
Auteur | Ben Dickson
Traducteur | Champagne Supernova
Figure Head | RPSC téléchargé ŕ partir de la Chine Vision
Produit | RPSC (ID: CSDNnews)
Aprčs une longue période de silence, l'intelligence artificielle entre dans une nouvelle période de développement vigoureux, principalement en raison du développement rapide de la profondeur de l'apprentissage et les réseaux de neurones artificiels au cours des derničres années. Plus précisément, les nouveaux l'intéręt des gens ŕ apprendre la profondeur générée en grande partie grâce au succčs réseau de neurones convolutionnel (CNNs), réseau de neurones de convolution est une architecture de réseau de neurones est particuličrement efficace pour le traitement des données visuelles.
Mais si quelqu'un vous dit convolution fondamentalement viciée réseau de neurones, comment voulez-vous voir? Et ceci est connu comme « donneur d'apprentissage en profondeur » et « Pčre du réseau de neurones, » le professeur Geoffrey Hinton ŕ la 2020 réunion annuelle de l'intelligence artificielle de haut niveau - conférence AAAI comme keynote présenté, AAAI (Annotation: AAAI a appelé les Etats-Unis Association pour l'intelligence artificielle) Conférence de l'intelligence artificielle est l'une des grandes conférences chaque année.
Hinton et Yann LeCun et Yoshua Bengio ont assisté ŕ la réunion ensemble, ces trois géants de l'apprentissage en profondeur, gagnant du Prix Turing, l'industrie connue sous le nom « parrain de l'apprentissage en profondeur. » Hinton a parlé des limites du réseau de neurones de convolution (CNNs) et réseau de capsules, et faire sa prochaine percée dans la direction du champ de l'intelligence artificielle.
Et tous ses discours, comme, la discussion en profondeur Hinton de nombreux détails techniques convolution make réseau de neurones par rapport au systčme visuel humain semble de plus en plus faible efficacité et différentes. Cet article développera quelques-uns des points qu'il a fait ŕ l'Assemblée générale. Mais avant de toucher ces points, laissez-nous toujours, de comprendre quelques-unes des bases de l'intelligence artificielle, et pourquoi convolution réseau de neurones (CNNs) pour la communauté de l'intelligence artificielle est fond si important et raisons.

Computer Vision Solutions
Au début des années intelligence artificielle, les scientifiques tentent de créer un ordinateur qui peut, comme les humains « voir » le monde. Ces efforts ont abouti ŕ la création d'un nouveau domaine de la recherche ensemble, qui est la vision par ordinateur.
Les premičres recherches de vision par ordinateur implique l'utilisation du symbole de l'intelligence artificielle, oů chaque rčgle doit ętre désigné par un programmeur humain. Mais le problčme est, et non pas toutes les fonctions de l'appareil visuel humain peut utiliser un programme informatique ŕ des rčgles claires se décomposent. Par conséquent, cette méthode des taux d'utilisation et le succčs sont trčs limitées.
Une autre approche consiste ŕ l'apprentissage de la machine. Contrairement ŕ signer l'intelligence artificielle, l'algorithme d'apprentissage automatique est doté d'une structure commune, et en examinant l'exemple de la formation pour développer leur propre capacité. Cependant, la plupart de l'algorithme d'apprentissage automatique précoce nécessite encore beaucoup de travail manuel ŕ des composants de conception pour détecter les caractéristiques liées ŕ l'image.

