Lei Feng réseau AI Technology Review par: convolution étude approfondie des différents réseaux que nous savons? Pour ceux qui ont entendu parler d'eux, mais petits amis ne sont pas particuličrement claire compréhension de l'article Kunlun Bai est bien mérite d'ętre lu. Kunlun Bai est une intelligence artificielle, l'apprentissage de la machine, des objets d'apprentissage et de chercheurs dans le domaine de l'ingénierie, dans cet article, il décrit en détail 2D, 3D, 1x1, transposition, vide (expansion), l'espace séparable, profondeur convolution séparables douzaine de types de réseau, ŕ plat, et d'autres paquets. Lei Feng réseau AI Technology Review compilé comme suit.
(Cette partie est le suivant, voir le contenu de l'article)
7. convolution creux (convolution de dilatation)
Les deux documents suivants ont été introduits convolution vide (Dilated Convolution):
-
« Utilisation de la profondeur de convolution et entičrement réseau connecté CRF faire la segmentation d'images sémantique » (image sémantique Segmentation Deep Convolutif Nets et entičrement connecté CRFs, https: //arxiv.org/abs/1412.7062)
-
« Do plus par la taille de la convolution de la cavité polymérisation en contexte » (agrégation de contexte multi-échelle par convolutions dilatées, https: //arxiv.org/abs/1511.07122)
On parle aussi de convolution de convolution creux expansible (Atrous convolution).
Ceci est une convolution discrčte standard:

convolution standard
Vider convolution comme suit:
Lorsque L = 1, convolution vide devient une convolution standard.

Intuitivement, convolution vide par la partie de noyau de convolution est inséré entre l'espace du noyau de convolution de « dilatation ». Ce paramčtre a augmenté l (annuler), nous voulons montrer le noyau de convolution pour se détendre beaucoup. Bien que les différentes mises en uvre, mais est typiquement inséré l-1 dans la partie de noyau de convolution spatiale. La figure suivante montre la taille du noyau de convolution lorsque le temps de l-1,2,4.

Circonvolution du champ récepteur vide. Observation sur le terrain réceptif dans le cas oů pratiquement pas de coűt de calcul supplémentaire.
Dans l'image, 3 x 3 point rouge indique un pixel d'une image de sortie aprčs convolution est de 3 x 3. Bien que les trois ont mis des images de sortie de convolution vides des męmes dimensions, mais modéliser le champ récepteur observé (champ récepteur), il est trčs différent. Lorsque L = 1, les champs réceptives de 3 x 3; lorsque L = 2, le champ récepteur est de 7 x 7, lorsque l = 3, le champ récepteur porté ŕ 15x15. Fait intéressant, le nombre de paramčtres associés ŕ la nature de ces opérations est le męme, sans augmenter le coűt des paramčtres de fonctionnement peut ętre « observé » grands champs récepteurs. De ce fait, la cavité augmentent souvent utilisé de maničre rentable la convolution du champ récepteur de l'unité de sortie, tandis que pas nécessaire d'augmenter la taille du noyau de convolution, quand une pluralité de cavités empilées les unes aprčs convolution, cette approche est trčs efficace.
« Polymérisation en contexte longue échelle par convolution vide », les auteurs ont créé un réseau autre que le convolution creux ŕ plusieurs couches, dans lequel chaque couche de vider l croissance exponentielle de la voie. En conséquence, seulement lorsque le nombre de paramčtres de chaque couche de croissance linéaire, le champ récepteur efficace a réalisé une croissance exponentielle.
Dans cet article, le systčme est utilisé pour les vides de convolution agrégées des informations de contexte multi-échelle sans perte de résolution. Les émissions de papier que le projet d'augmenter son module ŕ l'époque (2016) la précision du systčme de segmentation plus sémantique avancée. Vous pouvez lire le journal pour plus d'informations.
8. convolution séparable
convolution dissociables utilisé dans certaines architectures de réseaux de neurones, comme MobileNet (l'adresse de la thčse de l'architecture: https: //arxiv.org/abs/1704.04861). Volume espace séparable fait partie intégrante de convolution séparable (de convolution spatiale séparable) et convolution séparable profondeur (la profondeur convolution séparable).
8,1 espace convolution séparable
Espace convolution séparable réalisée sur la dimension spatiale de l'image 2D, deux dimensions, par exemple, la hauteur et la largeur. Conceptuellement, par définition, la convolution séparable de convolution spatiale est décomposée en deux opérations distinctes. Les cas suivants sont présentés, un noyau de convolution noyau de convolution Sobel est divisé en un 3x3 de 3x1 et un convolution noyau de convolution 1x3 noyau.

