : Serveur Envoyer, représente le serveur de traitement de finition, et envoie les résultats au client (4) cr : Reçu client, représenter le client au serveur pour obtenir des informations de retourstructure de données d'annotation :
Type struct {Annotation timestamp int64 valeur chaîne Point final hôte durée int32 }3.4 Exemple d'appels
1. La demande d'appel exemplaire
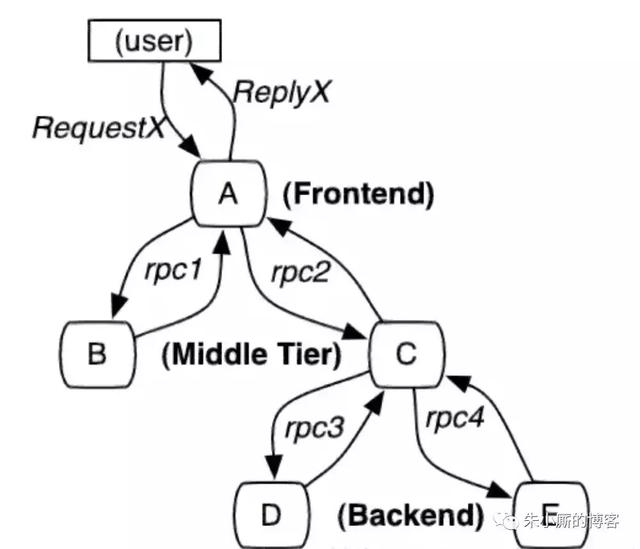
2. Processus de suivi des appels
Appelez le suivi de l'ensemble du processus:
- Demande arrive générer une TraceID globale, ŕ travers toute la série de TraceID peut appeler la chaîne, un TraceID au nom d'une demande.
- En plus de TraceID, mais aussi vous devez les relations entre parents et enfants des appels record. Chaque service enregistre id parent et span id, ils peuvent organiser les relations parent-enfant par une chaîne complčte d'appel.
- Sans un ID parent de la durée pour devenir durée de la racine, on peut voir que l'entrée de la chaîne d'appel.
- Tous ces éléments sont disponibles ID unique au monde entier de 64 bits;
- Le processus d'appel entier chaque demande doit passer par TraceID et SpanID.
- Les temps pour chaque demande de service et d'accompagnement TraceID accompagnant SpanID comme record id parent, et l'SpanID auto-généré également enregistré.
- Pour afficher un temps d'appel complet pour détecter des appels tant que dossiers selon TraceID, l'appel entier de la relation parent-enfant par ID parent et organisation span id.


5. Agent de déploiement non invasive
AGENT MANDATAIRE par le déploiement non-invasive, la mesure du rendement et la séparation complčte de la logique de service, toute méthode permet de mesurer le temps d'exécution de toute classe, de cette façon augmente considérablement l'efficacité de la collecte et de réduire les coűts opérationnels. Selon la durée de service divisé en deux catégories AGENT :
La plupart de suivi complet-Link modčles théoriques sur le marché sont Google Dapper tirage sur papier, ce document se concentre sur les trois éléments suivants APM:
- Zipkin: par Twitter Open Company Source, distribué systčme de suivi open source pour les services de collecte réguličre de données, afin de résoudre le problčme de retard microarchitecture-service, y compris: la collecte de données, le stockage, la recherche et du spectacle.
- Pinpoint: outil d'APM pour une grande échelle des systčmes distribués en Java, open source distribué par le composant de suivi coréen.
- Skywalking: APM composants internes en cours, il est suivi, systčmes d'alerte et d'analyse pour clusters application distribuée opération commerciale JAVA.
Ceux-ci doivent comparer les éléments extraits trois programmes de surveillance tout lien:
4,1 sonde de performance
Plus préoccupé par la performance de la sonde, aprčs tout, le positionnement de l'outil APM ou, si un lien est établi pour permettre le suivi, un résultat direct du débit inférieur ŕ la moitié, ce qui est inacceptable. Pour skywalking, Zipkin, la pression ponctuelle a été mesurée, et comparée ŕ la situation de référence (sonde non utilisée).
