Le contenu principal sont les suivantes:
- statut en temps rťel de la seule plate-forme de produits
- la pratique Flink seulement la volontť du produit
- Flink Sur K8S
- Planification de la relŤve
Tout d'abord, le statut sera le seul produit est actuellement une plate-forme en temps rťel cadre informatique unifiťe dans les produits CD sera plate-forme en temps rťel, mais comprend Storm, Spark, Flink, y compris les trois principaux cadre informatique. Pour des raisons historiques, le nombre d'emplois actuellement sur la plate-forme Storm est le plus grand, mais depuis l'annťe derniŤre, l'accent d'affaires mis progressivement ŗ Flink ci-dessus, il a ťtť une augmentation substantielle du nombre de demandes cette annťe Flink ci-dessus.
Les grands panneaux d'affichage promotion des indicateurs statistiques, y compris les diffťrentes dimensions (par exemple, des recommandations en temps rťel en tant que fournisseur clť de l'ťlectricitť d'affaires, plus de fonctionnalitťs en temps rťel comprennent :: diverses dimensions de l'ordre, les UV, les taux de conversion, l'activitť de la plate-forme ŗ temps rťel entonnoir noyau se compose de huit parties etc.), pour la direction, les opťrations, les dťcisions de ce produit ŗ l'utilisation, le nettoyage des donnťes en temps rťel, enterrť ŗ partir du point d'utilisateur des donnťes collectťes, nettoyťes et associť en temps rťel, fournir de meilleures donnťes pour chacune des activitťs en aval, en plus des services bancaires d'Internet, la sťcuritť du vent contrŰle, et les amis de paritť et d'autres services, ainsi que Logview, Mercure, Titan servant de systŤme de contrŰle interne, les systŤmes de synchronisation de donnťes VDRC en temps rťel.
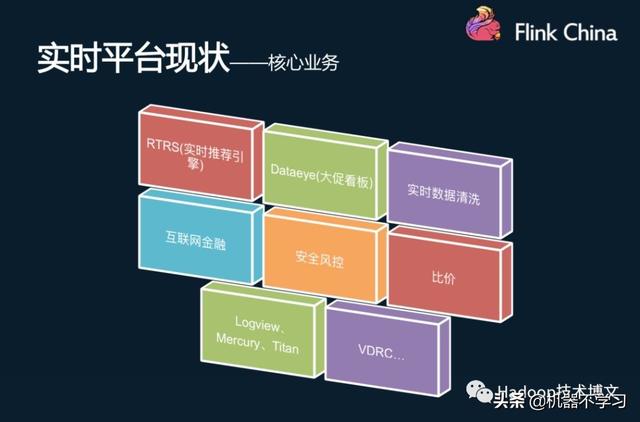
Les responsabilitťs comprennent la plate-forme en temps rťel pour les plates-formes de calcul en temps rťel et la base de donnťes en temps rťel. plate-forme de calcul en temps rťel sur la base du cadre de calcul TempÍte, Spark, Flink et ainsi de suite, de surveiller, la stabilitť a fourni une garantie pour fournir des donnťes d'entrťe et de sortie pour le dťveloppement des affaires. base de donnťes en temps rťel contenant la dťfinition et la normalisation du point en amont enterrť, les donnťes de comportement des utilisateurs, les journaux de donnťes MySQL de nettoyage Binlog, jouant un traitement tel que large, fournir l'assurance de la qualitť pour les donnťes en aval.
Dans la conception du cadre, y compris les deux sources de donnťes. On est enterrť dans les donnťes de point App, micro-lettres, H5 et d'autres applications, aprŤs kafka envoyťs ŗ la collecte de donnťes primaires, l'autre est une ligne de journal MySQL Binlog donnťes en temps rťel de. Pour le calcul des donnťes de trame qui ne association de nettoyage, les donnťes brutes fournissant plus facile ŗ utiliser par les applications d'entreprise en temps rťel en aval ETL (y compris la largeur de la table en ligne, etc.).