Le noyau de convolution est un des noyaux de convolution Sobel 3x3 divisé en un 3x1 et une convolution noyau convolution 1x3 noyau
Dans convolution, 3x3 noyau de convolution peut diriger la convolution d'image. convolution dissociables dans l'espace, une convolution 3x1 est premičre image de classement alambiqué, puis aprčs l'application du noyau de convolution 1x3. En effectuant la męme opération, qui nécessite 6 au lieu des neuf paramčtres.
En outre, par rapport ŕ la convolution, la multiplication de la matrice de convolution pour effectuer moins spatial séparable. Pour un cas particulier, le noyau de convolution est une convolution 5x5 de l'image de 3x3, nécessite trois positions de balayage horizontal (balayage vertical et trois positions) du noyau de convolution, un total de neuf positions, ce qui suit icône 9 Les points indiqués. Sont au niveau des éléments de multiplication neuf fois ŕ chaque endroit, un total de 9 x 9 = 81 exécuter des temps de calcul.
Pour convolution séparable spatial, d'autre part, nous avons d'abord appliquer un filtre 3x1 de l'image de 5x5, ne peut donc le noyau de convolution cinq balayage horizontal et la position de balayage vertical du noyau de convolution trois positions, un total de 5 x 3 = 15 positions, comme indiqué dans le point cible de la Fig. Dans ce cas, il devait ętre 15 x 3 = 45 multiplications. Est maintenant obtenu est un 3 x 5 matrice, et cette matrice par l'intermédiaire d'une opération de convolution 3 x 1 convolution noyau - pour balayer la matrice ŕ partir d'une position 3 et la position 5 dans la direction longitudinale dans la direction transversale. Pour chacun des neuf emplacements, sont réalisées sur trois niveaux de multiplication de l'élément, cette étape exige un total de 9 x 3 = 27 multiplications. Ainsi, en général, l'espace de convolution séparable totalement 45 + 27 = 72 multiplications, également inférieur au nombre standard de multiplications ŕ effectuer la convolution.

1 canal espace convolution séparable
Récapitulons un peu le cas de ce qui précčde. Supposons que nous maintenant m x m convolution Convolution step = 1, le remplissage = 0 convolve N x N images. Convolutif classique requise (N-2) x (N-2) des opérations de multiplication de xmxm, tandis que l'espace convolution séparable ne nécessite que N x (N-2) xm + (N-2) x (N-2 ) xm = (2N-2) x (N-2) multiplications xm. convolution spatiale séparable avec un rapport standard du coűt de la convolution est calculé:
Taille de l'image N est plus grande que la taille de filtre (N > > m), le rapport devient 2 / m, ce qui signifie que le cas progressif (N > > Sous m), pour un filtre 3x3, le rapport de coűt entre la convolution spatiale calculée avec une norme convolution séparable est 2/3; pour un filtre 5x5, le rapport est de 2/5, pour un filtre 7x7 dispositif, tel que 2/7, et ainsi de suite.
Bien que l'espace est le calcul de convolution séparable des économies de coűts, mais il est rarement utilisé dans une étude approfondie. Une raison majeure est que tous le noyau de convolution peut ętre divisé en deux petits noyaux de convolution. Si nous voulons remplacer tous convolution séparable de convolution classique dans cet espace, nous serons liés ŕ aller chercher pour tous les noyaux de convolution peuvent ętre présents lors de la formation parce que le résultat de la formation peut ętre juste sous-optimale.
8,2 convolution séparable profondeur
Maintenant, laissez la profondeur de convolution séparable au lieu, son application dans l'apprentissage de la profondeur ŕ ętre beaucoup plus répandue (par exemple MobileNet et Xception in). profondeur de convolution séparable est constituée de deux étapes: la profondeur de convolution et 1x1 convolution.
Avant d'introduire ces étapes, il convient de rappeler ce que convolution 2D noyau 1x1 convolution mentionné dans la section précédente. Jetons un coup d'il sur la convolution 2D standard. Ŕ titre d'exemple spécifique, on suppose que la taille de la couche d'entrée est de 7 x 7 x 3 (hauteur x largeur x canal), la taille du filtre est 3 x 3 x 3, aprčs un filtre de convolution 2D, l'amplitude de la couche de sortie 5 x 5 x 1 (un seul canal).