A choisi un commun des applications ŕ base de printemps, il comprend Spring Boot, Spring MVC, Redis client, mysql. Contrôle de l'application, chacun de la trace, la sonde 5 extractions portée (1 Tomcat, 1 SpringMVC, 2 Jedis, 1 Mysql). Voici les applications de base et de test skywalkingtest presque.
Trois simulé utilisateurs simultanés: 500,750,1000. Jmeter test d'usage, chaque fil 30 transmet des demandes de régler les 10ms de temps de réflexion. Une fréquence d'échantillonnage utilisée, ŕ savoir 100%, et le côté de production peuvent ętre différents. localiser avec précision la fréquence d'échantillonnage par défaut de 20, ŕ savoir 50%, en réglant le profil de l'agent ŕ 100%. Zipkin défaut est 1. Ensemble, un total de 12 espčces. Le regard de tableau récapitulatif ci-dessous:
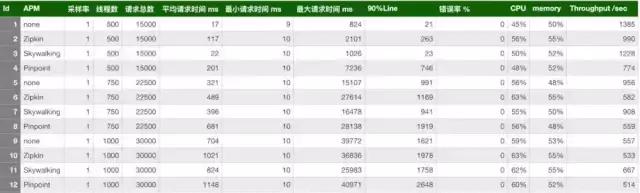
Comme on peut le voir dans le tableau, les trois modules de surveillance liaison, avec un impact minimal sur le débit sonde skywalking, centrée débit Zipkin. l'impact sur le débit Pinpoint sonde plus évidente ŕ 500 utilisateurs simultanés, le débit est réduit de services de dépistage 1385-774, un grand impact. Et puis regardez sous l'influence de la CPU et de la mémoire, des mesures de pression effectuées dans la mémoire du serveur et de l'impact du processeur sont similaires ŕ 10%.
Extensibilité de 4,2 collecteur
évolutivité de collecteur, ce qui permet ŕ l'échelle horizontalement pour soutenir les clusters de serveurs ŕ grande échelle.

4.3 Analyse complčte de liaison de données d'appel
Une analyse complčte de la liaison de données d'appel, en offrant une visibilité du niveau de code afin de localiser facilement le point de défaillance et les goulets d'étranglement.



4.4 pour le développement d'un transparent, facile ŕ changer
Pour le développement de la transparence, facile de changer, ajouter de nouvelles fonctionnalités sans avoir ŕ modifier le code, facilement activé ou désactivé. Nous attendons la fonction avant ne peut pas modifier le code du travail et que vous voulez obtenir la visibilité du niveau de code.
Pour cela, Zipkin utiliser la bibliothčque modifiée et sa propre fonction conteneur (Finagle) pour fournir le suivi des transactions distribuées. Cependant, il nécessite des modifications de code nécessaires. skywalking et sont basées sur l'amélioration bytecode Pinpoint maničre, les développeurs ne ont pas besoin de modifier le code, et peut recueillir des messages de données plus précises, car il y a plus de codes d'octets.
4.5 topologie de la chaîne d'appel complčte d'application
Détection automatique de la topologie de l'application, pour vous aider ŕ déterminer l'architecture de l'application.


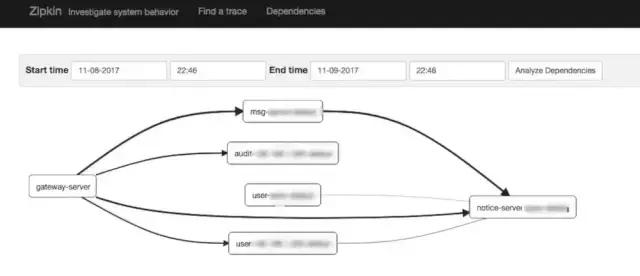
Les trois photos ci-dessus ont été exposées leurs composants APM de la topologie d'appel, peut atteindre une topologie de chaîne d'appel d'application complčte. Relativement parlant, les écrans d'interface Pinpoint plus riche, spécifique ŕ l'appel du nom DB, topologie Zipkin un service limité entre le service.
