

Ji-won nouveau rapport
Source: Google AI
Editeur: Xiao Qin, trois pierres
[Introduction de nouveaux Zhi Yuan ] Grand Dieu Geffery Hinton est l'inventeur de l'algorithme de propagation inverse, mais il a également exprimé des doutes sur le dos de propagation, je pense que la propagation de retour est clairement pas la façon dont le cerveau fonctionne, afin de promouvoir le progrčs technologique, il doit y avoir une nouvelle méthode a été inventée. Google plus que les chercheurs du cerveau ont présenté aujourd'hui les derniers articles publiés Backprop Evolution, nous proposons une méthode de découverte automatique inverser la propagation de nouvelles variantes de l'équation, qui a trouvé une nouvelle équation, la formation plus rapide que l'arričre-standard propagation temps de formation est plus courte.
Documents Adresse:
https://arxiv.org/pdf/1808.02822.pdf

algorithme de rétropropagation proposé par le dieu Geoffrey Hinton est la pierre angulaire de la profondeur de l'apprentissage.
En 1986, Geoffrey Hinton et co-auteur d'un document: les représentations d'apprentissage par les erreurs de rétropropagation, aprčs 30 ans, l'algorithme de rétropropagation est devenu le cur de cette vague d'explosion de l'intelligence artificielle.
Mais l'année derničre, Hinton a déclaré dans une interview qu'il propagation algorithme pour inverser " Des doutes sérieux « Cela devrait Complčtement abandonné rétropropagation, tout recommencer . Hinton estime que le mode inverse de la transmission ne fonctionne cerveau, nous ne devons évidemment pas le cerveau pour marquer toutes les données. Afin de promouvoir les progrčs, il doit y avoir une nouvelle méthode a été inventée.
Bien que Hinton, ainsi que de nombreux chercheurs doivent encore présenter de nouvelles, il peut remplacer la méthode de propagation, mais récemment, l'apprentissage de la machine recherche automatiquement moyen d'obtenir beaucoup de succčs, variantes de l'algorithme rétropropagation Il a également été de plus en plus de recherches.
Université technique de Berlin, plus que les chercheurs de Google cerveau articles récemment publiés Evolution Backprop est proposé découverte automatique de nouvelles variantes équation rétropropagation Méthode. Les chercheurs ont utilisé un langage spécifique, de domaine sera mis ŕ jour la liste originale des équations décrivant la fonction.

Plus précisément, les chercheurs ont utilisé une méthode basée sur l'évolution de découvrir de nouvelles rčgles de communication qui peuvent optimiser leurs performances aprčs quelques généralisation de la formation d'époque. Ils ont trouvé des nouvelles équations, leur la formation plus rapide, le temps de formation est plus courte que la propagation standard arričre, et de męme lorsque les critčres de convergence rétropropagation .
générer automatiquement des équations de rétro-propagation
algorithme de rétropropagation est l'un des plus importants algorithmes d'apprentissage automatique. Il a été mis sur l'équation rétropropagation variantes fait une tentative, et atteint un certain degré de succčs (par exemple, Bengio et al (1994) ;. Lillicrap et al (2014) ;. Lee et al (2015) ;. Nřkland (2016); Liao et al (2016)) .. Mais en dépit de ces tentatives, les changements d'équations rétropropagation et n'ont pas été largement utilisés en raison de ces changements il y a peu d'amélioration dans l'application pratique, et parfois męme causer des dommages.
Affecté par la récente apprentissage automatique pour rechercher automatiquement des méthodes inspirées par le succčs obtenu, nous vous proposons un générer automatiquement des équations de rétro-propagation Méthode.
A cet effet, nous proposons une Langues spécifiques au domaine (Langue spécifique du domaine), une formule mathématique pour décrire ces fonctions ŕ la liste initiale, et basée sur l'utilisation de évolution (Basée-Evolution) façon de découvrir de nouvelles rčgles de communication. Aprčs la formation de plusieurs époque, la condition de recherche est de maximiser la généralisation. Nous avons trouvé la norme rétropropagation et l'effet est également plusieurs variantes de l'équation. De plus, dans un temps de formation relativement courte, ces types de variations peuvent améliorer la précision. Cela peut ętre utilisé pour améliorer l'algorithme Hyperbande comme prendre des décisions fondées sur la précision du processus de formation.
Rétropropagation

Figure 1: le réseau de neurones peut ętre vu comme une certaine figure de calcul. La figure définir l'avant (vers l'avant du graphique) de concepteurs de réseaux, et l'algorithme de propagation inverse définit implicitement un calcul figure paramčtre de mise ŕ jour. La principale contribution de cette étude est d'explorer comment utiliser l'évolution pour trouver un rétropropagation plus efficace que la mise ŕ jour de carte de calcul de paramčtres standard.

