
Auteur | nuage de technologie Modifier | Camel Cet article est l'Acadťmie chinoise d'ingťnierie et une lettre du nuage ensemble ŗ la technologie complŤte ťtant employťe papier AAAI2020 ę Couplť vision profonde Classififier apprentissage de plusieurs annotateurs Noisy Ľ interprťtation.

Ces derniŤres annťes, l'apprentissage en profondeur a prouvť l'efficacitť des diffťrentes t‚ches de classification, telles que l'utilisation de contrŰle du vent modŤle de train profond rťseau de neurones (DNN) sur l'ťtiquette de donnťes, et obtenu de bons rťsultats. Cependant, dans de nombreuses situations pratiques, telles que la surveillance vidťo et des images de diagnostic mťdical d'une scŤne rťelle, il est difficile de recueillir un ťtiquetage clair et prťcis.
Les nuages de l'Acadťmie chinoise des sciences et de la technologie et de la lettre travail publiť ę Couplť vue DeepClassififier apprentissage de plusieurs Noisy annotateurs Ľ, capables d'explorer une utilisation plus efficace des ťtiquettes d'information faible mťthode de classification de l'apprentissage en profondeur, une nouvelle ťtiquette des gens bruyants nouvelle mťthode pour l'apprentissage du classificateur en profondeur ŗ double vue de l'ťtiquette.
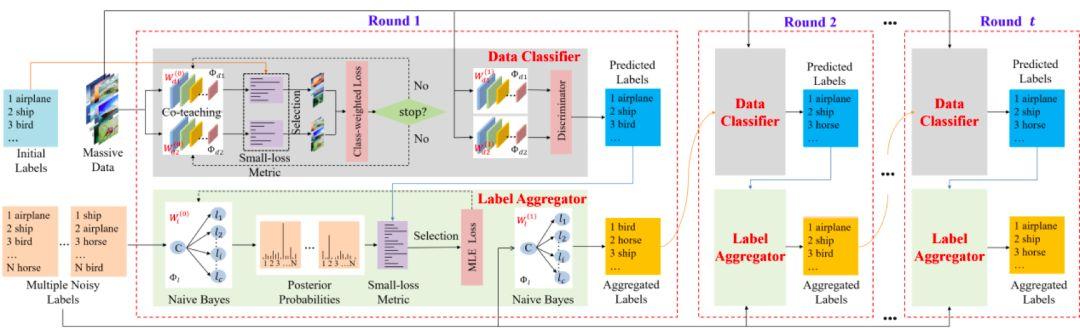
Ce document, nous nous concentrons sur l'ťtude approfondie du bruit du rťseau de neurones de personnes ťtude marquťe de la classification de l'ťtiquette de la question, l'attente maximisation algorithme de processus estimation itťrative des problŤmes d'apprentissage mutuel vu que les vues de l'ťtiquette et des vues de donnťes (figure 1). Nous apprenons en ayant deux points de vue sont gťnťrťs par un pseudo-label l'autre point de vue, mettre ce problŤme en un problŤme d'apprentissage supervisť, et en mettant ŗ jour l'ťtiquette et les paramŤtres du modŤle pseudo-itťratif, de sorte que les deux points de vue apprennent les uns des autres. Notre mťthode proposťe (appelťe CVL) rťduit l'erreur d'ťtiquettes surajustement, et a une performance de convergence plus stable.
NOUVEAU DOUBLE algorithme vue classification en fonction de la profondeur de l'apprentissage, l'utilisation complŤte des informations provenant de plusieurs balises de modťlisation faible dans la surveillance de la sťcuritť, le contrŰle du trafic aťrien, la sťcuritť financiŤre et d'autres domaines peuvent Ítre appliquťs, peut amťliorer efficacement le niveau de sťcuritť et des affaires de contrŰle des risques. Et le domaine de la sťcuritť avec des applications innovantes combiner amťliorer considťrablement la sťcuritť de renforcer le systŤme de rťglementation plus efficace de renforcer la capacitť de combat de la sťcuritť, d'amťliorer l'efficacitť de la sťcuritť. Pendant ce temps, dans le domaine du contrŰle des risques financiers, la technologie de sťcuritť innovante, dispose ťgalement d'un utilitaire stable.
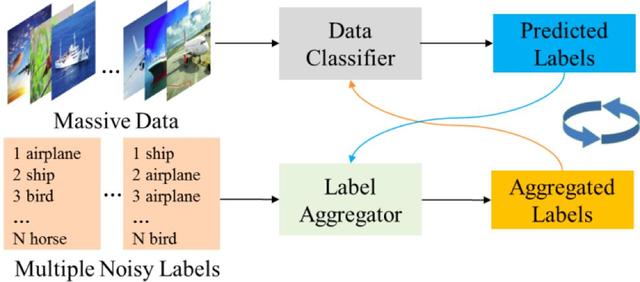
Figure 1: nouvelle mťthode pour le modŤle logique
Nouvel algorithme Vue d'ensemble
Les nouvelles tentatives d'algorithme pour construire un classificateur dans l'espace de reprťsentation et de l'espace d'ťtiquettes en deux vues, respectivement, dans le processus de formation, le rťsultat de deux classificateurs guident les uns des autres, la surveillance mutuelle, en alternance mise ŗ jour itťrative, la performance stable de la formation finale du classificateur.