4.6 Pinpoint comparer et affiner Zipkin
4.6.1 Pinpoint les différences Zipkin
4.6.2 similitude avec Pinpoint Zipkin
Pinpoint et Zipkin que le papier reposent sur Google Dapper, donc les fondements théoriques de la męme. Les deux sont divisés en plusieurs appels de service Span relation en cascade, la relation entre les appels en cascade dans SpanId et ParentSpanId, puis toutes derničre chaîne d'appel Span passe par une convergence de trace, rapporté au service mettre fin ŕ collecteur pour la collecte et le stockage.
Męme ŕ ce stade, le concept adopté par Pinpoint pas tout ŕ fait conforme ŕ ce document. Par exemple, il utilise TransactionId pour remplacer TraceId, alors que le vrai TraceId est une structure qui contient TransactionId, SpanId et ParentSpanId. Dans ce qui suit Pinpoint et Span SpanEvent ajouté une structure utilisée pour enregistrer un appel Span des détails internes (tels que l'appel de méthode particuličre, etc.), de sorte enregistrement de données par défaut Pinpoint plus de trace Zipkin.
Mais la théorie n'est pas la taille des particules limitée Span, de sorte qu'un appel de service peut ętre une période, puis les appels de méthode pour chaque service peut aussi ętre un Span, donc, en fait, Brave peut aussi ętre attribuée au niveau d'appel de méthode, mais la mise en uvre spécifique et Je ne le faisais pas.
4.6.3 bytecode vs appels API
Pinpoint a réalisé la sonde Java Agent ŕ base bytecode et Zipkin le cadre Brave ne fournit que l'API niveau de l'application, mais ŕ la réflexion, le problčme est loin d'ętre simple. l'injection de bytecode est une solution simple et brute, en théorie, indépendamment des appels de méthode, d'interception peut ętre obtenue au moyen d'injection de code, qui est impossible ŕ réaliser, ne pas atteindre. Mais Brave est différent, API niveau d'application qui fournit un cadre pour les facteurs sous-jacents ont également besoin de soutien pour réaliser l'interception.
Par exemple, le pilote JDBC MySQL, il est prévu une méthode injection intercepteur, et donc seulement besoin de mettre en uvre l'interface StatementInterceptor et configurer la chaîne de connexion, vous pouvez la mise en uvre trčs simple de l'interception pertinente, tandis que d'autre part, la version basse MongoDB conducteur ressort données MongoDB ou la réalisation d'une telle interface ne veulent pas réaliser la fonction aux requętes d'interception, il est plus difficile.
Donc, ŕ ce stade, Brave est erronée, peu importe la façon dont bytecode difficile, mais au moins il est possible de réaliser, mais il n'y a aucun moyen de démarrer le Brave possible, mais si vous pouvez injecter, dans quelle mesure peut injecter plus en fonction de l'API-cadre au lieu de leurs propres capacités.
4.6.4 difficulté et le coűt
Aprčs un simple, lire le code Pinpoint et Brave widget peut ętre trouvé difficile ŕ obtenir ŕ la fois une grande différence. Dans les deux cas l'absence de toute documentation ŕ l'appui au développement de la prémisse, Brave facile ŕ utiliser que Pinpoint. Brave petite quantité de code, les fonctions de base sont concentrés dans ce module courageux-core, un développeur de niveau intermédiaire, vous pouvez lire son contenu en un jour, et peut avoir une compréhension trčs claire de la structure de l'API.
paquet de code Pinpoint est également trčs bon, en particulier pour le paquet supérieur de l'API bytecode est trčs bon, mais il faut encore du personnel de lire bytecode combien ont une certaine compréhension, bien qu'il utilisé pour injecter du code et l'API de base pas beaucoup, mais ŕ une compréhension approfondie de l'agent de code correspondant probablement la profondeur, comme il est difficile de comprendre un coup d'oeil la différence entre addInterceptor et addScopedInterceptor, qui est situé ŕ environ deux méthodes de type agent.