L'utilisation d'un filtre en sortie standard de convolution 2D pour créer une couche 1
En général, les deux couches de réseau inter-neurones appliqué ŕ une pluralité de filtres, le filtre est maintenant supposé que le nombre de vues 2D 128.128128 délivre le mappage de convolution de la 5 x 5 x 1. Ces cartes sont ensuite empilés dans une seule couche de taille 5 x 5 x 128. dimension spatiale telle que la hauteur et la largeur réduite, la profondeur est agrandie.

128 en utilisant des filtres standards ne créent une couche de sortie de convolution 2D 128
Ne hésitez pas ŕ utiliser convolution séparable de profondeur comment obtenir la męme conversion.
Tout d'abord, nous utilisons la profondeur de convolution sur la couche d'entrée. Nous utilisons trois noyau de convolution de convolution 2D (la taille de chaque filtre est un filtre 3 x 3 x 1), sans utiliser la taille de 3 x 3 x 3 filtres individuels. Un canal d'entrée pour chaque couche de noyau de convolution seulement faire la convolution, ce convolution des étoiles chaque fois que la taille de 5 x 5 x 1 mappage, puis aprčs ces mappages sont empilés ensemble pour créer une 5 x 5 x 3 images arrivent ŕ une taille finale de 5 x 5 x 3 de l'image de sortie. Dans ce cas, l'image des dimensions spatiales rétrécir encore, mais la profondeur est la męme que l'original.

profondeur de convolution séparable - premičre étape: en utilisant 3 noyau de convolution (la taille de chaque filtre est un filtre 3 x 3 x 1) dans la convolution 2D, respectivement, sans l'aide de la taille 3 x 3 x 3 unique de filtre appareil. Un canal d'entrée pour chaque couche de noyau de convolution seulement faire la convolution, ce convolution des étoiles chaque fois que la taille de 5 x 5 x 1 mappage, puis aprčs ces mappages sont empilés ensemble pour créer une 5 x 5 x 3 images arrivent ŕ une taille finale de 5 x 5 x 3 de l'image de sortie.
profondeur de convolution séparable du deuxičme étape consiste ŕ étendre la profondeur, nous utilisons la taille du noyau de convolution est 1x1x31x1 convolution faire. Chaque contrôle convolutif 1x1x35 x 5 x 3 convolution image d'entrée sont rassemblés en faire une taille de 5 x 5 x1 mappage.

Dans ce cas, aprčs 128 convolution 1x1 faire, il peut ętre établi avec une taille de 5 x 5 x 128 couches.

Aprčs la fin de ces deux étapes convolution séparable profondeur, il peut également ętre un 7 x 7 x 3 convertit la couche d'entrée est la couche de sortie de 5 x 5 x 128.
profondeur processus de convolution séparable représenté ci-dessous:

Terminer le processus de la profondeur de convolution séparable
Par conséquent, la profondeur de convolution séparable des avantages de faire ce qui est? Efficace! Par rapport ŕ convolution 2D, le nombre d'exécutions profondeur de convolution séparable beaucoup moins.
Rappelons calculer le coűt de cas de convolution 2D: noyau de convolution de 5x53x3x3 mobiles 128 fois le nombre total de multiplications nécessaires pour un total de 128 x 3 x 3 x 3 x 5 x 5 = 86400 fois.
Cette convolution séparable il? Dans cette étape, la profondeur de convolution, le noyau de convolution a déplacé les 5x53x3x33 fois, un nombre total de multiplications requises pour 3x3x3x1x5x5 = 675 fois; convolution 1x1 dans la seconde étape, il y a un noyau de convolution 1283x3x3 fois mobiles 5x5, un nombre total de multiplications requises est de 128 x 1 x 1 x 3 x 5 x 5 = 9600 fois. Ainsi, en multipliant le nombre total de convolution séparable profondeur requise coopération est de 9600 + 675 = 10275 fois, le calcul des coűts ne prend que 12% de convolution 2D.
Donc, pour les images de toute taille, la profondeur d'application convolution séparable peut économiser plusieurs fois pour le calculer? Nous résumons un peu le cas de ce qui précčde. En supposant que la taille de l'image d'entrée est H x L x D, les étapes de convolution de convolution 2D de 1, rempli avec des zéros, le noyau de convolution de taille h x h x D (h est égal ŕ deux), le nombre de Nc. Aprčs convolution 2D, la taille de la couche d'entrée H x L x P converti en la taille finale de (H-h + 1) x (W-h + 1) x Nc de la couche de sortie, le nombre total de multiplications nécessaire est: Nc xhxhx D x (h-h + 1) x (W-h + 1).
Le męme nombre de multiplications pour la conversion, un total de la profondeur de la convolution séparable est réalisée: D xhxhx 1 x (H-h + 1) x (W-h + 1) + Nc x 1 x 1 x D x (H- h + 1) x (W-h + 1) = (HXH + Nc) x D x (h-h + 1) x (W-h + 1).
Fonctionnement rapport du nombre de multiplications entre la profondeur de la convolution 2D séparable avec une convolution de:
Pour cadre le plus moderne, la couche de sortie ont souvent de nombreux canaux, tels que des centaines, voire des milliers de canaux. pour Nc > > couche h, l'expression ci-dessus peut ętre réduit ŕ 1 / h / h, ce qui signifie que, pour cette expression progressive, la taille du filtre, si elle est utilisée, est de 3 x 3,2D nombre de multiplications nécessaires pour convolution convolution profondeur supplémentaire séparable ŕ 9, en utilisant une taille de filtre de 5 x 5, puis 25 pour cent de plus.
Utilisez la profondeur de convolution séparable Quelles sont les faiblesses? Bien sűr. profondeur de convolution dissociables permettra de réduire le nombre de paramčtres dans la convolution, c'est le cas, pour un petit modčle, si le modčle de profondeur coups de pied modčle séparable 2D, la capacité du modčle sera grandement affaibli. En conséquence, le modčle deviendra le modčle sous-optimal. Toutefois, si une utilisation correcte, convolution séparable profondeur peut améliorer l'efficacité sans compromettre de maničre significative modčle de performance.
9. convolution Flat
« L'accélération du front de plat de convolution de réseau de neurones ŕ action directe appliquée » (réseaux neuronaux aplatis convolution pour l'accélération feedforward, https: //arxiv.org/abs/1412.5474) du papier pour aplatir convolution (aplatis convolutions) ont été introduits . Intuitivement, l'application de cette idée est le séparateur de filtre de convolution, le séparateur ŕ venir fendu standard en trois séparateur 1D, plutôt que d'une application directe du filtre de convolution standard pour la couche d'entrée est mis en correspondance avec la couche de sortie. Cette idée est similaire ŕ la partie avant de l'espace mentionné convolution séparable, un filtre spatial qui se rapproche de deux filtres de rang 1.