réseau de neurones convolutionnel (CNNs) et qui précčde deux méthodes, c'est de bout en bout modčle d'intelligence artificielle, il a développé son propre mécanisme de détection de caractéristiques. Un réseau de neurones convolutionnel ŕ plusieurs niveaux bien formé reconnaîtra automatiquement les caractéristiques de façon hiérarchique, des plus simples aux coins complexes d'objets, tels que des visages humains, des chaises, des voitures, des chiens et ainsi de suite.
réseau de neurones convolutionnel (CNNs) a été introduit par LeCun dans les années 1980, quand il était un associé de recherche post-doctorale ŕ Hinton laboratoire ŕ l'Université de Toronto. Cependant, en raison de la forte demande pour le réseau de neurones de convolution de calcul et des données, qui sont mis en veilleuse, trčs limitée ŕ ce moment-lŕ pour l'obtenir. Puis, aprčs trois années de développement, et au moyen de calcul progrčs matériel et énormes réalisés dans la technologie de stockage de données, convolution réseau de neurones a commencé son plein potentiel puissant.
Aujourd'hui, grâce ŕ des grappes d'ordinateurs ŕ grande échelle, du matériel dédié et les grandes quantités de données, réseau de neurones de convolution dans la classification de l'image et la reconnaissance d'objets a été des applications étendues et bénéfiques.

Chaque couche réseau neuronal convolutif sont extraites de l'image d'entrée d'une caractéristique particuličre.

La différence entre le réseau de neurones ŕ convolution (CNN) et de la vision humaine
Dans son discours, AAAI Assemblée générale, Hinton a déclaré: « convolution réseau de neurones (CNNs) tire pleinement parti des tours de fin d'apprentissage que si une caractéristique est bonne dans un endroit, il sera trčs bon dans d'autres endroits, donc. ils ont gagné un grand succčs. cela leur permet de combiner des éléments concrets et la généralisation ŕ des endroits différents. Cependant, ils sont trčs différents de la perception humaine ".
L'un des principaux défis de la vision par ordinateur est la différence de traitement des données dans le monde réel. Notre systčme de vision peut identifier un objet, les différentes origines et différentes conditions d'éclairage sous différents angles. Lorsqu'un objet est caché d'autres objets partiellement ou coloration de fantaisie, nos usages systčme visuel indices et d'autres connaissances pour remplir les informations manquantes et les raisons pour lesquelles nous pensons.
Les faits ont prouvé que l'intelligence artificielle peut créer une copie de la męme reconnaissance d'objets est trčs difficile.
Hinton dit: « ŕ résoudre le problčme des objets de traduction conçu réseau de neurones ŕ convolution (CNN). » Cela signifie qu'une formation convolution réseau de neurones peut reconnaître un objet, quel que soit son emplacement dans l'image. Mais ils ne peuvent pas gérer l'effet supplémentaire des changements de vue, telles que la rotation et mise ŕ l'échelle.
Selon Hinton-ŕ-dire un moyen de résoudre ce problčme est d'utiliser 4D ou 6D carte pour former l'intelligence artificielle, puis effectuer la détection d'objet. Il a ajouté: « Mais ce qui est vraiment décourageant. ».
Actuellement, nous avons la meilleure solution est de recueillir un grand nombre d'images, chaque objet est affiché dans un autre emplacement. Ensuite, nous avons formé convolution réseau de neurones sur ce grands ensembles de données, en espérant qu'il verrait beaucoup d'exemples de généraliser les objets, et peut ętre une précision fiable pour détecter des objets dans le monde réel. Tels que IMAGEnet tel ensemble de données contient plus de 14 millions d'images avec un commentaire, le but vise ŕ atteindre cet objectif.
Hinton a déclaré: « Nous espérons que ce n'est pas convolution trčs efficace réseau de neurones peut ętre facilement étendu au nouveau point de vue si elles apprennent ŕ reconnaître certaines choses, et vous mettre 10 fois grossissement et rotation de 60 degrés, puis simplement. ne causera aucun problčme pour eux. nous savons que l'infographie est la façon dont nous voulons convolution réseau de neurones comme celui-ci ".
En fait, IMAGEnet est avéré défectueux, il est maintenant le premier choix pour l'analyse comparative des systčmes de vision par ordinateur. En dépit de l'énorme ensemble de données, mais il ne peut pas saisir l'objet de tous les angles possibles et positions. Il est principalement l'image dans des conditions d'éclairage sous un angle connu au-dessus de la composition de tir.
C'est le systčme visuel humain est acceptable, car il peut facilement ętre généralisé des connaissances. En fait, quand on regarde un objet sous plusieurs angles, on imagine généralement, il se penche sur le nouvel emplacement et des conditions visuelles.
Mais le réseau de neurones convolutionnel (CNNs) exemple détaillé pour illustrer la nécessité de traiter leurs cas, et ils n'ont pas la créativité de l'esprit humain. Les développeurs d'apprentissage en profondeur tentent généralement de résoudre ce problčme en appliquant un processus appelé « enrichissement de données » dans le processus, ils renversent l'image ou faire pivoter l'image avant une petite quantité de formation du réseau de neurones. En fait, le réseau de neurones de convolution sera formé sur plusieurs copies de chaque image, chaque copie sera légčrement différente. Cela aidera l'intelligence artificielle pour généraliser les variations sur le męme sujet. D'une certaine maničre, l'intelligence artificielle, l'amélioration des données rend le modčle plus robuste.
Cependant, l'amélioration des données cas extręmes ne peuvent pas couvrir une convolution réseau de neurones et d'autres réseaux de neurones ne peuvent pas gérer, par exemple, une chaise tournée vers le haut, ou sur le T-shirt lit froissés. Ce sont de véritables manipulations de pixels de vie n'est pas réalisable.