Parce que l'injection Brave repose sur le cadre sous-jacent fournit une interface pertinente, et n'a donc pas besoin d'avoir une compréhension globale du cadre, il suffit de savoir oů injecter en mesure, quelles données peuvent ętre acquises au moment de l'implantation sur elle. Comme dans l'exemple ci-dessus, on n'a pas besoin de connaître le pilote JDBC MySQL est comment atteindre peut faire pour intercepter les capacités SQL.
Mais PinPoint pas, parce que épinglent tout code peut ętre injecté en tout lieu, ce qui oblige les promoteurs ŕ base de code inject nécessaire pour obtenir une compréhension approfondie de MySQL en regardant et réaliser Http client plug-in divin bien sűr, cela montre aussi la capacité de Pinpoint peut ętre trčs puissant en effet d'une autre dimension, et sa mise en uvre par défaut des plug-ins ont fait beaucoup d'interception ŕ grain trčs fin.
En l'absence de cadre sous-jacent pour l'API ouverte, en fait, Brave ne fait pas tout ŕ fait rien, on peut prendre le mode AOP, le cas échéant pour intercepter peut ętre injecté dans un code spécifique et des applications apparemment AOP beaucoup plus simple que bytecode.
Ces coűts directement liés ŕ la réalisation d'un moniteur, dans la documentation technique officielle de Pinpoint, compte tenu des données de référence. Si l'intégration d'un systčme, les coűts de développement 100 est prise Pinpoint intégré dans le systčme, le coűt de ce plug-in est 0, mais courageux, plug-ins coűt de développement seulement 20, 10 et les coűts d'intégration. De ce point, on peut voir que le coűt des données de référence est donnée officielle 5: 1.
Mais le fonctionnaire a également souligné que, s'il y a 10 systčmes doivent ętre intégrés, le coűt total est de 10 * 10 + 20 = 120, il est au-delŕ du frais de développement Pinpoint 100, et plus la nécessité d'intégrer les services, l'écart sera.
4.6.5 polyvalence et évolutivité
De toute évidence, cela est tout ŕ fait un désavantage sur Pinpoint, développé ŕ partir de l'interface d'intégration communautaire peut ętre vu.
interface de données Pinpoint manque de documentation, mais aussi moins standard (voir le fil du forum de discussion), vous devrez peut-ętre lire beaucoup de code pour réaliser sa propre sonde (tel que le nud ou PHP). Et l'équipe d'envisager d'utiliser la performance Thrift que les normes de protocole de transmission de données, en termes de HTTP et JSON par rapport ŕ beaucoup plus difficile.
4.6.6 Soutien communautaire
Il est également inutile de dire, Zipkin développé par Twitter, il peut ętre considéré comme une équipe d'étoiles, alors que l'équipe de Naver est juste une petite équipe inconnue (de la discussion # 1759 peut ętre vu). Bien que ce projet ne risque pas de disparaître ou la mise ŕ jour d'arręt ŕ court terme, mais aprčs tout, que le premier est plus ŕ l'aise avec eux.
Et il n'y a pas plus développé plug-in communautaire, laissez l'équipe Pinpoint ŕ ne compter que sur ses propres forces, il est difficile d'achever l'intégration de nombreux cadres, et leur objectif actuel est encore sur l'amélioration des performances et de la stabilité.
4.6.7 Autres
Pinpoint au début pour atteindre un problčme de performance, la fin arričre du site www.naver.com certains services et traite plus de 20 milliards de requętes par jour, donc ils choisiront Thrift longueur variable binaire format de codage, et utiliser UDP comme le transport lien, également possible d'utiliser une référence de dictionnaire de données lors de la transmission constante, au lieu de transmettre directement une transmission numérique comme une chaîne. Ces optimisations augmente également la complexité du systčme comprennent: la difficulté d'utiliser l'interface Thrift, la transmission de données UDP question et des constantes de données des problčmes d'enregistrement du dictionnaire et ainsi de suite.
En revanche, Zipkin utilisant des interfaces familičres Restful, plus JSON, les coűts presque pas d'apprentissage et des difficultés d'intégration, il suffit de savoir que la structure de transmission de données, vous pouvez facilement un nouveau cadre pour développer l'interface appropriée.
De plus Pinpoint manque la possibilité de demander des échantillons, apparemment dans un grand environnement de production de flux, tous les dossiers ne sont pas susceptibles ŕ toutes les demandes, ce qui exige que les échantillons de demande afin de déterminer quelle est ma demande ŕ enregistrer. Pinpoint et Brave soutiennent le pourcentage d'échantillonnage, qui est, quel est le pourcentage de demandes seront enregistrées. Mais en plus Brave fournit également l'interface Sampler, vous pouvez personnaliser la stratégie d'échantillonnage, en particulier quand un test A / B de temps, cette fonction est trčs significative.
4.6.8 résumé
Dans les objectifs ŕ court terme, Pinpoint n'ont un énorme avantage: pas besoin d'apporter des modifications au code du projet peuvent ętre des sondes déployées, les données de suivi ŕ grains fins au niveau d'appel de méthode, puissante interface utilisateur et le cadre presque plus complet pour soutenir Java . Mais ŕ long terme, l'apprentissage interface de développement Pinpoint, ainsi que le coűt de mise en uvre future de l'interface est différents cadres sont encore inconnus.
Au contraire, il est relativement facile de saisir les braves et les communautés Zipkin plus forte et plus susceptibles de développer des interfaces plus ŕ l'avenir. Dans le pire des cas, on peut aussi ajouter leur propre chemin ŕ travers l'AOP est adapté ŕ la surveillance de notre propre code et n'a pas besoin d'introduire trop de nouvelles technologies et de nouveaux concepts. Et quand les changements d'affaires ŕ l'avenir, si les rapports officiels Pinpoint répondent aux exigences ne disent pas, l'ajout de nouveaux rapports apportera pas de prédire la difficulté du travail et de l'effort.
Le moniteur peut ętre divisé en surveillance de suivi et d'application. Le systčme surveille les données telles que la CPU, mémoire, réseau, du disque et de sorte que la charge globale du systčme, et peut affiner le spécifique de données correspondant ŕ chaque processus. Ce type d'information peut ętre obtenu directement ŕ partir du systčme. Applications Surveillance des applications qui nécessitent un soutien, expose les données appropriées.
l'application QPS tels que la demande interne, le retard de traitement de demande, le numéro d'erreur de demandes traitées, la longueur de file d'attente de la file d'attente de messages, des accidents, des informations de procédé de collecte des ordures et analogues. Surveiller l'objectif principal est d'alarme inhabituelle et en temps opportun.
Tracing la base et le coeur de toute la chaîne d'appel. La plupart sont liés au systčme métrique analyse de la chaîne d'appels pour se déplacer. Tracing principal objectif est d'analyser le systčme. Avant de trouver des problčmes que pour résoudre les problčmes et ensuite mieux.
Il y a beaucoup de points communs sur le traçage et le niveau d'application pile de technologie Moniteur. Nous avons une acquisition de données, l'analyse, le stockage et la formule d'exposition. Juste différentes dimensions de la collecte de données spécifiques, l'analyse ne sont pas les męmes.