Il y a quelques jours, l'équipe Chen Tianqi a annoncé TVM, sur dit le microblogging, « nous avons publié TVM aujourd'hui, et forment ensemble une étude approfondie NNVM pour compléter une variété de chaîne d'outils d'optimisation du matériel pour supporter le téléphone mobile, cuda, OpenCL, métal, javascript et divers autres arričre-plan. Bienvenue ŕ la théorie du compilateur apprentissage en profondeur, calcul haute performance, l'accélération matérielle des étudiants intéressés ŕ se joindre ensemble pour promouvoir les grands projets open source DMLC communauté ».
Selon Lei Feng réseau AI Technology Review est entendu que la plupart des systčmes existants sont optimisés pour une gamme étroite de GPU au niveau du serveur, et la nécessité de déployer beaucoup de travail sur, y compris les téléphones mobiles, les équipements IOT et des accélérateurs dédiés. Et TVM est une pile matérielle d'extrémité de la profondeur du déploiement de la charge de travail d'apprentissage IR (représentation intermédiaire). En d'autres termes, ce type de solution peut ętre distribuée au modčle d'apprentissage en profondeur sur une variété de périphériques matériels, pour atteindre fin ŕ l'accord final.
Il est la présence de trois caractéristiques:
-
Pour optimiser CPU, GPU et autre matériel informatique spécialisé sur les tâches d'apprentissage profondeur réguličre;
-
calcul figure peut ętre convertie automatiquement, de sorte que l'utilisation de la mémoire est réduite au minimum, afin d'optimiser la présentation des données, le mode de calcul de la fusion.
-
Compilé ŕ partir de la fin de l'avant existante pour fournir la fin de matériel métal nu, les Javascripts exécutables du navigateur.
Lei Feng réseau AI Technology Review a appris, le blog de TVM est le premier décrit le papier:
« Avec l'aide de TVM, les développeurs ont besoin seulement une petite quantité de travail supplémentaire, vous pouvez facilement courir sur le côté du téléphone mobile, les appareils embarqués et męme sur la profondeur des tâches d'apprentissage .TVM navigateur fournit également une étude en profondeur uniforme et la charge de travail sur plusieurs plates-formes matérielles cadre d'optimisation, y compris le recours ŕ l'informatique nouveau accélérateur dédié primitif ».
Et aujourd'hui, Chen Tianqi a publié une nouvelle dynamique sur le microblogging au didacticiel suivant Tucson Hu Wei a présenté en se concentrant sur la promotion de l'optimisation des op apprentissage en profondeur de TVM.
« Apprentissage en profondeur l'optimisation des op est trčs importante, mais la question difficile. De Tucson avenir Hu Wei a écrit un tutoriel décrit comment optimiser l'utilisation de l'étude approfondie VRA de op gpu, que existante tf passer ŕ travers quelques dizaines de lignes de code pour atteindre vingt-trois python fois plus élevé ".
Cet article est également mis ŕ jour en męme temps sur le blog TVM, Lei Feng réseau AI Technology Review premičre fois ŕ faire la couverture et les rapports.
Hu Wei, maîtrise en génie électronique, Université de Beijing de l'aéronautique et de l'astronautique, actuellement Gap année, et maintenant la pratique de groupe HPC futur Tucson. L'article, intitulé « Optimiser les GPU profondes d'apprentissage avec les opérateurs: TVM Un exemple Convolution la profondeur » (ŕ Convolution sens de la profondeur, par exemple, pour optimiser l'utilisation de l'opérateur GPU TVM apprentissage en profondeur)
opérateur efficace systčme d'apprentissage de l'apprentissage en profondeur est la profondeur de base. Ces opérateurs habituellement difficiles ŕ optimiser, les experts HPC doivent payer beaucoup d'efforts. TVM comme une pile de bout en tenseur IR / DSL, peut faciliter l'ensemble du processus.
Cet article fournit une bonne référence, comment les développeurs d'apprendre ŕ écrire noyau GPU haute performance avec l'aide des opérateurs de TVM. L'équipe utilise Convolution sens de la profondeur (c.-ŕ-topi.nn.depthwise_conv2d_nchw) ŕ titre d'exemple, et montre comment vous pouvez améliorer le déjŕ optimisé manuellement tensorflow le noyau CUDA.
La description de l'article en utilisant la version finale 2-4 TVM fois plus rapide que tf-1.2 sous différentes charges d'exploitation optimiser le noyau, la fusion de l'opérateur trois fois plus vite -7 fois. Voici les résultats des tests dans le cadre GTX1080, la taille du filtre = , stride = , padding = 'męme':

Est une circonvolution la profondeur idée de base de la construction d'un modčle peut effectivement réduire la complexité de calcul de la profondeur des réseaux de neurones, y compris Xception et MobileNet appartiennent Convolution Google sens de la profondeur.

