Sebastian origine Ruder
Wang récemment compilé ŕ partir ruder.io
Qubit produit | Numéro public QbitAI
La profondeur cible de base de l'apprentissage, est de trouver la vitesse et la fiabilité d'un minimum de généralisation, le modčle est aussi un point de plus.
descente de gradient stochastique (SGD) La méthode proposée en 1951 par Robbins et Monro , il a été 60 ans d'histoire. Dans l'étude actuelle de la recherche approfondie, cette approche est critique, est généralement utilisé dans le processus de retour de propagation.
Ces derničres années, les chercheurs ont proposé un certain nombre de nouveaux algorithmes d'optimisation, utilise une équation différente pour mettre ŕ jour les paramčtres du modčle. 2015 Kingma et Ba proposé méthodes Adam , il peut ętre considéré comme l'un de l'algorithme d'optimisation les plus couramment utilisés. Cela suggčre que, du point de vue des travailleurs, l'apprentissage machine, la meilleure façon d'apprendre la profondeur de l'optimisation restent en grande partie les męmes.
Cependant, il y a beaucoup de nouvelles façons d'augmenter cette année, ce qui peut avoir une incidence sur la méthode suivante d'optimisation du modčle utilisé. Dans cet article, Ruder de son point de vue, a présenté le travail et les directions possibles pour la méthode d'optimisation apprentissage en profondeur édifiante. En lisant cet article, vous connaissez avec SGD et la méthode d'adaptation des taux d'apprentissage, comme les méthodes Adam.
Amélioration des méthodes Adam
Bien que, comme Adam une telle méthode du taux d'apprentissage adaptatif utilise une gamme trčs large, cependant, la reconnaissance de l'objet et MT et d'autres travaux de recherche, de nombreux résultats de la recherche de pointe utilisent encore des méthodes traditionnelles pour conduire le montant de SGD.
Certaines des raisons données par Wilson et al. Dans la derničre étude pour expliquer, par rapport ŕ la quantité de méthode d'entraînement SGD, le taux d'apprentissage adaptatif convergera ŕ une autre méthode de la valeur minimale, et les résultats ne sont généralement pas idéal. Dérivé de l'expérience, la reconnaissance d'objets, et le caractčre niveau des tâches langage de modélisation telles que l'analyse de la syntaxe, la valeur minimale obtenue par la méthode d'apprentissage adaptatif est généralement pire que la valeur minimum de quantité d'entraînement obtenue par la méthode SGD. Cela semble contre-intuitif, parce que la méthode Adam a un bon mécanisme de convergence, et son taux d'apprentissage adaptatif remplirait mieux que la méthode traditionnelle de SGD. Cependant, Adam et autre méthode du taux d'apprentissage adaptatif a aussi des limites.
Découplage poids d'affaiblissement
Dans certains jeux de données, Adam méthode de généralisation d'une différence que le montant de SGD pour promouvoir la cause possible atténuation du poids (weight decay) . Pondčre les problčmes d'atténuation couramment utilisés pour la classification d'image, ŕ savoir, aprčs chaque mise ŕ jour des paramčtres, le taux d'atténuation en poids multipliée par le t en poids, dans lequel le taux d'atténuation d'un peu moins de 1 Wt:
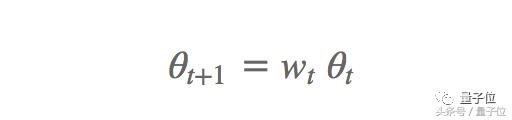
Cela empęche le poids devient trop importante. Ainsi, le poids d'atténuation peut ętre comprise comme un terme de régularisation L2, le taux d'atténuation en fonction du poids appliqué sur la perte en poids:
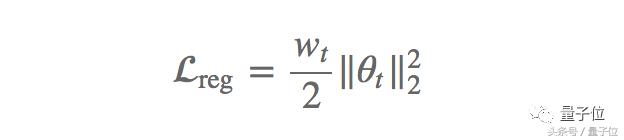
méthode de réduction de poids est généralement utilisé comme terme de régularisation, soit modifier directement le gradient, fonction habituellement appelée dans plusieurs bibliothčques de réseau de neurones. Adam et équations impulsion de mise ŕ jour algorithme, l'autre par le męme élément est multiplié par les valeurs de gradient de modification d'atténuation, les poids affaiblissement L2 régularisation pas. Ainsi, Loshchilov Hutter et que « découplage carie poids » , le męme que défini ŕ l'origine, mis ŕ jour aprčs chaque gradient de mise ŕ jour des paramčtres par cette méthode en 2017.