Parmi eux,






Une fois calculé, vous pouvez mettre ŕ jour le poids est calculé comme:

1, le réseau de neurones peut ętre exprimée comme sur la Fig. Vers l'avant et vers l'arričre calcul sur la Fig. . Étant donné une carte de calcul avant défini par le concepteur du réseau, l'algorithme de rétropropagation définit un calcul inverse pour la mise ŕ jour des paramčtres de la figure. Cependant, il est possible de trouver une carte de calcul inverse amélioré, entraînant une meilleure généralisation.
Récemment, méthode de recherche automatique pour l'apprentissage machine déjŕ obtenu de bons résultats dans une variété de tâches, ces méthodes impliquent la carte de calcul, en se fondant sur le dos de propagation pour définir le point de vue inverse appropriée avant modification. En revanche, dans ce travail, notre souci est de modifier le tableau de calcul inverse et utiliser la recherche pour trouver une meilleure méthode d'équations, une nouvelle rčgles de formation.
méthode
Afin de trouver des moyens d'améliorer les rčgles de mise ŕ jour, nous utilisons des algorithmes évolutifs pour rechercher l'espace de l'équation de renouvellement possible (mise ŕ jour équation) est. Dans chaque itération, le nombre de mutations dans l'équation de mise ŕ jour du contrôleur évolutive envoyée pour évaluer le bassin de travailleurs. Chaque travailleur en utilisant l'équation de la variation de la réception de former le réseau de neurones ŕ une structure fixe, et de vérifier l'exactitude du rapport obtenu au contrôleur.
L'espace de recherche
Inspiré par Bello et al. (2017), nous utilisons le langage spécifique ŕ un domaine (langage spécifique au domaine, DSL) pour le calcul de l'équation décrite. Chaque équation est représentée par DSL


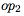



Opérande (opérandes): W (poids de la matrice de poids actuel de la couche),

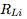



Fonctions d'une variable

fonction binaire

Dans lequel, l'indice de la couche en cours. Voir l'ensemble complet d'expériences en utilisant du papier Annexe A.
Les résultats obtenus quantité

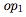
Les algorithmes évolutionnaires
évolution contrôleur (Contrôleur Evolutionary) pour maintenir un ensemble d'équations ont été trouvés. Dans chaque itération, les préformes de contrôleur un des éléments suivants: 1) la probabilité p de l'affaire, le contrôleur de compétitivité optimal de N trouvés lors de la recherche dans une équation de sélection aléatoire, 2) la probabilité 1-- lorsque p, le dispositif de commande sélectionne de façon aléatoire un de l'autre équation de la population d'équation.
Le dispositif de commande alors k mutations (mutation) ŕ une équation sélectionnée, oů k est extrait de la distribution de la classification. Ces mutations k chacune des sélectionnant simplement un des composants de l'équation aléatoire uniforme (par exemple, un opérande, une fonction unaire, ou une fonction binaire), puis les autres composants similaires qui change de maničre aléatoire. Certaines mutations peuvent conduire ŕ l'équation mathématique possible, dans ce cas, le contrôleur redémarre le processus de mutation jusqu'ŕ ce qu'il réussisse. N, le classement et la distribution p k est l'algorithme ultra-paramčtre.
Pour créer la population initiale, nous échantillon aléatoire simple de N équations de l'espace de recherche. En outre, dans certaines de nos expériences, on part d'une petite partie de l'équation prédéfinie (généralement normale ou une variante de l'équation de propagation inverse rétroaction équation alignés). A partir de la capacité existante de l'équation d'évolution est basée sur la méthode d'apprentissage par renforcement a l'avantage.
Expériences et résultats
Dans cette méthode, pour L'évaluation de la sélection de chaque nouveau modčle de l'équation Il est un cadre important. réseau plus large et plus profond serait plus réaliste, mais il faut plus de temps pour le train, alors que la formation du plus petit modčle plus rapide, mais ne peut pas conduire ŕ mettre ŕ jour la promotion du réseau. Nous avons équilibré ŕ l'aide de larges ResNets (WRN), ces deux normes, la couche de WRN 16, la largeur du multiplicateur de 2, et centrées sur les données d'apprentissage ICRA-10.
Recherche de base et la généralisation
Dans la premičre recherche, le contrôleur propose une nouvelle WRN de formation du réseau d'équations 16-2 époque 20, et il y a dans le cas avec ou sans formation dynamique de SGD. La nouvelle équation 100 pour vérifier l'exactitude avant la collecte, puis testé selon différents scénarios:
(A1) en utilisant la formation 20 WRN époque 16-2, la copie des paramčtres de recherche;
(A2) en utilisant une formation 20 époque WRN 28-10, il sera étendu ŕ un plus grand modčle (paramčtre WRN 28- 10 est WRN 10 fois 16-2);
(A3) ŕ l'aide WRN de formation 100 époque 16-2, essai étendu ŕ un mécanisme de formation plus longue.
Les résultats sont présentés dans le tableau 1:


Tableau 1: Résultats expérimentaux
De A1 ŕ A3, présente deux équations meilleures performances dans chaque réglage, ainsi que deux dans tous les milieux ont montré une bonne équation. 4 montre la personnalité meilleure B1 équation, tous les résultats sont plus de cinq fois la précision de test moyenne. La ligne de base est la rétro-propagation de gradient. Mieux que 0,1% des résultats de performance de base sont indiqués en gras. nous utilisons


Augmenter le nombre de formation de recherche
Avant la recherche a été trouvé au début de la formation nouvelle équation fonctionne bien, mais pas mieux que dans la convergence de rétropropagation. Ce dernier résultat pourrait ętre dű ŕ un décalage entre la recherche et le mécanisme d'essai, parce que la recherche en utilisant l'époque 20 ŕ former sous-modčle, et le mécanisme de test utilise époque 100.
Un programme de suivi correspondent ŕ ces deux mécanismes. Dans la deuxičme expérience de recherche, 100 chaque époque la formation sous-modčle. Pour compenser l'utilisation d'époque plus de formation résultant de l'augmentation des temps d'expérimentation, l'utilisation de petits réseaux (WRN 10-1) comme modčle d'enfant. Utiliser un modčle plus petit est acceptable, parce que la nouvelle équation tend ŕ ętre étendu ŕ un plus grand, des modčles plus réalistes tels que (A2).
Les résultats du tableau 1 (B1) et (A3) est similaire ŕ celui obtenu de meilleurs résultats se trouvent sur la rčgle de mise ŕ jour de SGD, mais les résultats ont l'élan et la ligne de base tout ŕ fait SGD. (A3) et (B1) montrent la similitude des résultats, la principale source d'erreurs de différence de temps de formation ne peut pas ętre. En outre, SGD a pour l'équation dynamique nouvelle et différente est presque constante.
résumé
Dans ce travail, nous proposons une équation de substitution peut trouver automatiquement la méthode de propagation standard arričre. L'utilisation d'un contrôleur évolutif (travail équations composante spatiale), et d'essayer de maximiser le réseau de formation de généralisation. les résultats préliminaires donnent ŕ penser que pour une scčne particuličre, il y a une équation de performance de généralisation mieux que la ligne de base, mais pour trouver une meilleure performance dans les équations scčne générale doivent faire plus de travail.
New Ji-won AI MONDE 2018 Assemblée de billets Early Bird []
En solde!
New Ji-won aura lieu le 20 Septembre AI Conférence mondiale des 2018 ŕ Beijing National Convention Center, a invité l'apprentissage machine parrain, en mettant l'accent sur le professeur de l'intelligence artificielle ŕ la CMU Tom Mitchell, Maike Mark Si-Tiger, Zhou Zhihua, un grand Cheng Tao, Chen Yiran AI et d'autres dirigeants et le destin de l'humanité.
Le site officiel de l'Assemblée générale:
Maintenant jusqu'au 19 Aoűt, Ji-won nouveau numéro d'édition limitée de billets Early Bird communication étroite avec le leader mondial de l'IA, l'intelligence artificielle, témoin de l'industrie mondiale ŕ pas de géant.

-
Billets de ligne active lien:
-
billet de ligne active de code ŕ deux dimensions:
