
Source: AI Youdao
Cet article sur 2800 mots Il a recommandé la lecture de 6 minutes.
Cet article est de résumer la fonction d'activation commune sigmoďde, tanh, points de connaissances clés Relu, Leaky Relu, ELU, MAXOUT de.
Nous savons que le modčle de réseau de neurones, chaque couche cachée et la couche de sortie, y compris la nécessité d'activer la fonction (Fonction d'activation). Nous sommes plus familiers avec la fonction d'activation utilisée est également Relu, sigmoďde et ainsi de suite. Cependant, la méthode de sélection pour chaque fonction d'activation, sauf si il y a quelques fonctionnalités qui nécessitent une attention particuličre. Aujourd'hui, nous avons et tout le monde travailler ensemble pour résumer la fonction d'activation commune sigmoďde, tanh, points de connaissances clés Relu, Leaky Relu, ELU, MAXOUT de.
Pourquoi avons-nous besoin d'activer la fonction
La structure de base d'un seul neurone réseau neuronal est constitué de sortie linéaire et non linéaire une sortie Z de deux parties. Comme indiqué ci-dessous:
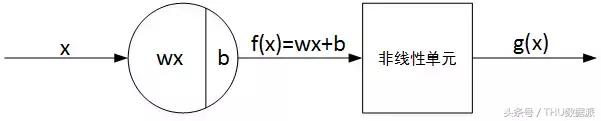
Dans lequel, f (x) est la sortie linéaire Z, g (x) est la sortie non-linéaire, g () représente la fonction d'activation. Populaire, la fonction d'activation est généralement fonction non linéaire, son rôle est de se joindre ŕ une partie du réseau de neurones non linéaire ŕ des facteurs tels réseaux de neurones peut mieux résoudre des problčmes plus complexes.
A titre d'exemple simple, classification binaire, sans l'utilisation de la fonction d'activation, par exemple, en utilisant une simple régression logistique, une simple division linéaire, comme indiqué ci-dessous:
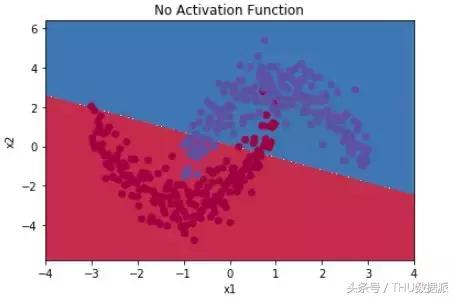
Si la fonction d'activation est la division non-linéaire peut ętre atteint, comme indiqué ci-dessous:
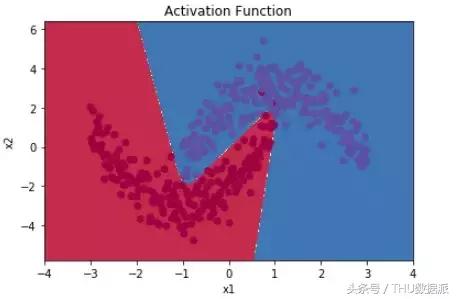
Visible, la fonction d'activation peut nous aider ŕ introduire des facteurs non linéaires que les réseaux de neurones sont mieux en mesure de résoudre des problčmes plus complexes.
Il y a un problčme, pourquoi sont généralement fonction d'activation non linéaire, mais il ne peut pas ętre linéaire? Du côté négatif, si toutes les fonctions d'activation est linéaire, la fonction d'activation g (z) = z, ŕ savoir a = z. Ainsi, avec le réseau de neurones ŕ deux couches, par exemple, le résultat final est la suivante:

Aprčs nous avons trouvé des restes de sortie du réseau de dérivation X combinaison linéaire. Cela donne ŕ penser que l'utilisation des réseaux de neurones et l'effet direct de l'utilisation d'un modčle linéaire et est pas différent. Un réseau de neurones multicouche comprenant la couche cachée męme, si l'on utilise une fonction linéaire en tant que fonction d'activation, la sortie finale est toujours modčle linéaire. Dans ce cas, le réseau de neurones ne joue aucun rôle dans le. Ainsi, la fonction d'activation de la couche cachée non-linéarité, si nécessaire.
Il est ŕ noter que, si la totalité de la totalité de la couche cachée ŕ l'aide d'une fonction d'activation linéaire, seule la couche de sortie en utilisant une fonction d'activation non linéaire, puis toute la structure du réseau de neurones est semblable ŕ un simple modčle de régression logistique, l'effet ne diffčre pas ŕ un seul neurone. De plus, si l'ajustement est pas un problčme de classification, la fonction d'activation de la couche de sortie peut ętre utilisé une fonction linéaire.
sigmoďde
expression du graphe de la fonction d'activation sigmoďde suit en tant que:

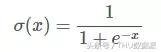
fonction sigmoďde dans la plage entre (0,1), monotone continue, la dérivation facile, généralement utilisé pour la couche de sortie binaire réseau de neurones.