Et la quantité de poids d'entraînement procédé d'atténuation SGD (SGDW) mise ŕ jour de gradient comme suit:
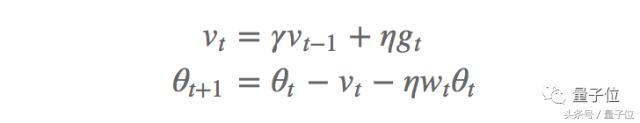
Dans lequel, [eta] est le taux d'apprentissage, le troisičme terme est le découplage de la deuxičme valeur de poids équation d'atténuation. De męme, nous obtenons des méthodes Adam (AdamW) des valeurs d'atténuation pondérées:
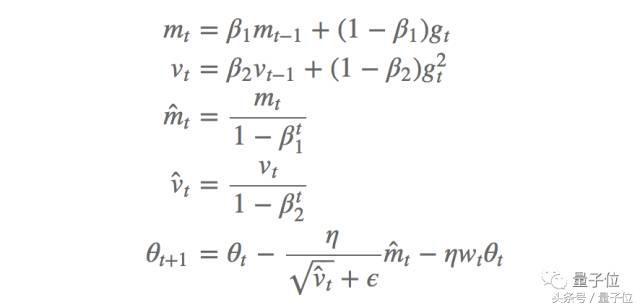
Dans lequel, mt et mt est une premičre erreur de synchronisation et son estimation de correction, et vt vt second écart temporel et l'écart est corrigé estimation, beta1 et 2 sont le taux de décroissance correspondant, et la męme valeur de poids est ajoutée terme d'amortissement. Les auteurs disent que cette approche améliore considérablement la capacité de la méthode Adam de généralisation, et comparable ŕ la quantité des travaux de méthode conduit SGD sur l'ensemble des données de classification d'images.
De plus, le processus de sélection et il pčse le taux d'apprentissage de la désintégration du processus de sélection sont séparés, ce qui peut mieux atteindre l'optimisation ultra-paramčtre, car le paramčtre ne dépend ultra-moderne plus les uns des autres. Il est également ŕ mettre en uvre séparément de l'atténuation du processus de mise en uvre de l'optimisation du poids, ce qui contribue ŕ construire un code plus compact et réutilisable, référence fast.ai mise en uvre AdamW / SGDW (https://github.com/fastai/fastai/ traction / 46 / fichiers).
moyenne mobile exponentielle fixe
Des études récentes (Dozat et Manning, 2017 , et Lainé Aila, 2017 ) valeurs trouvées expérimentalement diminuent 2 affectent la contribution de la moyenne mobile exponentielle de la derničre méthode des moindres carrés gradient d'Adam. En général, la valeur par défaut est 0,999 2, aprčs avoir défini ou 0,990,9, de meilleurs résultats dans différentes tâches, ce qui suggčre qu'il peut y avoir des problčmes moyenne mobile exponentielle.
IPSC 2018 est en cours d'examen dans un article sur la convergence d'Adam et (https://openreview.net/forum?id=ryQu7f-RZ) Au-delŕ étudié le problčme, en notant la moyenne mobile exponentielle du gradient au carré est passé l'apprentissage adaptatif une autre raison de la généralisation de la méthode de faible taux. Le procédé d'adaptation de taux d'apprentissage de base doit ętre mise ŕ jour d'une moyenne mobile exponentielle de paramčtre de gradient au carré passé, par exemple Adadelta, RMSprop et Adam. L'indice moyen de la contribution de la recherche, de la motivation de cette idée est trčs bonne, il peut empęcher le taux d'apprentissage que la formation devient extręmement faible, ce qui est la méthode Adagrad des défauts critiques. Cependant, la pente de la mémoire ŕ court terme dans un panier ŕ linge dans d'autres cas.
Lorsque la méthode Adam converge vers une solution sous-optimale, nous avons observé un certain nombre de petits lots d'échantillons a contribué gradient de l'information importante et efficace, mais cela arrive rarement, l'indice en moyenne réduire leur impact, ce qui dans le modčle de faible convergence . Auteur donne d'un simple problčme d'optimisation convexe, nous pouvons voir les méthodes Adam ce phénomčne existe aussi.