Des expťriences ont ťtť rťalisťes deux ensembles de donnťes synthťtiques (MNIST et CIFAR10) et un ensemble de donnťes rťelles (LabelMe AMT), les derniers rťsultats de comparaison a montrť que, en termes de l'efficacitť de la mťthode CVL, la robustesse et la stabilitť sont meilleurs que d'autres.
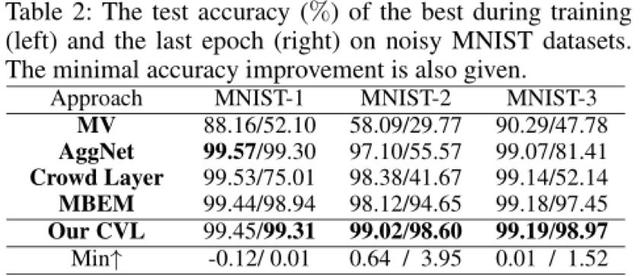
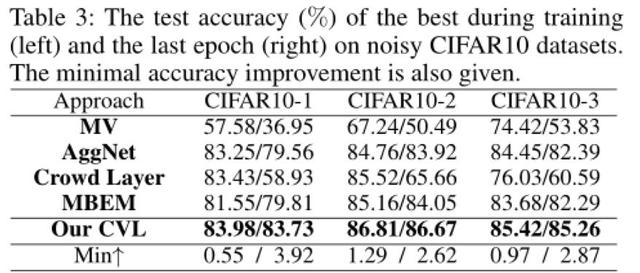
2 la figure, la figure 3: Dans les expťriences de mnist ensemble de donnťes synthťtiques et cifar10, notre mťthode est mieux que d'autres exemple de l'art antťrieur des rťsultats en termes d'efficacitť et de robustesse

Figure 4: Notre mťthode est mieux que d'autres algorithmes sur la convergence de la stabilitť
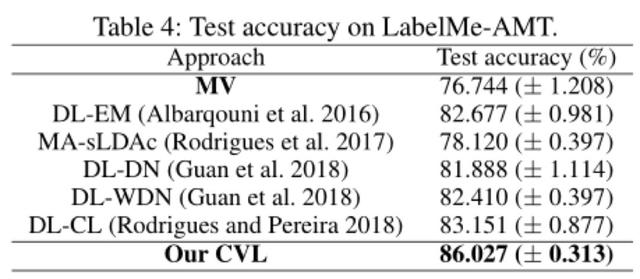
Figure 5: Les donnťes rťelles ťtablies LabelMe AMT, nos rťsultats nettement en avance sur d'autres algorithmes existants
Mťthodes de lecture
tout, nous pouvons d'abord Ítre faible surveillance de la question de la recherche sur les deux points de vue les uns des autres problŤmes d'apprentissage:
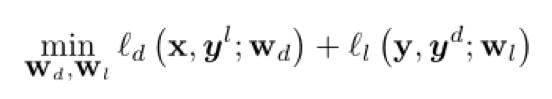
AprŤs l'initialisation et prť-formation, ce problŤme peut Ítre sous la supervision des balises prťvues et les ťtiquettes mises ŗ jour alternants recueillies en remplaÁant la solution d'optimisation. Ce point de vue double perspective offre un moyen simple et de maniŤre polyvalente, la polymťrisation et l'ťchange de connaissances classificateur de donnťes d'ťtiquettes avec l'autre.
Par la suite, nous avons adoptť plusieurs stratťgies en matiŤre d'apprentissage en vue de promouvoir Converge d'apprentissage mutuel ŗ un bon et des rťsultats stables.
1, vue de l'onglet Le modŤle de base. Si l'on suppose que le bruit de l'ťtiquette est le cas alťatoire et indťpendante de chaque ťtiquette, nous avons utilisť une matrice comme des paramŤtres confus de bruit pour l'ťtude des classificateur bayťsiens naÔfs. Dans le cas oý la catťgorie de bruit et de la matrice de confusion q constant distribution a priori, la probabilitť a posteriori de la classe k i-iŤme ťchantillon est calculťe par l'ťquation suivante:
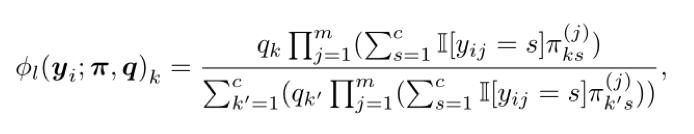
ModŤle de formation. L'insuffisance des problŤmes de formation seront rencontrťs deux vues de vue, cela signifie que les informations fournies sont insuffisantes pour voir prťdire adťquatement parfaitement tous les ťchantillons, ce qui inťvitablement erreur de prťdiction. Pour rťduire l'impact de ce facteur, nous utilisons une petite perte de mesures en tant que mesure de confiance dans l'ťtiquette, pour effectuer la sťlection de l'ťchantillon.