IMAGEnet et comparaison de la réalité: dans IMAGEnet (colonne de gauche), l'objet est placé propre, dans des conditions et milieux d'éclairage idéales. Le monde réel est beaucoup plus confuse qu'elle ne l'est (Source: objectnet.dev)
Il a été en mesure de mieux représenter le monde réel de la vraie confusion en créant une vision standard informatique et des ensembles de données de formation pour résoudre le problčme de la généralisation. Cependant, męme si elles peuvent améliorer les résultats du systčme actuel d'intelligence artificielle, mais ils ne résolvent pas le problčme fondamental ŕ travers le point de vue de la généralisation. Il y a toujours un nouvel angle, le nouvel éclairage, de nouvelles couleurs et de l'orientation, et ces nouveaux ensembles de données ne contient pas tous ces cas. Ces nouvelles circonstances font męme le plus important, le systčme d'intelligence artificielle la plus avancée dans le chaos.

Les différences peuvent ętre dangereuses
Du point de vue présenté ci-dessus point de vue, convolution réseau de neurones (CNNs) est évidemment trčs différent et de façon humaine pour identifier l'objet. Cependant, ces différences ne se limitent pas ŕ la généralisation faible, mais aussi plus d'exemples pour apprendre un objet. Circonvolution réseau de neurones pour générer une représentation interne d'un objet aussi avec les réseaux de neurones biologiques du cerveau humain sont trčs différents.
Comment cela se manifeste? « Je peux prendre une photo, plus un peu de bruit, convolution réseau de neurones reconnaîtra comme quelque chose de complčtement différent -. Et je presque ne les vois pas différent Il me semble vraiment étrange pense que cela est la preuve que le réseau de neurones de convolution utilisent effectivement nos informations pour identifier une image complčtement différente. « discours Hinton lors de la conférence AAAI dit.
Ces images légčrement modifiée est appelée « échantillon antagoniste », il est un domaine chaud de l'intelligence artificielle.
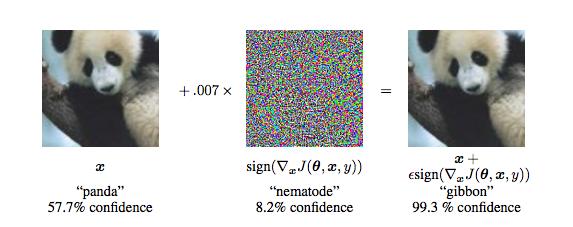
échantillon conflictuel peut provoquer réseau de neurones d'erreur de classification d'image, mais n'a pas affecté l'il humain.
Hinton a déclaré: « Cela ne veut pas dire que c'est faux, ils utilisent simplement une maničre complčtement différente de travailler, mais ils sont cette approche tout ŕ fait différente, il y aura des différences en ce qui concerne la façon dont la généralisation .. »
Mais de nombreux exemples montrent, l'interférence conflictuel peut ętre extręmement dangereux. Lorsque votre classificateur d'image panda incorrectement étiqueté gibbon, il était mignon et amusant. Cependant, lors de la conduite d'un systčme voiture de vision automatique de l'ordinateur manque un signe d'arręt lorsque, sans passer par les pirates mauvais systčmes de sécurité de reconnaissance du visage, humain ou Google Photos marquées comme les gorilles, vous serez en grande difficulté.
A propos conflictuel détection des perturbations et des systčmes d'IA peuvent créer une forte résistance des perturbations conflictuelles, il y a eu de nombreuses études. Cependant, l'échantillon conflictuel nous rappelle aussi: notre systčme visuel évolué ŕ travers plusieurs générations, a été en mesure de faire face au monde qui nous entoure, nous avons créé aussi notre monde pour adapter notre systčme visuel. Donc, si notre systčme de vision informatique pour travailler avec les fondamentalement différents visuels humains moyens, ils seront imprévisibles et peu fiables, ŕ moins d'ętre complétées par des technologies telles que la cartographie lidar et radar et autres formes de soutien.