Les auteurs proposent un nouvel algorithme AMSGrad pour résoudre ce problčme, il utilise le gradient maximum du carré du passé aux paramčtres de mise ŕ jour, plutôt que l'indice moyen précédent. Procédé de mise ŕ jour AMSGrad suit le procédé ci-dessus sans estimation de correction de déviation:
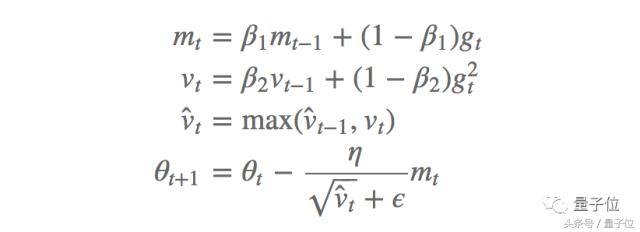
Les expériences montrent que, sur un petit ensemble de données et ensemble de données 10-ICRA, cette méthode est mieux que la performance de la méthode Adam.
Ajuster le taux d'apprentissage
Dans de nombreux cas, on n'a pas besoin d'améliorer et d'adapter la structure du modčle, mais les paramčtres ultra-ajustement. Une partie des recherches les plus récentes dans le spectacle de modélisation linguistique par rapport ŕ des modčles plus complexes, LSTM de réglage des paramčtres et les paramčtres de régularisation peut obtenir les performances les plus avancées.
Dans l'optimisation de l'étude approfondie, un paramčtre super important est le taux d'apprentissage . En effet, dans la méthode SGD, la nécessité de construire un protocole de recuit de taux d'apprentissage approprié pour obtenir un bon minimum de convergence. On pourrait penser qu'une telle méthode comme le taux d'apprentissage adaptatif d'Adam, différents taux d'apprentissage est plus robuste, car ces méthodes sont le taux d'apprentissage auto-renouvellement. Cependant, męme avec ces méthodes, bon taux d'apprentissage et le meilleur taux d'apprentissage peut varier considérablement (Andrej Karpathy compte vérifié dit que le meilleur taux d'apprentissage était 3e-4 https://twitter.com/karpathy/status / 801621764144971776).
Zhang une étude en 2017 a indiqué que , aprčs ajustement des taux d'apprentissage et dynamique des paramčtres de protocole de recuit, la méthode de performance Adam SGD gagner un combat, et une convergence plus rapide. D'autre part, on peut penser que les méthodes Adam de taux d'apprentissage taux d'apprentissage adaptatif peut imiter le recuit, mais un programme de recuit clair est toujours utile. Parce que, si nous apprenons la méthode de recuit SGD pour ajouter Adam, mieux il peut faire mieux que les méthodes de SGD dans les tâches de traduction automatique, et une convergence plus rapide .
En fait, le programme de recuit de taux d'apprentissage semble ętre un nouveau projet de long métrage, parce que nous avons constaté que le taux de recuit pour améliorer le programme d'apprentissage pour améliorer la performance du modčle de convergence finale. Vaswani, qui en 2017 donne un exemple intéressant de . Lorsque le réglage des paramčtres du modčle, nécessitent généralement une grande échelle d'optimisation ultra-paramčtre, point d'innovation de cet article est d'étudier le taux de programme recuit également considéré comme attention particuličre ŕ optimiser. Les auteurs ont utilisé une méthode Adam, oů ß1 = 0,9, et les paramčtres non définis par défaut 2 = 0,98, = 9.10, on peut dire que le taux d'apprentissage est l'un des meilleurs programme de recuit:
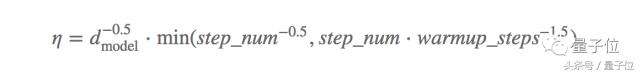
Dans lequel dmodel est le nombre de paramčtres du modčle, et warmup_steps 4000.