Dans l'environnement TVM, en cours d'exécution du code est Convolution comme la profondeur suivante:
# Rembourrage stagePaddedInput = tvm.compute (
(Lot, in_channel, height_after_pad, width_after_pad),
lambda b, c, i, j: tvm.select (
tvm.all (i > = Pad_top, i - pad_top = pad_left, j - Entrée pad_left , Tvm.const (0,0)),
name = "PaddedInput") # depthconv stagedi = tvm.reduce_axis ((0, filter_height), name = 'di') dj = tvm.reduce_axis ((0, filter_width), name = 'dj') Output = tvm.compute (
(Lot, out_channel, out_height, out_width),
lambda b, c, i, j: tvm.sum (
PaddedInput * Filtre ,
axe = ),
name = 'DepthwiseConv2d')
Guide GPU général Optimisation
Hu Wei a mentionné trois problčmes majeurs lors de l'optimisation du code CUDA devrait généralement ętre noté dans l'article, qui est, la réutilisation des données (réutilisation des données), la mémoire partagée (mémoire partagée) et une violation d'accčs (conflits bancaires).
Dans l'architecture de l'informatique moderne, le coűt est calculé ŕ partir du chargement des données de la mémoire est beaucoup plus élevé que le simple virgule flottante. Par conséquent, nous voulons ętre chargé dans un registre ou cache peut ętre utilisé ŕ nouveau dans les données d'entrée.
Il existe deux formes de la convolution de la profondeur de la réutilisation des données: des filtres d'entrée réutilisation et le recyclage, les anciennes lames sur un canal d'entrée et calcule une pluralité de fois, ce qui se produit lorsque la tuile, par exemple ŕ convolution de la profondeur 3x3:

Sans tuile, chaque fil et calcule un des éléments de données d'entrée de charge de sortie 3x3. Un total de 16 fils 9x16 charges.

La tuile, chaque fil calcule 2x24x4 sorties des éléments de données d'entrée et des charges. Un total de 4 fils 16x4 charges.
Et la mémoire partagée violation d'accčs
tampon de mémoire partagée peut ętre considérée comme un GPU, et est plus rapide sur la feuille. La pratique habituelle consiste ŕ charger les données de la mémoire globale en mémoire partagée, et toutes les discussions dans les données de bloc sont lues ŕ partir de la mémoire partagée.

Afin d'éviter une violation d'accčs, un fil continu d'un accčs continu ŕ la meilleure adresse mémoire comme indiqué (chaque couleur représente une banque de mémoire partagée):
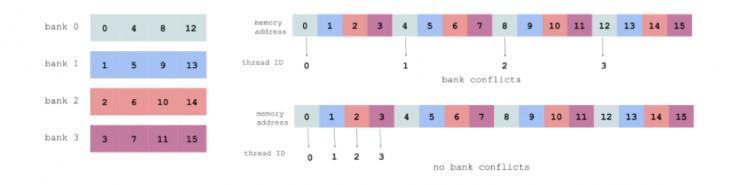
Pour plus de détails se référer https://devblogs.nvidia.com/parallelforall/using-shared-memory-cuda-cc/
processus d'optimisation spécifique
Calcul de l'entrée ligne de remplissage pour enregistrer l'allocation de mémoire
Rembourrage est explicitement déclaré comme une étape distincte. En calculant l'allocation de mémoire en ligne pour éviter la redondance:
s = tvm.create_schedule (s) Output.op .compute_inline
Le passage d'un grand bloc en plus petits
Une approche simple est un traitement de CUDA un bloc de canal d'entrée et les filtres correspondants, pour calculer la mémoire partagée aprčs le chargement:
IS = s.cache_read (PaddedInput, "partagée", )
FS = s.cache_read (Filter, "partagée", )
block_y = tvm.thread_axis ( "blockIdx.y")
block_x = tvm.thread_axis ( "blockIdx.x")
# Bind la dimension du lot (N dans NCHW) avec block_y
s .bind (Output.op.axis , block_y)
# Bind la dimension du canal (C en NCHW) avec block_x
s .bind (Output.op.axis , block_x)
La figure ci-dessous montre les résultats des tests, le coűt du temps moyen de fonctionnement des GTX 10801000 fois et par rapport ŕ tensorflow et depthwise_conv2d.
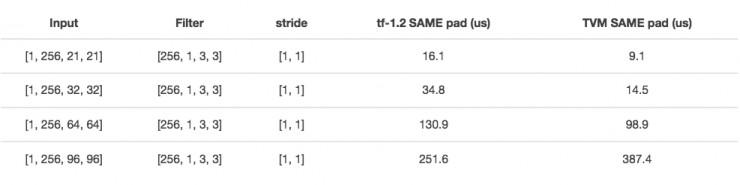
la performance est bonne, mais si elle est de 64 x 64, alors la performance sera grandement diminuée si le canal est de 21 x 21 ou 32 x 32 taille,. Si vous faites des changements, l'effet augmentera beaucoup:


Le nombre de fils paramčtres de réglage
Enfilez réalisé dans un cuda bloc 32 x 32, comme suit:

Comment num_thread_y et num_thread_x ces deux paramčtres ajustés pour obtenir la solution optimale? Dans Filter = et foulée = ci-dessous:

Grâce ŕ des tests, l'équipe a obtenu les résultats suivants:
-
Ŕ grande échelle la réutilisation des données de tuiles est bonne, mais pas propice ŕ la lecture de la mémoire locale.
-
Différents effets num_thread_y et l'accčs num_thread_x au conflit.
-
Et num_thread_x num_thread_y meilleure combinaison d'accčs ŕ la mémoire partagée nécessaire pour atteindre (zone de stockage, éviter des conflits) efficaces, la réutilisation des données, et l'équilibre de la mémoire locale lue.
Par la recherche de la force brute, la TVM nous pouvons num_thread_y et num_thread_x passés comme arguments ŕ l'annexe de la fonction, et d'essayer toutes les combinaisons possibles pour trouver la combinaison optimale.

Vthread (fil virtuel) et Modčles strided
En TVM, Vthread peut soutenir efficacement modčles strided.

Dans le filtre en cas = , foulée = , blocking_h = 32, blocking_w = 32, les résultats sont comme suit:

plus vite que le cas 1 cas 2, étant donné que le boîtier 2 num_thread_x = 8 et num_vthread_x = 4 cas, afin d'assurer des fils continus accéder ŕ des adresses de mémoire consécutives, pour des conflits d'accčs ŕ éviter, comme le montre (chaque couleur représente un fil charge de travail):

Rappelons ŕ nouveau le contraste et tensorflow:

fusion des opérateurs
opérateur de fusion est un procédé typique pour l'optimisation de réseau d'apprentissage de la profondeur, dans la TVM en tenant compte du modčle original depthwise_conv2d + + scale_shift de Relu, peut ętre légčrement modifié comme suit:

IR généré comme suit:
/ * Entrée = , Filter = , foulée = , padding = 'SAME' * / {produire Relu
// attr thread_extent = 1 // attr storage_scope = allouer DepthwiseConv2d "local"
// attr thread_extent = 1 // attr thread_extent = 8 // attr thread_extent = 8 produits DepthwiseConv2d {
pour (i, 0, 4) {
pour (j, 0, 4) {
DepthwiseConv2d = 0.000000f
pour (di, 0, 3) {
pour (dj, 0, 3) {
DepthwiseConv2d = (DepthwiseConv2d + (tvm_if_then_else (((((((1 - di) - i)}
}
}
}
}
pour (i2.inner.inner.inner, 0, 4) {
pour (i3.inner.inner.inner, 0, 4) {
Relu = max (((DepthwiseConv2d * Echelle ) + Maj ), 0.000000f)
}
}}
Vous pouvez le voir, chaque fil avant que les résultats sont écrits depthwise_conv2d mémoire globale, et calcule scale_shift Relu. Fusion avec un seul opérateur depthwise_conv2d aussi vite. Ci-dessous = entrée , Filter = , stride = , les résultats rembourrage = 'SAME' est:
-
tf-1.2 depthwise_conv2d: nous 251,6
-
tf-1,2 depthwise_conv2d + scale_shift + Relu (séparée): 419,9 nous
-
TVM depthwise_conv2d: nous 90,9
-
TVM depthwise_conv2d + scale_shift + Relu (fusion): 91,5 nous
code plus optimisé peut se référer aux liens suivants:
Declare: https://github.com/dmlc/tvm/blob/master/topi/python/topi/nn/convolution.py
Horaire: https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/depthwise_conv2d.py
Test: https://github.com/dmlc/tvm/blob/master/topi/recipe/conv/depthwise_conv2d_test.py