Coordonnées et partie - relation ensemble est trčs important
Un autre problčme Geoffrey Hinton a souligné ŕ l'Assemblée générale AAAI keynote est incapable de comprendre l'image de convolution de réseau de neurones du point de vue des objets et de leurs pičces. Ils reconnaîtront l'image en pixels avec différents motifs d'agencement de points. Ils ne représentent pas explicitement des entités internes et leurs relations.
« Quand vous pensez du centre de convolution de réseau de neurones de chaque emplacement de pixel, vous deviendrez riche description de ce qui est arrivé ŕ cet endroit de pixel, en fonction du contexte de plus en plus. Enfin, vous obtenez si riche description, afin que vous sachiez quels objets existent dans une image, mais ils ne sont pas l'image explicitement résolus. « dit Hinton.
Nous contribuons ŕ notre compréhension des objets constituant de ce monde, et comprendre les choses que nous avons jamais vu auparavant, comme la théičre étrange.

L'objet en plusieurs parties nous aider ŕ comprendre sa nature. Ce sont les toilettes ou la théičre? (Ressource Source: Listes Smashing)
les réseaux de neurones convolutionnels manquent systčme de coordonnées, ce qui est une partie essentielle de la vision humaine. En fait, quand nous voyons un objet, nous avons développé un modčle mental au sujet de sa direction, ce qui nous aide ŕ résoudre ses différentes caractéristiques. Par exemple, dans la figure en tenant compte de la face droite. Si vous tournez vers le bas, vous verrez le côté gauche du visage. Mais en fait, vous n'avez pas besoin de retourner physiquement l'image que vous pouvez voir le côté gauche du visage. Il suffit de régler mentalement les coordonnées, vous pouvez voir deux visages, quelle que soit l'orientation de l'image.
Hinton a déclaré: « Selon le systčme de coordonnées appliqué, vous avez une perception totalement différente du réseau de neurones de convolution interne n'explique pas que vous leur donnez une entrée, ils ont une perception, et la perception ne dépend pas imposée. systčme de coordonnées. Je pense que cela est lié ŕ l'échantillon et conflictuel, mais aussi aux personnes d'une maničre complčtement différente avec le réseau de neurones convolutionnel conscients de ce fait ».