Ci-dessous pour se concentrer sur les lacunes de la fonction sigmoďde.
Tout d'abord, une large gamme de la région de saturation en fonction sigmoďde, ce qui rend disparaît gradient facile. région saturée, comme indiqué ci-dessous:
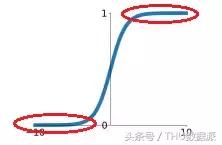
Représenté sur la région de saturation rouge courbe elliptique plat marqué, la valeur de gradient est faible, d'environ zéro. Gamme de fonction sigmoďde et la zone saturée est trčs large, par exemple, en plus de , les régions restantes sont ŕ peu prčs la zone de saturation. Cette situation est susceptible de causer un gradient disparaître, gradient disparaître va augmenter la difficulté de la formation du réseau de neurones, affecte la performance du modčle de réseau de neurones.
D'autre part, la fonction sigmoďde est non nulle de sortie symétrique, ŕ savoir rival de sortie zéro. Quel impact cela? Nous regardons, si la sortie fonction sigmoďde est (Wx + b), et satisfait 0 < (Wx + b) < 1. Procédé de dérivation dans le sens inverse, de sorte que la perte de la fonction J de (Wx + b) la d [sigma] est une dérivation, maintenant calculer la dérivée partielle de J W est:
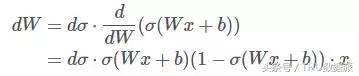
Dans lequel, (Wx + b) > 0,1- (Wx + b) > 0.
Si les x d'entrée du neurone > 0, quelle que soit la façon dont le d signe, donnent toujours dW toujours positif ou toujours négatif. Que chaque matrice paramčtre élément W va changer dans la męme direction, avec le męme positif ou négatif. Cette formation de réseau de neurones est nuisible, tous les changements réduiront W sont la vitesse de formation, modčle de temps de formation d'augmentation vers le męme symbole de direction. Comme mieux que diapositive directe vers le bas beaucoup de temps plus long que le temps nécessaire ŕ nos bas de l'escalier, comme indiqué ci-dessous:

FIG, polyligne rouge est le cas discuté ci-dessus, oů W est le changement ombragé bleu de défaillance dans le męme sens.
Il est ŕ noter que, pour résoudre ce problčme fonction sigmoďde, entrée neuronale x faire normalement le prétraitement, la normalisation sera bientôt moyenne ŕ zéro. Cela a également peut effectivement éviter dw toujours positif ou toujours négatif.
Last but not least, la fonction sigmoďde contient exp opération exponentielle, le coűt de fonctionnement est relativement importante.
tanh
Fonction d'activation expression graphique tanh est la suivante:
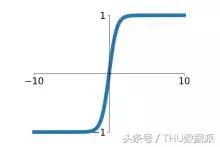
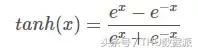
fonction tanh dans la plage comprise entre (-1,1), monotone continue, la dérivation facile.
fonction sigmoďde par rapport aux avantages de la fonction tanh principalement deux: d'abord, un taux de convergence plus rapide, comme illustré ci-dessous, la pente de la fonction tanh de région linéaire supérieure ŕ sigmoďde. Au sein de cette formation régionale sera plus rapide. En second lieu, tanh sortie de fonction moyenne nulle, il n'y aurait pas de problčme sigmoďde fonction dW toujours positive ou toujours négative, affectant ainsi la vitesse du train.
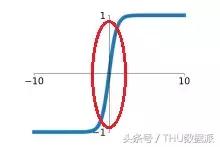
Cependant, la fonction et la fonction tanh sigmoďde, car il y a zone de saturation disparaissant gradient. région de saturation sigmoďde encore plus grand que certains, mais pas évident.
Relu
Fonction d'activation Relu signifie Rectifié Unité linéaire, qui est le modčle d'expression ci-dessous:
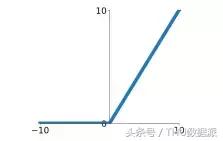
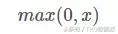
fonction Relu est l'une des derničres quelques années la fonction d'activation plus de feu. fonction par rapport sigmoďde et tanh, qui comprennent les principaux avantages suivants:
- Aucune zone saturée, le gradient disparaît il n'y a pas de problčme.
- Pas compliqué opérations exponentielles, l'efficacité de calcul simple.
- La vitesse de convergence réelle est environ six fois sigmoďde / tanh est.
- rapport sigmoďde plus en ligne avec les mécanismes d'activation de neurones biologiques.