Smith et al. Dans un autre document en 2017 révčle une corrélation intéressante entre le taux d'apprentissage et la taille des lots. Les deux paramčtres de super-sont généralement considérés comme indépendants les uns des autres, mais ils ont constaté que la réduction du taux d'apprentissage est équivalent ŕ l'augmentation de la taille des lots, ce qui peut augmenter la vitesse de formation parallčle. Round, nous pouvons réduire le nombre de mise ŕ jour du modčle, et d'améliorer la vitesse de formation en augmentant le taux d'apprentissage et de mise ŕ l'échelle de la taille du lot. Cette constatation influe sur le processus de formation étude approfondie massif, en partant du principe n'a pas besoin d'ętre le réglage ultra-paramčtre, régler ŕ nouveau le programme de formation existant.
Démarrage ŕ chaud (redémarre chaud)
SGD redémarre avec la méthode
Une autre méthode efficace est récemment proposé SGDR , Loshchilov Hutter et remplacé par le systčme de taux d'apprentissage de recuit en mode redémarrage ŕ chaud, une méthode pour améliorer le SGD. Chaque fois que vous redémarrez, le taux d'apprentissage est initialisé ŕ une certaine valeur, puis progressivement diminué. Il est important, cela peut redémarrer ŕ tout moment, car l'optimisation ne démarre pas ŕ partir de zéro, mais ŕ partir des paramčtres du modčle sur une convergence étape a commencé. La clé est d'ajuster le taux d'apprentissage par un programme de recuit cosinus positif, ce qui diminuera rapidement le taux d'apprentissage, comme suit:
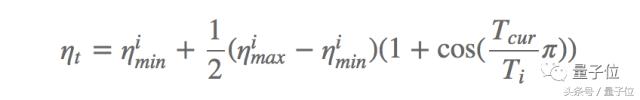
Ce qui imin et l'intervalle de changement imax est le taux d'apprentissage du i-ičme formation, Tcur représente le nombre d'itérations ont été effectuées depuis le dernier redémarrage et Ti indique le nombre d'itérations pour le prochain redémarrage. taux d'apprentissage par rapport ŕ un recuit classique, la méthode de redémarrage thermique (Ti = 50, Ti = 100 et Ti = 200) Les performances tel que représenté sur la Fig.
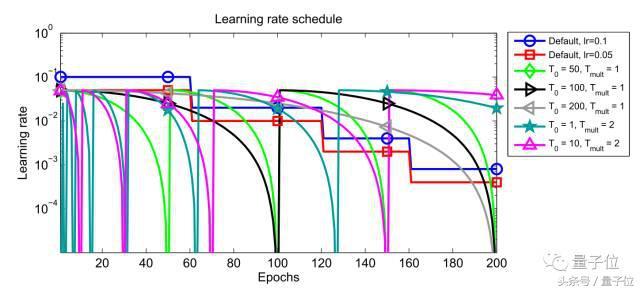
Figure 1: Joignez-vous ŕ redémarrage des changements de performance de la méthode du taux d'apprentissage
Aprčs le redémarrage, avec une éjection de paramčtre de taux d'apprentissage initial élevé de la racine ŕ une valeur minimale d'un déjŕ convergé vers différentes zones de la surface de la perte de fonction. Ce mécanisme de recuit positif afin que le modčle peut converger rapidement vers une nouvelle et de meilleures solutions. On a également constaté l'observation que le temps nécessaire pour la méthode de descente de gradient stochastique ŕ l'aide d'un redémarrage ŕ chaud de 2 ~ 4 fois moins que la méthode de recuit de taux d'apprentissage, et peut atteindre comparable ou de meilleures performances.
L'utilisation d'un cycle de redémarrage ŕ chaud est aussi appelé le recuit de taux d'apprentissage modifie le taux d'apprentissage, ŕ l'origine développé par Smith proposé. les étudiants fast.ai sont donnés deux autres articles discutent du cycle de redémarrage ŕ chaud et changer le taux d'apprentissage, ŕ l'adresse suivante:
https://medium.com/@bushaev/improving-the-way-we-work-with-learning-rate-5e99554f163b
instantané intégré (ensembles instantanés)
L'intégration est un instantané méthode ingénieuse récemment proposée par Huang , ŕ savoir l'utilisation d'un ensemble de redémarrage ŕ chaud assemblé, et le coűt supplémentaire pratiquement aucun d'un modčle unique au cours de la formation. Cette méthode peut ętre formé ŕ un modčle unique, en tant que systčme de recuit de convergence cosinus vu précédemment, puis enregistrez les paramčtres du modčle, et redémarrage ŕ chaud, ces étapes sont parfois répétées M. Enfin, tous les instantanés enregistrés constituent un modčle de l'ensemble. On peut voir ŕ. La figure 2, afin d'optimiser la différence de performance processus d'intégration de SGD instantané commun de performance sur la surface d'erreur.