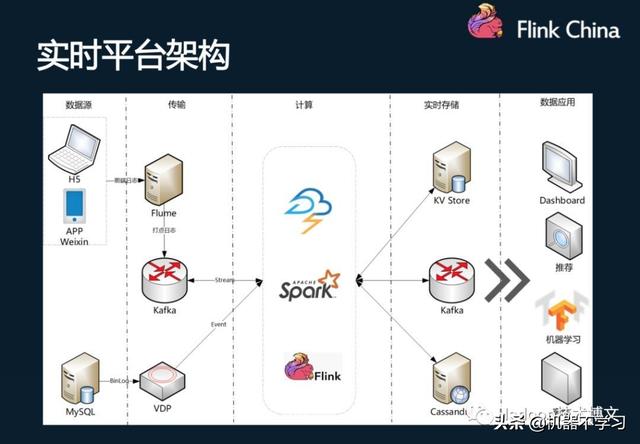
Deux, scŤne Flink pratique d'un produit CD sera: Dataeye en temps rťel Kanban
Dataeye en temps rťel Kanban est les donnťes pour appuyer la nťcessitť pour tous le point enterrť, lorsque les commandes donnťes calculťes en temps rťel, avec une grande quantitť de fonctionnalitťs de donnťes et nťcessitent dimension statistique il y a beaucoup, comme station totale, deux plates-formes, catťgorie, calendrier, foule activitťs, telles que la dimension temporelle, augmentent la complexitť des calculs, l'indice de production de donnťes statistiques a atteint des centaines de milliers par seconde.
UV pour calculer, par exemple, d'abord, les donnťes de Kafka Buried lavťes, puis les donnťes associťes ŗ Redis, de bonnes donnťes de corrťlation sont ťcrites dans Kafka, les t‚ches de calcul Flink donnťes associťes ŗ la consommation ultťrieure de Kafka. Les rťsultats des calculs sont gťnťralement t‚che est grande (en raison notamment des dimensions de calculer et de mesures, peuvent atteindre des dizaines de millions), la sortie de donnťes par aussi par Kafka comme un tampon, t‚che de synchronisation de l'utilisation finale pour synchroniser HBase, comme l'affichage des donnťes en temps rťel. t‚che de synchronisation ťcrirait limite de donnťes HBase et le mÍme type de fusion de l'indice, la protection des HBase. En mÍme temps, il y a une autre faÁon de calculer comme un plan de reprise aprŤs incident.
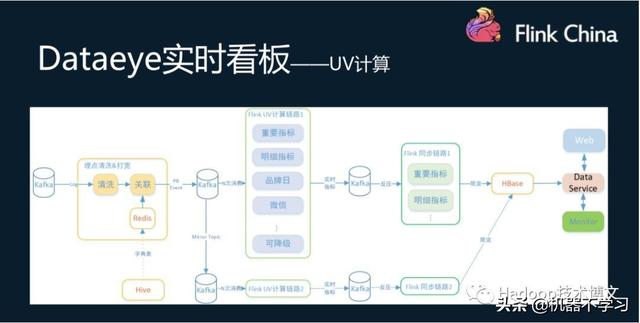
Lorsque le calcul de tempÍte pour calculer le moteur est nťcessaire d'utiliser comme un stockage REDIS ťtat intermťdiaire, mais aprŤs le passage ŗ Flink, Flink lui-mÍme comprend un stockage d'ťtat, ťconomisant de l'espace de stockage; Redis parce qu'aucun accŤs, mais aussi d'amťliorer les performances, la ressource globale la consommation est rťduite ŗ 1/3 de l'original.
Dans le processus de t‚ches informatiques migrent progressivement de Storm ŗ Flink, les deux programmes doivent migrer en mÍme temps pour sťparer les t‚ches informatiques et la synchronisation des t‚ches, les donnťes sont ťcrites pour attťnuer la pression sur la HBase.
