

Résumé: FFT convolution est maintenant largement utilisé dans le traitement du signal numérique, et au cours des derničres années confirme le développement du systčme programmable multi-core hétérogčne (HMPS) de. De plus, HMPS est devenu une tendance dominante dans le domaine DSP. Par conséquent, l'étude sur HMPS gros point FFT a mis en uvre de maničre efficace est convolution trčs important. Procédé de convolution de chevauchement-addition ŕ base de FFT, conçue pour un débit élevé de données d'entrée des flux de chevauchement-ajout filtre. HMPS introduit un grand point FFT basée la mise en uvre convolutionnel de l'effet de filtrage est obtenu avec une grande précision. De plus, avec les techniques de conception de filtre ŕ eau, afin d'améliorer la vitesse de traitement du systčme, le parallélisme des tâches et du débit de données. Sur la base de la carte expérimentale de développement FPGA Xilinx XC7V2000T ont montré que plus les points d'échantillonnage impliqués dans le calcul, seront plus élevés parallélisme des tâches du systčme, le traitement des données de vitesse et de débit. Lorsque le point d'échantillonnage a atteint 1 M, moyenne du systčme de parallélisme des tâches a atteint 5,33, le nombre de cycles d'horloge consommé 2.745 × 106 systčmes, et la précision de l'erreur absolue 10-4.
format de citation chinois: Zhang Victoria, Hugh Shen Lei, Song Yu Kun, et d'autres gros point FFT convolution hétérogčne conception de systčmes programmables multi-core et mise en uvre Technologie électronique, 2017,43 (3): 16-20.
Anglais format de citation: Zhang Duoli, Shen Xiulei, Song Yukun, et al. Conception et mise en uvre d'une grande convolution FFT sur le systčme programmable multi-curs hétérogčnes . App lication de la technique électronique, 2017,43 (3): 16-20.
0 introduction
Dans le domaine du traitement numérique du signal, réponse impulsionnelle flux de données de l'opération de convolution du filtre récepteur largement adapté, les communications numériques, le traitement d'image et le filtre passe-bande de signal de réception dans le radar. Procédé FFT de convolution pour convertir convolution linéaire sur le domaine de fréquence en utilisant le processeur de FFT efficace, il est efficace pour les algorithmes de traitement de flux de données, une haute vitesse de traitement de données, mais ŕ faible débit de données. Afin de traiter le flux de données en utilisant la méthode de convolution FFT, un processeur FFT doit ętre multiplexé, afin de maintenir la vitesse de traitement de synchronisation et le débit.
Avec le développement rapide de la technologie des semi-conducteurs, HMPS IC est devenue la principale tendance, et la technique de traitement du matériel deviennent les plus prometteurs dans de nombreuses applications. Ainsi, dans les flux de données sur les processus de remplissage nul, une opération de convolution dans la FFT grand point, ces HMPS données intensives ętre la meilleure solution et des tâches de calculs. Pour obtenir une vitesse de traitement élevée et le débit, sur la base NoC HMPS reliés entre eux, qui profitent de la puissance de traitement parallčle, a une bonne extensibilité et une faible consommation d'énergie.
Grand point de mise en uvre convolution FFT nécessite un grand nombre de calculs complexes, la conception du filtre de goulot d'étranglement. Cela introduit en papier et un grand principe de fonctionnement de convolution FFT point sommaire et la méthode de dérivation, d'autre part, HMPS architecture du systčme d'affichage et systčme de cartographie de l'algorithme détaillé; Enfin, les paramčtres de performance du systčme, y compris le résultat de la comparaison de l'erreur, le degré des tâches du systčme de parallélisme, la consommation des ressources matérielles et la cible et la direction pour améliorer les performances du systčme pour .
Un algorithme de chevauchement-add principe
Comme représenté sur la. Figure 1, la convolution FFT de chevauchement-addition est échantillonnée en séquence des segments de données ayant une longueur L et analogues. Supposons que les coefficients de prise h (n) de longueur N, la séquence d'échantillons x (n) est infinie, la séquence x (n) de la portion aliquote de L de segments de données de croissance, comme le montre l'équation (1):


Ensuite, la séquence h (n) et x (n) dans le résultat FFT du filtrage de convolution est défini comme suit:

Dérivé de (2) et (3) le calcul de la convolution grand point FFT, d'une part, le calcul des fragments linéaires de segment de yk de convolution (n), alors la portion des fragments de segment de résultats de convolution en ajoutant , par rapport ŕ un résultat filtré finale y (n).
Pour éviter les effets de crénelage, la longueur M de la réponse impulsionnelle du filtre, la séquence de chaque segment est ajouté aprčs le M-10, tandis que la conversion du domaine temporel dans la convolution dans le domaine fréquentiel est multiplié, dans la séquence de N échantillons dans DFT dans lequel NL + M-1, par la formule (4) dans le domaine fréquentiel résultat filtrage peut ętre obtenu:

Oů H (k) une réponse de domaine de fréquence du filtre, X (k) et Y (k) représente la séquence de l'échantillon et la réponse de domaine de fréquence du résultat du filtrage. Aprčs la séquence et la séquence de segments dans le domaine des fréquences en multipliant la réponse impulsionnelle dans le null-remplissage, chaque segment inverse résultat filtrage opération FFT, et enfin dans le domaine temporel, une partie arričre supérieure du point M-1 inférieur un M-1 segment du point avant chevauchement additionner le résultat filtré final.
2 plateforme Noc-HMPS
HMPS systčme multi-programmable hétérogčne principalement utilisé dans les calculs de haute densité, le systčme est conçu non seulement pour satisfaire un certain type de fonctionnement particulier, mais a aussi une certaine polyvalence.
Comme représenté sur la. Figure 2, une architecture de systčme ŕ base HMPS 7 × 6 structure de réseau 2D maille ayant un noeud de ressource 22, les opérandes et les informations de contrôle d'état passé ŕ travers le réseau de communication. En męme temps, les types de noeuds de ressources d'intégration de systčmes multi-core sont: les clusters Flash, le contrôleur principal de cluster (contrôleur principal cluster), port Ethernet cluster (Ethernet Port cluster), réseau ŕ trois niveaux, groupe DDR3 de 4 Go et trois types d'opérations ŕ virgule flottante cluster unité. Le systčme est 32 bits ŕ virgule flottante unité coprocesseur groupe principal (COP Cluster), groupe de moyens de calcul reconfigurable (RCU Cluster) et les clusters FFT / IFFT répondre ŕ la norme IEEE-754 ŕ virgule flottante ŕ simple précision. Chaque noeud de ressource plate-forme de NoC ŕ chaque paquet de demande d'état de transfert ayant un état du réseau, pour fournir le réseau de transmission de paquets de données de configuration et un réseau d'échange d'informations de configuration de circuit (PCC). La tâche est en cours d'exécution, tous les nuds doivent satisfaire aux ressources sur le mécanisme de communication de réseau et la principale puce de contrôleur pour gérer l'ordonnancement des tâches co-traitement, jouer les avantages des systčmes de haute performance.

2.1 groupe flash
Aprčs la remise ŕ zéro du systčme, le durcissement par des informations de configuration du cluster Flash pour compléter le guide HMPS initialisation des tâches du systčme.
2.2 hôte cluster contrôleur
DDR en demandant des informations de configuration, la configuration du cluster impliqués dans la tâche, transmet le message de demande de données / réponse, envoyé tâche DDR reçoit des informations de commutation, la commutation de tâches, le systčme pour terminer la planification des tâches.
2.3 cluster port Ethernet
L'échange de données entre le logiciel PC et puce FPGA, les informations de configuration du systčme délivrant des opérations de la mission et renvoyer les données originales et les données de résultats de calcul, cluster port réseau est un moyen nécessaire HMPS débogage.
2.4 réseau ŕ trois niveaux
Par le réseau de PCC, la configuration du réseau et l'état du réseau de 7 × 62D configuration de réseau maillé, le systčme de transmission de données et d'informations de commande. réseau de transmission de données formée en reliant le noeud de routage de réseau PCC PCC, seule voie de transmission de données. Configurer la configuration du réseau est faite et que les informations de chemin ŕ la demande de données vers l'avant. État de la demande de données de téléchargement de réseau / réponse uniquement des informations de chemin.
2,5 groupe DDR3
DDR3 contrôleur d'écriture capable de traiter la requęte de contrôle des noeuds de ressources, et la tâche impliquée dans la configuration du systčme d'information, les données brutes, les résultats intermédiaires et des données immédiates et analogues sont stockées dans la 4 GB DDR3.
2.6 pôle FFT / IFFT
32 bits FFT capacité de virgule flottante / cluster IFFT peut prendre en charge 16K points FFT et FFT inverse, a une architecture particuličre de deux unités de calcul papillon capable de fonctionner en męme temps, et par conséquent, le point 16K FFT et FFT inverse ne nécessite que le cycle d'horloge du systčme 56.3K .
2.7 cluster RCU
32 groupes de bits RCU capacité en virgule flottante et un traitement principal structuré opération de nombre réel complexe, y compris les multiplications complexes réels entre les quantités d'addition et de soustraction, etc. . L'unité de traitement est constitué de deux multiplieurs et deux additionneurs, ayant des caractéristiques reconfigurables, il est possible de traiter de grandes quantités d'opérations de données. En męme temps, capable de supporter deux modes de données de fonctionnement: le mode de stockage et un mode de flux.
groupe 2,8 COP
Satisfaire la simple précision IEEE-754 clusters norme ŕ virgule flottante COP est principalement contrôlée par la programmation de logiciels irréguličre complexes ŕ virgule flottante, nombre réel opération arithmétique, y compris le complexe, le nombre réel entre l'addition, soustraction, multiplication, division, racine carrée, etc. < 7>. l'architecture SIMD coprocesseur ŕ base de micro flamber employé comme l'unité de commande, via le point flottant matériel de commande de bus FSL coprocesseur IP. tâches systčme de cluster de COP impliqués dans le contrôle principalement les données reçues, et la transmission des résultats de l'unité de traitement opération de corrélation correspondant ŕ la programmation du logiciel SDK.
3 gros point cartographie algorithme de convolution FFT
Dans cet article, les coefficients de prise font 1K + 1 h (n) et le nombre d'échantillons de 16K points de x (n), par exemple, pour vérifier la méthode de zéro de remplissage et de chevauchement-addition, comme le montre la Fig.