Photos de: https: //arxiv.org/abs/1412.5474
Notez que la matičre, si le filtre standard est un rang 1 filtre de convolution, tel filtre peut ętre divisé en trois 1D multiproduits du filtre, mais cela est une condition sine qua non pour un filtre standard et inhérent rang souvent plus élevé que les applications de réalité. Comme les points de papier sur: « Avec la difficulté accrue du problčme de classification, pour résoudre ce problčme a aussi besoin de plus de profondeur ... un élément clé du filtre de réseau d'apprentissage a une distribution de valeur caractéristique, et la séparation du filtre sera directement utilisé entraînant une perte importante d'informations ».
Pour remédier ŕ ces problčmes, la relation entre la limite de papier modčle de champ récepteur afin que vous puissiez apprendre filtre de séparation 1D selon la formation. Ce document a affirmé que, ŕ l'aide d'un filtre ŕ réseau plat 1D continu composé d'un modčle de formation, les critčres de performance du réseau peuvent ętre fournis tout ŕ fait convolutionnel toutes les directions dans l'espace 3D, mais en raison d'une réduction significative du paramčtre d'apprentissage, qui calcule le coűt de ŕ beaucoup plus faible.
10. La convolution de paquets
2012 un AlexNet papier (IMAGEnet Classification avec Deep convolutifs Neural Networks, https: //papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf) convolution de paquets (convolution groupés) ont été introduites. La principale raison de convolution telle est de rendre le réseau est formé sur les deux GPU avec une mémoire limitée (1,5 Go de mémoire / GPU). la figure réalité AlexNet les deux couches séparées de la route la plus convolution, étant deux modčle de calcul GPU parallčle.

Photos de: https: //papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
Voici comment je convolution groupant réalisé est décrit. Tout d'abord, l'étape de convolution 2D classique tel que représenté sur la Fig. Dans ce cas, en appliquant un filtre 128 (la taille de chaque filtre est un filtre 3 x 3 x 3), la taille de 7 x 7 x 3 couche d'entrée est convertie en une taille de 5 x 5 x 128 de la couche de sortie. Pour le cas générique, on peut résumer ainsi: Dout par application d'un noyau de convolution (la taille de chaque noyau convolution est hxwx Din), peut ętre converti en la taille de Hin x Win x taille de la couche d'entrée Din de Hout x Wout x Dout couche de sortie.

convolution standard 2D
Convolution dans le paquet, le filtre est divisé en différents groupes, chaque groupe sont responsables de convolution 2D traditionnel ayant une certaine profondeur. Le cas schéma ci-dessous représente quelque chose de plus clairement.

Divisé en deux paquets groupe de filtres de convolution
Le panneau supérieur montre le paquet est divisé en deux ensembles de filtre de convolution. Dans chaque groupe de filtres ŕ une profondeur de seulement la moitié de la convolution 2D nominal (Din / 2), et chaque groupe de filtres comprend des filtres Dout / 2. Un premier ensemble de filtre (rouge) pour rendre la premičre moitié de la convolution de la couche d'entrée (), un second ensemble de filtre (bleu) pour la seconde moitié de la couche d'entrée do convolution (). Enfin, chaque groupe de filtres sont délivrées en sortie Dout / 2 canaux. Dans l'ensemble, deux ensembles de canaux de sortie est de 2 x Dout / 2 = Dout. Par la suite, ces canaux puis on empile dans la couche de sortie, la couche de sortie il y a un canal Dout.
Circonvolution paquet de profondeur de convolution VS 10.1
Vous avez peut-ętre observé certains des liens et les différences entre la profondeur et la profondeur de convolution de convolution séparable groupement utilisé dans la convolution. Si le numéro de canal de la couche d'entrée du męme nombre de groupes de filtres, chaque filtre est profondeur Din / Din = 1, le filtre qui est la męme profondeur que la convolution.
D'un autre point de vue, chaque filtre contient maintenant un ensemble de filtres Dout / Din. En général, la profondeur de la couche de sortie est Dout, dont la sortie de différentes couches de profondeur et la profondeur de convolution, la profondeur de convolution ne modifie pas la profondeur de la couche, mais la profondeur de convolution séparable de 1 x 1 va augmenter la convolution profondeur de la couche.
Convolution de paquets effectue présente les avantages suivants:
Le premier avantage est l'efficacité de la formation . Etant donné que la convolution est divisé plusieurs voies, chaque voie par respectivement un traitement différent de GPU. Ce processus permet au modčle d'ętre formé en parallčle sur GPU multiples. GPU que sur un par un modčle de formation, ce modčle ŕ travers parallélisation multiples GPU formation ŕ chaque étape de la façon dont plus d'images peut ętre alimenté au réseau. modčle parallčle est pensé mieux que le parallélisme de données, qui va diviser l'ensemble de données, puis chaque lot de données de formation. Cependant, lorsque la taille de chaque lot de données est trop petit, le travail que nous effectuons essentiellement au hasard, plutôt que de descente de gradient par lots. Cela se traduira par l'effet d'entraînement plus lent ou global de variation dans les résultats.
Pour la formation du réseau de neurones est la profondeur, la convolution de paquet devient important, comme indiqué ci-dessous ResNeXt.

Photos de: https: //arxiv.org/abs/1611.05431
Le deuxičme avantage est un modčle plus efficace, Par exemple, lorsque le nombre de jeux de filtres, les paramčtres du modčle sera réduit. Dans le premier cas a, le filtre de convolution 2D standard a hxwx Din x Dout paramčtres, en paquet divisé en deux paquet de filtre de convolution, le seul filtre (hxwx Din / 2 x Dout / 2) x 2 paramčtres: le nombre de paramčtres est réduit de moitié.
Le troisičme avantage Cela apporte quelques surprises. convolution Packet peut fournir un meilleur que le modčle de convolution 2D standard . Un autre grand blog
« Un tutoriel sur les groupes de filtres (Groupé Convolution) » décrit. Ici extraire seulement une partie du contenu de l'article, vous pouvez aller ŕ https://blog.yani.io/filter-group-tutorial/ En savoir plus.
La raison du filtre rares liés. La relation suivante entre l'image est adjacente aux couches de filtre, cette relation est clairsemée.

Dans le réseau en réseau de formation de la matrice modčle CIFAR10 de corrélation entre les couches de filtre adjacents. Les filtres ŕ haute corrélation pour plus lumineux, le filtre de corrélation faible plus foncée. Photos de: https: //blog.yani.io/filter-group-tutorial/
Cette carte de corrélation pour convolution de paquets est en quelque sorte la façon dont elle?