AprŤs le passage ŗ Flink aussi besoin de suivre et d'amťliorer un certain nombre de questions. Pour FlinkKafkaConsumer, pour des raisons d'affaires ŗ kafka dans AOTU Commit ŗ modifier, et le rťglage du dťcalage, il est nťcessaire de rťaliser son soutien commutation de cluster de kafka. Pour les donnťes d'ťtat sans la nťcessitť de nettoyer manuellement la fenÍtre. Il existe un cadre informatique problŤme commun - les problŤmes de donnťes doivent Ítre pris en compte. En mÍme temps, le nombre de t‚ches pour problŤme de poursuite synchrone, la tempÍte peut prendre des valeurs des Redis, Flink ne peut attendre.
ScŤne deux: Kafka Shuojuluode HDFS
Avant de rťaliser tout au long de Spark Streaming, maintenant il est progressivement mis ŗ Flink ci-dessus, le tableau de donnťes Buried Ruche OrcBucketingTableSink sur le sol pour les HDFS. Flink en mono processus d'ťcriture des t‚ches jusqu'ŗ 3,5K / s ou plus, aprŤs utilisation Flink consommation de ressources rťduite de 90%, tout en rťduisant le retard dans les annťes 30 ŗ 3. ņ l'heure actuelle faire encore un soutien Flink pour le tableau Bucket Spark de.
TroisiŤme scŤne: ETL-temps rťel
Pour le traitement ETL, la prťsence est un point de mal ŗ HDFS, et est en constante ťvolution de stockage de table dictionnaire, et les besoins de flux de donnťes en temps rťel pour se joindre ŗ la table dictionnaire. Changement dans le tableau dictionnaire est causťe par une t‚che de traitement par lots hors ligne, la pratique actuelle est d'utiliser ContinuousFileMonitoringFunction et ContinuousFileReaderOperator le moniteur de synchronisation HDFS changements de donnťes, les nouvelles donnťes continueront dans les broussailles, les donnťes les plus rťcentes ne rejoignent les donnťes en temps rťel.
Ensuite, nous prťvoyons de faire d'une maniŤre plus gťnťrale, ŗ la table de soutien et Hive Stream, joindre, mettre en uvre des changements de donnťes de table Hive, les donnťes sont automatiquement poussť effet.
Trois, Flink Sur K8S
Il y a un certain nombre de diffťrents cadres de l'informatique ŗ l'intťrieur du seul produit avec calcul en temps rťel, il y a un apprentissage de la machine, ainsi que des calculs hors ligne, et donc la nťcessitť d'un cadre sous-jacent unifiť pour la gestion, et donc migrera Flink au K8S.
Utiliser des composants de rťseau Cisco sur K8S, chaque conteneur de docker a sa propre adresse IP, l'extťrieur est visible. Fusion plate-forme temps rťel architecture globale, comme indiquť ci-dessous.
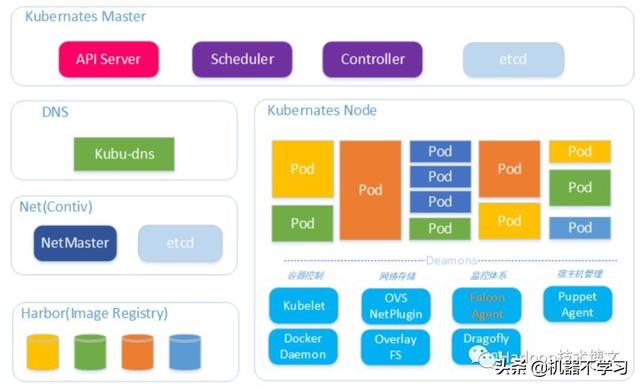
Les diffťrences dans la mise en uvre du programme seront fournis sur la communautť K8S Flink et le produit n'est encore trŤs important. CD produits utiliseront le mode de dťploiement K8S StatefulSet, la mise en uvre interne d'un certain nombre d'interfaces liťes cluster. Un travail correspondant ŗ un mini cluster et supports HA. Pour Flink, la plus grande raison d'utiliser StatefulSet une nacelle de nom d'hŰte est ordonnťe, de sorte que les avantages potentiels sont les suivants:
1.hostname de pod -0 -1 et peut Ítre spťcifiť directement JobManager, peut Ítre utilisť pour dťmarrer une statefulset un cluster, le dťploiement doit Ítre de 2, indťpendamment l'un de TaskManager Jobmanager et le dťploiement.