Le null-remplissage et le chevauchement par la méthode d'addition d'eau, en divisant les points d'échantillonnage dans 16K segments 16 longue 1K autre groupe, afin d'éviter les effets de repliement de spectre, tous les segments et les fragments et les coefficients de prise sont ajoutés 1K-11K point zéro séquences, converti en une longueur uniforme 2K pour compléter la convolution FFT segments respectifs par le segment de noeud de ressource de systčme. Afin d'améliorer la vitesse de traitement et la pleine utilisation des avantages de HMPS haute performance, tous les échantillons ŕ la fréquence de conversion de domaine ŕ travers le domaine et puis, les clusters informatiques tels que tout systčme informatique parallčle est capable de participer ŕ l'eau, afin d'améliorer le parallélisme des tâches du systčme.
. La figure 4 (a),. La figure 4 (b) et 4 (c), comme illustré, l'algorithme de convolution 16K FFT cartographier le point d'échantillonnage en quatre sous-tâches (Task0, Task1, Task2 et Task3). Dans le graphe de flux de données suivant (DFG), l'unité ŕ virgule flottante 18 systčme intervenant dans l'exécution des tâches.
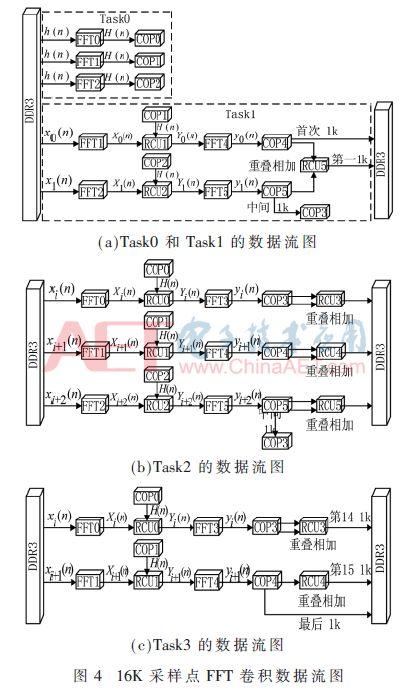
. La figure 4 (a), la tâche spéciale par Task0 FFT0, FFT1 et FFT2 grappes pour calculer la réponse en fréquence des coefficients de prise, stockés et COP0, COP1 de la grappe et l'unité de stockage de feuilles de COP2. Dans la tâche suivante, ils sont transmis ŕ RCU0, RCU1 et cluster RCU2, et ajouter zéro fragments de segments de séquence font multiplication par lots dans le domaine de fréquence.
Avant que les échantillons principaux 2K TASK1 de calcul, les résultats obtenus avant de filtrer 2K points, l'unité de stockage stocke la feuille intermédiaire grappes COP3 de COP5 de cluster 1K résultat filtré pour le prochain pipeline d'opération d'ajout de chevauchement.
. La figure 4 (b) comme indiqué, en utilisant quatre architecture informatique parallčle pipeline de circulation Task2, tous les nuds sont impliqués dans les ressources d'exécution des tâches, en théorie, pour atteindre le maximum. FFT0, FFT1 FFT2 et de l'eau de chaque groupe ont été calculées en réponse ŕ chaque point dans le domaine fréquentiel 2K, RCU0, les clusters RCU1 de RCU2 sont mis en uvre et des coefficients de prise et de chaque multiplication de points d'échantillonnage en vrac dans le domaine des fréquences, FFT3, FFT4 et des grappes par inversion FFT5 opération FFT dans le domaine fréquentiel en domaine temporel résultat de filtrage, sont transmises ŕ la COP3, des grappes de CdP4 et COP5 Enfin RCU3, les clusters RCU4 de RCU5 et deux sections longitudinales pour réaliser les segments de résultat se chevauchent et ajouter filtre 1K points, pour donner un résultat filtré finale et stockés dans un cluster DDR3.
Dans la derničre tâche Task3, le filtre primaire pour atteindre un point de l'échantillon final 2K, 3K filtrer le résultat est écrit ŕ grappe DDR3, comme représenté sur la Figure 4 (c). Jusqu'ŕ présent, ŕ travers quatre tâches pour réaliser l'opération de convolution FFT point 16K en HMPS dans.
Dans le schéma de mappage de l'algorithme ci-dessus par des grappes DDR3 ŕ des informations de configuration du magasin impliqués dans l'exécution des tâches, les données d'échantillon originales et le résultat de filtrage, le noeud FFT et grappe RCU impliqués dans le processus de calcul, en utilisant COP0, l'unité de stockage des grappes de COP1 et COP2 de feuilles stocke filtre coefficient de réponse de domaine de fréquence en utilisant COP3, CdP4 et cluster COP5 pour recevoir des données d'émission au RCU3 résultat intermédiaire correspondant, des grappes de RCU4 RCU5 et addition-recouvrement obtenue. Comme on peut le voir ŕ partir de la DFG, groupe de COP impliqué dans l'exécution des tâches simplement pour recevoir et transmettre les données intermédiaires, la tâche ne participe pas ŕ l'opération proprement dite, et tout le cluster de calcul de FFT et RCU de corrélation impliquée dans l'ensemble de la tâche, et donc, le systčme maximum théorique le parallélisme des tâches est 12.
Le mécanisme de communication et réseau HMPS sur le cluster ŕ virgule flottante ŕ puce dans le schéma de mise en correspondance de convolution FFT efficace, un grand point du systčme est plus pratique que l'architecture de conception traditionnelle, un fonctionnement souple et plus efficace.
4 Analyse des performances du systčme et des résultats
Dans Xilinx XC7V2000T carte de développement FPGA, la fréquence d'horloge du systčme est réglé sur 100 MHz et testé pour vérifier, et ŕ travers l'interface réseau et les clusters de logiciels PC les résultats des données au PC local.
Par le résultat du calcul avec le logiciel Matlab HMPS vu du résultat de la comparaison de l'erreur de traitement, en raison de la grande convolution point FFT accumulé Calcul de la fermeture d'erreur par rapport ŕ zéro, par conséquent, la méthode de l'erreur absolue systčme donné, tel que la formule (5):