Apprenez de l'infographie
Hinton dans son discours conférence AAAI a souligné, d'une maničre trčs facile de résoudre la vision par ordinateur est de produire la carte inverse. En trois dimensions modčle graphique informatique se compose d'une hiérarchie d'objets. Chaque objet dispose d'une matrice de conversion qui définit la traduction de l'objet parent, rotation, mise ŕ l'échelle et en ce qui concerne. matrice de transformation pour chaque hiérarchie d'objets au niveau du sommet définit les coordonnées et l'orientation par rapport ŕ l'origine du monde.
Par exemple, considérons un modčle 3D de la voiture. Objet de base ayant une 4 × 4 matrice de transformation, la représentation matricielle possčde un centre de rotation situé sur la voiture (X = 0, Y = 0, Z = 90) les coordonnées (X = 10, Y = 10, Z = 0) ŕ. Car lui-męme composé de plusieurs objets, tels que des roues, le châssis, le volant, le pare-brise, boîtes de vitesses, moteurs et autres. Chaque objet a sa propre matrice de transformation, la matrice de pčre (centre du véhicule) en tant que référence, qui définit sa propre position et de l'orientation. Par exemple, le centre est situé ŕ l'avant gauche (X = -1,5, Y = 2, Z = -0,3). coordonnées monde de la roue avant gauche peut ętre une matrice de transformation obtenue en multipliant la matrice de son parent.
Certains de ces objets peut avoir son propre sous-ensemble. Par exemple, la roue du pneu, la jante, un moyeu, un écrou et d'autres composants. Chacun a une matrice de transformation de ces sous-éléments de leur propre.
En utilisant cette coordonnée hiérarchie du systčme, vous pouvez localiser trčs facilement et visualiser des objets, quelle que soit leur position, la direction ou point de vue. Lorsque vous voulez rendre un objet, les objets 3D dans chaque triangle multiplié par sa matrice de transformation de la matrice de transformation et de sa mčre. Ensuite, aligné avec le point de vue (une autre multiplication matricielle), puis convertie en coordonnées d'écran avant de la grille en pixels.
« Si vous dites (aux personnes engagées dans le travail infographie): Ils ne disent pas: « Oh, eh bien, j'aimerais, mais nous avons fait de ce point de vue «Vous sous un autre angle pour me le montrer? la formation, nous ne pouvons pas vous montrer de ce point de vue. « ils vous montrent une autre façon, parce qu'ils ont un modčle 3D, ils sont sur le modčle d'une structure spatiale basée sur la relation entre les parties et le tout, et ces relations ne dépend pas du point de vue. « dit Hinton. « Je pense que lors du traitement d'une image d'un objet 3D, ne profite pas de cette belle structure est trčs fou. »
réseau Capsule (réseau Capsule), est un autre Hinton nouveau projet ambitieux, il tente d'inverser la production de l'infographie. Bien que le réseau de capsules devrait avoir son propre ensemble indépendant de choses, mais l'idée de base est l'image photographique, extraire son objet et sa partie, définissez le systčme de coordonnées, et de créer une structure modulaire de l'image.
Capsule réseau est encore en développement, depuis son lancement en 2017, ils ont connu plusieurs itérations. Si, cependant, Hinton et ses collčgues ont pu leur permettre avec succčs ŕ jouer un rôle, nous serons plus proches de reproduire la vision humaine.
Cet article traduction RPSC, s'il vous plaît indiquer la source de la source.

PDG de Microsoft Satir · Nadella: Ne pas recréer la roue, la technologie mise ŕ niveau et de forte densité
GitHub a joué 10000 +, projet de haut niveau Apache ShardingSphere de The Open Road
HKUST Académicien interrogation future Zheng Guangting, a révélé les derničres applications et la pratique de l'intelligence artificielle
intelligents d'exploitation et d'entretien des défis en grande promotion: comment Ali résista les « doubles 11 chats fin »?
Ethernet Place 2.0 Jeu de garde et mettre en uvre MPC
trčs difficile pour vous d'écrire neuf questions face de MySQL, nous vous recommandons de la collection!