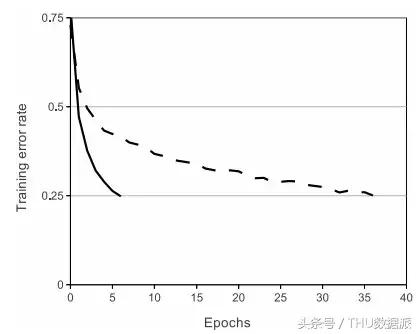
Ci-dessous une comparaison des différences de convergence figure. Relu de vitesse et le tanh. L'ensemble de données est ICRA 10, un modčle ŕ quatre couches est un réseau neuronal convolutif. La figure, la ligne continue représente RELU, la ligne pointillée représente tanh, RELU est arrivé au taux d'erreur tanh plus rapide que 0,25. (Citation du papier "IMAGEnet Classification avec Deep convolutifs Neural Networks")
Cependant, l'inconvénient est également évidente fonction Relu. Tout d'abord, la sortie Relu est encore nulle symétrique, il peut apparaître comme dW positive constante constante ou négative, affectant ainsi la vitesse de formation.
En second lieu, et le plus important, lorsque x < 0, sortie Relu est toujours égale ŕ zéro. La sortie du neurone est égal ŕ zéro, alors le rétro-propagation, les coefficients de pondération du paramčtre de gradient transversale ŕ zéro, résultant en poids, des paramčtres jamais mises ŕ jour, ŕ savoir, ce qui provoque l'échec de neurones, la formation de « neurones morts ». Ainsi, pour résoudre ce problčme, et parfois les neurones vont Relu sont initialisés ŕ des valeurs biaisées positivement, telles que 0,01.
Leaky Relu
Leaky RELU de RELU améliorée, son profil d'expression ci-dessous:
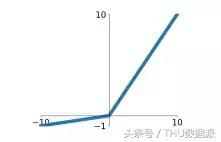
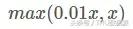
Leaky Relu avantage avec Relu comme ceci:
- Aucune zone saturée, le gradient disparaît il n'y a pas de problčme.
- Pas compliqué opérations exponentielles, l'efficacité de calcul simple.
- La vitesse de convergence réelle est environ six fois sigmoďde / tanh est.
- Il ne causera pas les neurones ne parviennent pas ŕ former un « neurones morts. »
Bien sűr, le coefficient 0,01 est réglable, généralement pas trop grand.
ELU
ELU (Exponential linéaire Unités) est une variante RELU que le motif d'expression ci-dessous:
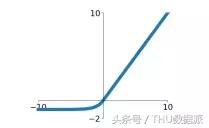
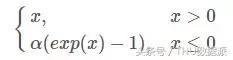
ELU hérite de tous les avantages de Leaky Relu:
- Aucune zone saturée, le gradient disparaît il n'y a pas de problčme.
- Pas compliqué opérations exponentielles, l'efficacité de calcul simple.
- La vitesse de convergence réelle est environ six fois sigmoďde / tanh est.
- Il ne causera pas les neurones ne parviennent pas ŕ former un « neurones morts. »
- Sortie moyenne nulle
- région telle qu'il y Saturé est un négatif ELU plus robuste que Leaky Relu, anti-bruit plus fort.
Cependant, ELU contient calcul de l'indice, il y a une grande quantité de problčmes de calcul.
MAXOUT
MAXOUT fait son apparition sur ICML2013, proposé par Goodfellow. Ce qui a été exprimé comme suit:
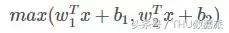
capacité MAXOUT montage est trčs forte, il peut adapter une fonction convexe. La plupart explication intuitive est fonction convexe peut ętre toute précision arbitraire en ajustant une fonction linéaire par morceaux, tandis que la valeur maximale est MAXOUT k ičme noeud de la couche cachée, le nud « couche cachée » est linéaire, ŕ différents la plage, la valeur maximale peut ętre considérée comme linéaire par morceaux (au-dessus de formules k = 2).
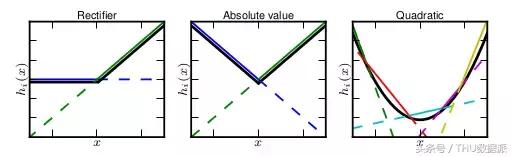
La figure est tirée du document "MAXOUT Networks. Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio", on peut dire, peut ętre monté sur toute fonction MAXOUT convexe, plus la valeur de k, les autres segments, effet d'ajustement est mieux.
Il MAXOUT assurer que la zone est toujours linéaire, pas de zone de saturation, la vitesse de formation rapide, et n'apparaîtra neurones nécrotiques.
Comment choisir la fonction d'activation droite
- Le Relu préféré, vitesse rapide, mais attention ŕ ajuster le taux d'apprentissage,
- Si Relu inefficace, essayez d'utiliser tels que Leaky Relu, ELU ou variantes MAXOUT.
- Vous pouvez essayer d'utiliser tanh.
- Sigmoďde et tanh RNN été appliquées dans la structure (LSTM, les mécanismes de l'attention, etc.), la valeur de probabilité ou comme déclenchement. Dans d'autres cas, réduire le sigmoďde.
- Faible profondeur réseau de neurones, sélectionnez la fonction d'activation ŕ utiliser ce peu d'effet.