Le tableau 1 montre le point d'échantillonnage est de 64 K et M 1, et la consommation de l'horloge du systčme systčme moyen de parallélisme de tâches correspondant, dans lequel, Aerr_imagmax Aerr_realmax et représente la partie réelle et la partie imaginaire de l'erreur absolue maximale. parallélisme moyenne des tâches est calculé comme suit:

Dans lequel, les grappes représente le degré de parallélisme, la consommation d'horloge Tclusters représente le degré de parallélisme des clusters, T représente une consommation d'horloge de la mission.
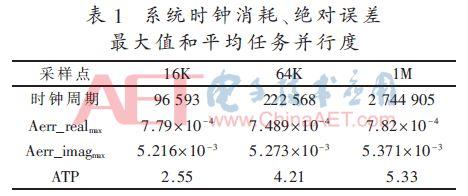
Dans le schéma de cartographie ci-dessus, les points 64K et 1M besoin de modifier uniquement le nombre de cycles d'autres Task2 restent inchangés. Le null-remplissage et le chevauchement-addition en moyenne de 16K points cycles de fonctionnement convolution FFT eau cinq fois, et les points de 64K et 1M sont nécessaires en utilisant 21 fois et 341 fois l'opération de cycle de l'eau.
A partir du tableau 1 peut ętre déduit des résultats expérimentaux, plus les points d'échantillonnage qui participent au fonctionnement du systčme, plus moyen de parallélisme des tâches du systčme, et l'erreur absolue maximale proche 10-4, par rapport ŕ hétérogčne unité de traitement multi-documents dans l'erreur relative de 10-3, le systčme actuel a une plus grande précision. Par rapport ŕ la littérature hétérogčne ŕ plusieurs SoC est (ATP qui atteint au maximum 3,88), ce modčle peut atteindre 5,33, qui a une vitesse de traitement plus élevée et le systčme d'attribution des tâches en moyenne, plus le nombre de points d'échantillonnage, plus l'effet.
Dans HMPS Xilinx XC7V2000T conseil de développement de la consommation des ressources matérielles, comme indiqué dans le tableau 2.

5. Conclusion
Dans de nombreuses applications, gros point FFT Convolution est nécessaire de briser le goulot d'étranglement technique, ce qui réduit le temps de calcul et d'améliorer l'efficacité opérationnelle et de filtrer l'exactitude des résultats est importante. Cet article permet la cartographie efficace des gros point convolution FFT HMPS programme de 2M, 4M, męme des échantillons plus grands peuvent facilement ajouter des cycles de l'eau par la méthode de cartographie ci-dessus pour mettre en uvre et ne nécessite pas des ressources matérielles supplémentaires la consommation.
Notez également que, pour améliorer les performances du systčme et le parallélisme des tâches nécessite en męme temps pour toutes les opérations impliquées dans les tâches de calcul du cluster. outils de papier le coefficient de prise 1K + 1 point robinet coefficient autre longueur appropriée peuvent ętre utilisées. En tant que systčme de processeur ŕ usage général, HMPS principalement utilisé dans le calcul de haute densité, peut ętre mis en uvre d'autres calculs complexes.
Grâce ŕ l'analyse expérimentale montre que les performances du systčme est beaucoup de place pour l'amélioration, afin d'obtenir des données plus le débit, la vitesse de traitement, et le parallélisme des tâches, le temps de communication peut ętre réduite en améliorant le réseau sur puce et en augmentant la bande passante efficace pour augmenter les données débit DDR et ainsi de suite, il a une grande importance.
références
CHEN F Y, ZHANG D S, Z WANG Y.Research de l'hétérogčne conception de l'architecture de processeur multi-core .Com puter Engineering & Science, 2011,33 (12): 27-36.
J REN, IL Y, XUN C Q, et procédé matériel / logiciel al.A pour des noyaux hétérogčnes coopérant sur l'architecture de flux .Chinese Journal des ordinateurs, 2008,31 (11): 2038-2046.
Hou Ning, Lu Yapeng, Zhang Duoli .Com solution munication de multi-core chipset basé sur NoC .Com PUTER Era, 2014 (10): 17-18.
W LEI, Xiao M, RUI X.Study sur un systčme de test en parallčle basé sur multiconducteur .Journal de Xian Jiaotong University, 2008,42 (6): 683-687.
LI J, J MARTINEZ considérations F.Power performance de calcul parallčle sur multiprocesseurs ŕ puce .ACM Transactions sur l'architecture et l'optimisation du code (TACO), 20052 (4): 397-422.
Wang Xing, Zhang Duoli, Song Yukun, et al.Design et la mise en oeuvre d'une réduction ŕ virgule flottante reconfigruable unité de calcul .International Conférence sur l'ordinateur, la sécurité des réseaux et ingénierie de la communication (CNSCE), 2014.
HAN Z F, LI J S, PAN H B, et al.Design de vecteur ŕ virgule flottante coprocesseur basé sur FPGA .Com puter ingénierie, 2012,38 (5): 251-254.
ZHANG D, ZHANG Y, la mise en uvre SONG Y.Procédé de grande FFT sur le systčme ŕ noyaux multiples homogčne .Solid-État et de la technologie Circuit intégré (ICSICT), 201412e Conférence internationale IEEE on.IEEE, 2014: 1-4.
SONG Y, R JIAO, ZHANG D, analyse et al.Performance de matrice multiplication basé sur un SoC multicoeurs hétérogčnes .ASIC (Asicon), 2015 IEEE 11e Conférence internationale on.IEEE, 2015: 1-4.
Informations Auteur
Zhang Victoria, Hugh Shen Lei, Song Yu Kun, Du Gaoming
(Hefei Université de technologie, l'Institut de Design Microelectronics, Hefei 2 30 009)