Compte tenu de l'ťtiquette, aprŤs une petite perte onglet de sťlection mťtrique perte d'estimation de probabilitť maximale comme suit:
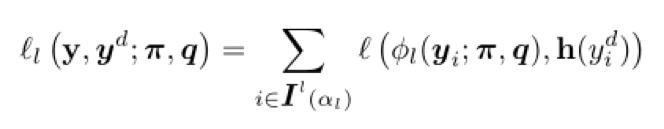
La fonction de perte, le paramŤtre peut Ítre estimťe par la formule suivante:
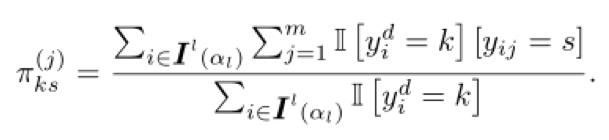
En outre, dans le cas des classes connues ensemble ťquilibrť.
Mise ŗ jour polymťrisation tag. Chaque tour, l'ťtiquette met ŗ jour son point de vue des ťtiquettes contrefaites une fois:
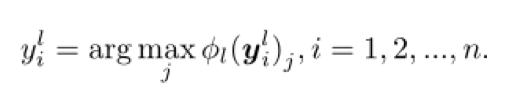
2, vue Le modŤle de base. Depuis la profondeur du rťseau a une grande capacitť ŗ apprendre, nous avons choisi les donnťes de classificateur de rťseau de neurones.
classificateur formť. En plus d'utiliser les mÍmes petites mesures de perte, nous vous proposons ťgalement deux stratťgies. Tout d'abord, puisque la profondeur du rťseau de grande capacitť, des donnťes arbitraires peuvent Ítre installťes, aprŤs la perte petite mťtrique, initialisťes en raison de diffťrentes causes diffťrentes biais de sťlection d'erreur. Nous autres stratťgies de co-enseignement adoptťes pour rťduire cet impact. Cela signifie que
Utilisez la mÍme structure, mais deux rťseaux diffťrents et l'initialisation, et dans chaque lot, chaque rťseau sera sťlectionnť une faible perte de l'ťchantillon considťrť comme des connaissances utiles, et ces ťchantillons pour enseigner leur rťseau de pairs pour paramŤtres de mise ŗ jour. …tant donnť que les deux rťseaux ont diffťrentes capacitťs d'apprentissage, qui peut filtrer les diffťrents types d'erreurs causťes par tag bruyante. En second lieu, puisque la catťgorie ťchantillon sťlectionnť est gťnťralement asymťtrique, il est nťcessaire d'ajouter les contraintes de l'ťquilibre des classes. Pour classificateur profondeur, ťtant donnť que notre mťthode sera choisie dans chaque lot d'ťchantillons, nous avons une perte dynamique de poids dans chaque catťgorie dans le lot, afin d'ťviter que certaines catťgories de prťfťrence sur un rťseau.
Au cours de la formation, chaque ťpoque, nous allons d'abord mťlanger et en lot p ,, (k = 1, 2, ..., p). Ensuite, deux rťseaux sťlectionnťs dans chaque lot d'ťchantillons d'un ensemble respectif de petites pertes ŗ l'apprentissage du rťseau de pairs. K-iŤme fonction de perte de charge suit comme:
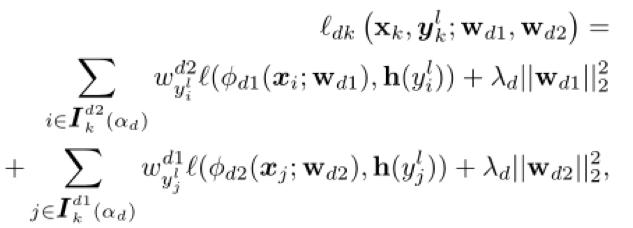
ťtiquette prťvision actualisťe. Chaque tour, dans le cas oý deux sorties de rťseau et les rťsultats de la classification, respectivement, par la vue de formule suivante met ŗ jour l'onglet.
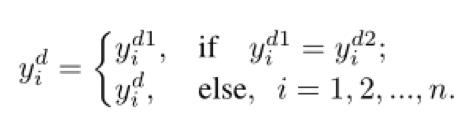
Actes de AAAI 2020: AAAI 2020 @ papier Wangjing interprťtera (PPT tťlťcharger )