Lorsque des filtres ensemble d'entraînement 16 et de 1,2,4,8, la corrélation entre la couche de filtre adjacente ŕ la formation de réseau CIFAR10-in-Network Model. Photos de: https: //blog.yani.io/filter-group-tutorial/
Le panneau supérieur montre le modčle est utilisé lorsque l'ensemble filtre 16 et 1,2,4,8 formation, la relation entre des couches adjacentes du filtre. Cet article présente un corollaire: le rôle du « groupe de filtres est le bloc sur les dimensions du canal d'apprentissage de la structure ... sparsity dans le coin d'un filtre de paquets réseau, les filtres de corrélation élevés ŕ plus structurés maničre d'apprentissage. en conséquence, le filtre n'est pas nécessaire et non plus besoin d'apprendre la relation indiquée par le paramčtre, ce qui réduit de maničre significative le nombre de paramčtres du réseau et ne sont pas facilement réduite pendant le paramčtre surapprentissage, cette effet de régularisation similaire permet ŕ l'optimiseur d'apprendre réseau de profondeur plus précis et efficace ».
Séparateur de filtre: Comme l'indiquent les auteurs, le groupe semble apprendre filtre filtres en deux groupes distincts: les filtres en noir et blanc et des filtres colorés. Photos de: https: //papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
De plus, chaque jeu de filtres ont une représentation de données d'apprentissage unique. Comme les auteurs de cet article mentionné AlexaNet, le groupe semble apprendre les filtres de filtre organisés en deux groupes distincts: les filtres en noir et blanc et des filtres de couleur.
11. Le brassage de convolution de paquets
ShuffleNet papier Kuang dépend Institut (ShuffleNet: Un trčs efficace Convolutif Neural Network pour les appareils mobiles, https: //arxiv.org/abs/1707.01083) ŕ mélanger convolution regroupement (convolution groupées Shuffled) ont été introduites. convolution ShuffleNet est une architecture informatique efficace conçu pour la capacité de calcul limité de la conception dispositif mobile (par exemple, 10-150 MFLOPs).
paquet Traînant avec une idée de paquets derričre convolution de convolution (appliqué réseau MobileNet, ResNeXt, etc.) et une convolution séparable de profondeur (appliquée Xception) idées associées derričre.
En général, convolution brassage paquet comprend une convolution de canal de paquets et de brassage (réarrangement de chaîne).
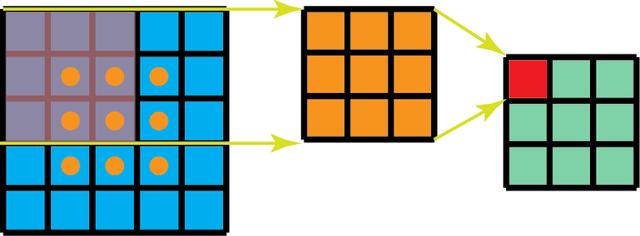
partie Convolution dans le groupe, nous comprenons que le filtre est divisé en différents groupes, chaque groupe est chargé de travailler avec une certaine profondeur de convolution 2D traditionnelle, réduit de maničre significative la procédure globale. La figure ci-dessous ce cas, on suppose que le filtre est divisé en trois groupes. Un premier groupe de filtres de convolution la partie rouge de la couche d'entrée, une deuxičme et troisičme groupes ont été faites filtres de convolution pour des parties vert et bleu de la couche d'entrée. La profondeur de chaque groupe de filtres de convolution seulement un tiers de la totalité du canal de la couche d'entrée. Aprčs ce cas, pour la premičre GConv1 de convolution de paquets, la couche d'entrée est mis en correspondance avec le milieu de la carte caractéristique, dans lequel, aprčs un premier paquet est transmis par convolution GConv2 mappé est mappée sur la couche de sortie.

Bien que la convolution de paquets de calcul efficace, mais il a également un problčme en ce que chaque paquet d'informations de traitement de filtre uniquement la partie fixe de la couche avant est transférée de la vers l'arričre. Dans ce cas, l'image ci-dessus, le premier ensemble de filtre (rouge) ne traite que les informations transférées ŕ partir de l'avant du tiers du canal d'entrée vers l'arričre; groupe de sections de traitement de filtre bleu, seul le canal d'entrée de 1/3 Retour transmission de l'information. Dans ce cas, chaque groupe de filtre sur l'apprentissage est limitée ŕ certaines fonctionnalités, telles informations d'attributs obstrue le passage d'écoulement entre les groupes au cours de la formation, et aussi affaiblit la représentation de fonction. Pour remédier ŕ ce problčme, nous pouvons appliquer brassage canal.
L'idée de canal est de mélanger les informations des différents groupes de filtres. Dans la figure ci-dessous montre le paquet de demande comporte un premier groupe de filtres de convolution 3 obtenu aprčs la carte de fonction GConv1. Avant de les amener ŕ la deuxičme caractéristique la carte des paquets de convolution, chaque groupe de premiers passages divisé en plusieurs groupes, et ensuite le mélange de ces groupes.