2. pod aprŤs pour diverses raisons ťchouent, en raison StatefulSet tirer ŗ nouveau la nacelle du mÍme nom d'hŰte, le cluster rťcupťrer le rapport de vitesse peut thťoriquement un dťploiement plus rapide (dťploiement chaque nom d'hŰte alťatoire).
Environnement miroir variable docker script qui entrypoint doit Ítre rťglť instructions d'installation:

grappes Flink correspondant ŗ compter sur d'autres configurations telles que HDFS, ŗ travers la crťation de ConfigMap pour gťrer et maintenir.
kubectl crťer ConfigMap hdfs-conf --from-file = hdfs-site.xml --from-file = core-site.xml
En quatriŤme lieu, le plan de suivi
systŤmes ŗ temps rťel en cours, la plate-forme d'apprentissage de la machine pour les donnťes ŗ traiter dans une variťtť de composants de stockage de donnťes distribuťes, comme Kafka, Redis, Tair et HDFS ainsi de suite, comment un accŤs pratique et efficace, le traitement, le partage des donnťes est un grand dťfi pour le courant accŤs aux donnťes et la dťtermination prend souvent beaucoup d'ťnergie, un des points de douleur principaux comprennent:
Pour Kafka, Redis, Tair en binaire des donnťes (format PB / Avro), les utilisateurs ne peuvent pas comprendre rapidement et directement le schťma et les donnťes de contenu, les coŻts d'acquisition de donnťes de contenu et de communication sont ťlevťs et l'ťcrivain.
…tant donnť que l'absence d'un ensemble de donnťes des services de systŤme indťpendant unifiť, l'accŤs aux donnťes binaires ŗ Kafka, Redis, Tair et comme le besoin de compter sur les informations fournies par l'auteur, tels que la gťnťration de classe proto, les dťfinitions de format de donnťes wiki, les coŻts de maintenance ťlevťs, sujettes ŗ erreur.
L'absence de schťma relationnel afin que l'utilisateur ne peut pas directement basťe sur une utilisation plus efficace SQL ou une entreprise de dťveloppement API couche LINQ.
Un des services pratiques distinctes pour publier et partager des donnťes ne peuvent pas passer.
donnťes en temps rťel ne peuvent Ítre fournis directement au lot moteur SQL.
De plus, pour la plupart de la source de donnťes actuelle est aussi un manque de vťrification d'accŤs, la gestion des droits, contrŰle d'accŤs, le suivi et d'autres caractťristiques.
UDM (Unified Data Management System) comprend un emplacement gestionnaire, le schťma Metastore et des modules client proxy, principales caractťristiques comprennent:
1. Fournir un nom au service de mappage d'adresses de l'utilisateur pour accťder aux donnťes par nom plutŰt que l'adresse spťcifique abstraite.
2. Les utilisateurs peuvent facilement via l'interface GUI Web facilement visualiser les donnťes de schťma, le contenu des donnťes d'exploration.
3. Fournir un soutien pour l'audit, le suivi, l'API client proxy fonctionnalitťs supplťmentaires telles que la traÁabilitť.
4. Spark / Flink / Storm comme cadre, l'encapsulation des sources de donnťes fournissant la forme la plus appropriťe.
UDM structure globale tel que reprťsentť sur la Fig.
les utilisateurs UDM, y compris les producteurs et les utilisateurs de temps rťel, la plate-forme d'apprentissage automatique et les donnťes hors ligne. Lorsque vous utilisez l'API SQL ou l'API de table, d'abord terminer l'enregistrement du schťma, puis utiliser le dťveloppement Sql, ce qui rťduit la quantitť de dťveloppement de code.
Tableau de calage de l'allumage pour accťder aux donnťes dťcrit Kafka PB processus internes de l'UDM
Dans Flink, un UDMExternalCatalog de pont entre l'ouverture et le cadre de calcul UDM Flink, en mettant en oeuvre ExternalCatalog chaque interface, et de mettre en uvre la TableSourceFactory de source de donnťes respective, l'accomplissement des fonctions de contrŰle d'accŤs, etc. Schťma