
annuaire
structure de réseau de neurones recherche évolutive algorithme basé sur les valeurs et les droits partagés
Regarder la détection vidéo de la cible visuelle
Faiblement méthode d'apprentissage supervisé comprend des informations d'état sont la reconnaissance de caractčres
Les estimations fondées sur la posture du corps d'anatomie 3D vidéo perçue
Randla-Net: Un nouveau cadre de segmentation sémantique de nuage de points de masse
structure de réseau de neurones recherche évolutive algorithme basé sur les valeurs et les droits partagés
Titre de la thčse: CARS: Evolution continue pour l'efficacité Neural architecture Search
Auteur: Zhaohui
Publié: 04/03/2020
Documents lien: https //Paper.yanxishe.com/review/13531 de = :? leiphonecolumn_paperreview0312
raison recommandée
Cet article 2020CVPR article, est un document Huawei. La question principale de cet article est d'optimiser la structure des algorithmes évolutifs dans la recherche de réseau de formation de réseau de neurones quand l'élection est trop long, les auteurs se réfčrent ŕ la ENAS et NSGA-III. Sur cette base, les auteurs proposent une nouvelle approche - l'évolution continue de la recherche de la structure (recherche d'architecture d'évolution continue), en abrégé CARS. La méthode fait usage de toutes les connaissances acquises, autant que possible, y compris la structure et les paramčtres du dernier cycle de formation.
innovations:
1, nous avons développé une méthode efficace pour la recherche évolution continue des réseaux de neurones. Vous pouvez régler l'architecture globale de la derničre génération a partagé les paramčtres de SuperNet dans l'ensemble de données de formation.
2, les stratégies de tri Aucun dominé ŕ choisir différentes tailles excellent réseau, le temps global besoin que de 0,5 jour de GPU.


Regarder la détection vidéo de la cible visuelle
Titre de la thčse: Détection Assisté des cibles visuelles en vidéo
Auteur: Chong Eunji / Wang Yongxin / Ruiz Nataniel / Rehg James M.
Publié: 05/03/2020
Documents lien: https //Paper.yanxishe.com/review/13533 de = :? leiphonecolumn_paperreview0312
raison recommandée
Cet article est CVPR 2020 la réception, pour résoudre le problčme est de détecter un objet d'intéręt dans la vidéo. Plus précisément, l'objectif est de définir chaque image vidéo de la ligne de chaque personne de la vue et la manipulation correcte du cadre extérieur (cas. Nouvelle architecture Mentionné simulent efficacement l'interaction dynamique entre la scčne et les caractéristiques de la tęte ŕ déduire les changements au fil du temps l'objet d'intéręt. en męme temps ce document présente une nouvelle série de données VideoAttentionTarget, contient réelles expériences sur le comportement du regard complexe et dynamique effectuées sur les ensembles de données montrent que le modčle proposé peut déduire vidéo d'attention. pour démontrer l'utilité de la méthode, l'attention du papier ŕ dessin prédit appliqué ŕ deux tâches de reconnaissance du comportement du regard social, et de montrer le classificateur résultant est nettement mieux que les méthodes existantes.


Faiblement méthode d'apprentissage supervisé comprend des informations d'état sont la reconnaissance de caractčres
Titre de la thčse: Faiblement apprentissage supervisé de fonction discriminante avec des informations d'état pour l'identification des personnes
Auteur: Yu Hong-Xing / Zheng Wei-Shi
Publié: 27/02/2020
Documents lien: https //Paper.yanxishe.com/review/13409 de = :? leiphonecolumn_paperreview0312
raison recommandée
Ce document présente méthode d'apprentissage faiblement supervisé en utilisant les informations état de reconnaissance des piétons de mise en uvre.
En acquérant le coűt trop élevé de la réalité des données de formation étiquetée manuellement, en utilisant l'apprentissage non supervisé pour identifier les différentes caractéristiques visuelles de chaque piéton a une signification trčs importante. Cependant, en raison de la position de tir que l'angle de la caméra différences de statut inégales, les męmes photos individuelles sont des différences visuelles existent, ŕ l'étude de la classification non supervisée a apporté de grandes difficultés. Ce document propose la faible méthode d'apprentissage supervisé peut ętre utilisé non souhaitées, des informations d'état d'annotation manuelle (par exemple une position de prise de photographie de l'appareil photo ou le visage dimensions angulaires), le procédé utilisant la catégorie d'information d'état limite de décision optimale est supposée, et le réglage de l'information d'état d'utilisation compenser les caractéristiques d'identification de contrôle. Thčse sur le duc-REID, MultiPie et ensembles de données de test CFP, le résultat est de loin supérieur aux autres méthodes existantes, alors que le modčle standard et des documents supervisés modčles d'apprentissage ont également été comparés en comparaison, et ont montré des performances comparables. Code article visible https: //github.com/KovenYu/state-information.


Les estimations fondées sur la posture du corps d'anatomie 3D vidéo perçue
Titre de la thčse: Anatomie-conscience humaine 3D Pose Estimationin vidéo
Auteur: Tianlang Chen
Publié: 01/02/2020
Documents lien: https //Paper.yanxishe.com/review/13408 de = :? leiphonecolumn_paperreview0312
raison recommandée
Les implications pour la recherche:
Cet article présente une nouvelle vidéo dans les solutions d'estimation de pose humaine 3D. Par rapport ŕ la recherche traditionnelle, ce document ne sont pas directement selon l'étude de position commune 3D, mais du point de vue de l'anatomie du squelette humain, la tâche dans la prédiction de prédiction direction longueur des os et des os prédiction de deux articulations peut donner trois dimensions emplacement.
innovations:
1, cet article propose une structure de propagation complčte de convolution de connexion de saut en longueur, la direction de prédiction pour les os. La structure du réseau peut ętre réalisé lors de la superposition de l'os pronostic de direction sans utiliser des unités consommatrices de temps de stockage (par exemple LSTM).
2, en utilisant un des points clés mécanisme d'attention implicite 2D visibilité de rétroaction Fractional dans le modčle comme un guide supplémentaire, ce qui facilite considérablement l'ambiguďté de profondeur les nombreuses postures difficiles.


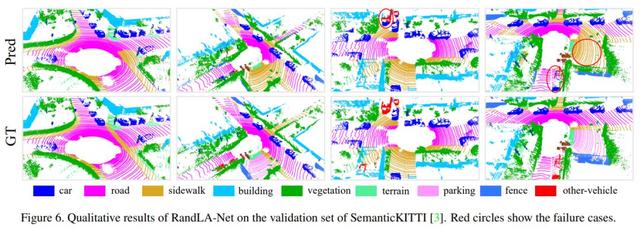
Randla-Net: Un nouveau cadre de segmentation sémantique de nuage de points de masse
Titre de la thčse: Randla-Net: Segmentation efficace sémantique des nuages de points grande échelle
Auteur: Qingyong Hu
Publié: 01/02/2020
Documents lien: https //Paper.yanxishe.com/review/13407 de = :? leiphonecolumn_paperreview0312
raison recommandée
Le noyau de cet article:
Auteur introduit le cadre du réseau Randla-Net pour en déduire la sémantique par point sur un grand nuage de points d'échelle. La raison pour laquelle la méthode de sélection de point d'échantillonnage aléatoire au lieu des points plus complexes, car le cadre peut réduire considérablement l'empreinte mémoire du coűt de calcul. En outre, les auteurs ont introduit un nouveau module d'agrégation de fonction locale, en utilisant une architecture de réseau léger, Randla-Net ultime preuve que le cadre du réseau peut ętre utilisé efficacement pour résoudre le problčme du nuage de points de masse.
innovations:
Sur la structure du réseau proposé (Randla-Net) basée sur un simple et un échantillonnage aléatoire efficace polymérisation en fonction locale. La méthode pour diviser l'ensemble de données Semantic3D SemanticKITTI et d'autres ensembles de données de nuages de points grande scčne sont trčs bons résultats, ce qui prouve les excellentes propriétés de la méthode, par ailleurs, nous avons constaté expérimentalement que le cadre proposé pour un réseau, l'efficacité de calcul est trčs élevé, nettement mieux que les autres modčles.


Lei Feng Lei Feng Lei réseau de réseau de réseau Feng