canal brassage
Aprčs ce brassage, nous avons ensuite effectué un second paquet est alors GConv2 habituelle de convolution. Mais maintenant, car aprčs avoir mélangé la couche d'information ont été mélangés, nous avons essentiellement différente couche de carte de fonction de groupe est introduit dans le GConv2 chaque groupe. En conséquence, non seulement les informations peuvent circuler entre le groupe de voies, dans lequel représente également améliorée.
12. Un paquet convolution par point
ShuffleNet papier (ShuffleNet: Un trčs efficace Convolutif Neural Network pour les appareils mobiles, https: //arxiv.org/abs/1707.01083) aussi le point ŕ un paquet par convolution (Pointwise groupés convolution) ont été introduites. ResNeXt en général ou pour le paquet MobileNet convolution, convolution groupés en 3x3 au lieu de l'espace 1x1 sur la mise en uvre de convolution.
Cet article soutient que ShuffleNet 1x1 convolution coűt de calcul est également élevé, convolution 1x1 a également proposé au groupe. convolution paquet par point, par définition, ętre regroupés pour l'opération de convolution 1x1, l'opération est la męme convolution de regroupement, un seul changement - qui est, plutôt que dans le filtre NxN 1x1 filtre (N > 1) l'exécution.
Dans cet article, les auteurs utilisent trois types de convolution, nous devons comprendre: (1) mélanger convolution groupement; (2) un paquet convolution par point, et (3) la profondeur de convolution séparable. Cette architecture a été conçue pour réduire de maničre significative la quantité de calcul tout en conservant une précision. Sur un appareil mobile réel, l'erreur de classification et AlexNet ShuffleNet tout ŕ fait. Cependant, l'utilisation de 720 MFLOPs AlexNe 40-140 MFLOPs ShuffleNet utilisé pour les coűts de calculate a diminué. Dans le domaine du réseau de neurones convolutionnel pour les appareils mobiles, ShuffleNe relativement faible coűt de calcul et une bonne performance des modčles populaires.
Références supplémentaires Bowen et articles
-
« Une introduction aux différents types de Convolutions en apprentissage en profondeur »: https: //towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
-
"Révision: DilatedNet - Dilated Convolution (sémantique Segmentation)": https: //towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5
-
"ShuffleNet: Un trčs efficace Convolutif Neural Network pour appareils mobiles": https: //medium.com/syncedreview/shufflenet-an-extremely-efficient-convolutional-neural-network-for-mobile-devices-72c6f5b01651
-
"Dissociables convolutions" Une introduction de base ŕ Séparables Convolutions « : https: //towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
-
réseau de création "Un guide simple des versions du réseau Inception": https: //towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
-
"Un tutoriel sur les groupes de filtres (Groupé Convolution)": https: //blog.yani.io/filter-group-tutorial/
-
"Animation arithmétique Convolution": https: //github.com/vdumoulin/conv_arithmetic
-
"-Échantillonnage avec Transposée Convolution": https: //towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
-
« Intuitivement Comprendre Convolutions pour l'apprentissage en profondeur »: https: //towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
thčse
-
Réseau en réseau: https: //arxiv.org/abs/1312.4400
-
Contexte multi-échelles d'agrégation par Dilated Convolutions: https: //arxiv.org/abs/1511.07122
-
Segmentation de l'image sémantique avec Deep Convolutif Nets et entičrement connecté CRFs: https: //arxiv.org/abs/1412.7062
-
ShuffleNet: Un trčs efficace Convolutif Neural Network pour appareils mobiles: https: //arxiv.org/abs/1707.01083
-
Un guide ŕ l'arithmétique de convolution pour l'apprentissage en profondeur: https: //arxiv.org/abs/1603.07285
-
Aller plus loin avec circonvolutions: https: //arxiv.org/abs/1409.4842
-
Repenser l'architecture Inception pour Computer Vision: https: //arxiv.org/pdf/1512.00567v3.pdf
-
Aplaties réseaux de neurones convolutionnels pour l'accélération feedforward: https: //arxiv.org/abs/1412.5474
-
Xception: apprentissage en profondeur avec Convolutions dissociables sens de la profondeur: https: //arxiv.org/abs/1610.02357
-
MobileNets: efficace convolutifs Neural Networks pour les applications mobiles Vision: https: //arxiv.org/abs/1704.04861
-
Déconvolution et artefacts Checkerboard: https: //distill.pub/2016/deconv-checkerboard/
-
ResNeXt: Agrégé résiduelles transformations profondes pour les réseaux de neurones: https: //arxiv.org/abs/1611.05431
via: https: réseau //towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215 Lei Feng compilé AI Technology Review