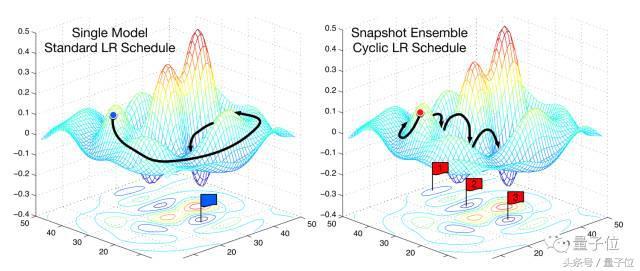
Figure 2: SGD et de l'intégration de l'instantané
En général, le succčs de l'intégration dépend de la diversité de chaque portefeuille modčle. Ainsi, l'intégration de l'instantané cosinus dépend de la capacité du programme de recuit, de sorte que le modčle peut ętre redémarré aprčs chaque Converge ŕ différents optima locaux. Les auteurs montrent que cela est vrai dans la pratique, et obtenu de bons résultats sur 10 ICRA, et 100-ICRA SVHN.
restart Adam avec la méthode
Dans un premier temps la méthode de démarrage ŕ chaud ne s'applique pas ŕ Adam, puisque son atténuation de poids est pas normal. Aprčs l'atténuation des poids fixes, Loshchilov Hutter et de la męme maničre que le 2017 ŕ Adam étendent dans un redémarrage ŕ chaud. Dans lequel, imin = 0, imax = 1, pour donner:
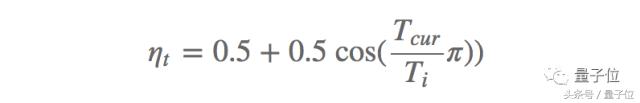
Sélectionner un plus petit Ti (entre 1 et 10 itérations) et multiplié par un coefficient Tmult ŕ chaque redémarrage, tel que le 2 recommande de commencer.
optimisation apprentissage
L'un des plus intéressants sont les papiers Andrychowicz, qui l'an dernier auteur Apprendre ŕ apprendre par descente de gradient par descente de gradient, est les utilisateurs reddit sélectionnés « 2016 Best Paper » . Ils ont formé optimiseur LSTM pour mettre ŕ jour les paramčtres principaux au cours de modčle de formation. Malheureusement, optimiseur LSTM d'apprentissage individuel, ou utiliser une optimisation optimiseur LSTM pré-formation augmentera considérablement la complexité de la formation du modčle.
Cette année, il y a un « apprendre ŕ apprendre » trčs influent du papier, l'utilisation LSTM pour générer la structure de modčle de langage spécifique au domaine de . Alors que le processus de recherche nécessite beaucoup de ressources, mais la structure peut ętre trouvée pour remplacer la structure existante. Le processus de recherche a été prouvé ętre efficace et obtenir des résultats dans la plupart des modčles linguistiques de pointe, et a réalisé un résultat trčs concurrentiel sur 10 ICRA.
La męme stratégie de recherche peut ętre appliquée ŕ tout autre domaine déjŕ défini ses processus clés manuellement, ce qui est un champ de l'algorithme d'optimisation de l'apprentissage en profondeur. Comme nous l'avons vu, l'algorithme d'optimisation est conforme ŕ cette rčgle: ils ont utilisé dans l'exponentielle passé en mouvement pente moyenne (comme dynamique) et la moyenne mobile exponentielle du gradient au carré passé (comme Adadelta, RMSprop, Adam) une combinaison de .
Bello et al définit la langue d'un domaine particulier, l'optimisation des primitives utiles, telles que la moyenne mobile exponentielle. Ensuite, ils échantillonnés dans tout l'espace possible de mettre ŕ jour les rčgles des rčgles de mise ŕ jour, la mise ŕ jour des rčgles ŕ utiliser ce modčle de formation et met ŕ jour le contrôleur RNN en fonction de la performance sur le modčle de formation du jeu de test. processus complet illustré ŕ la figure 3.
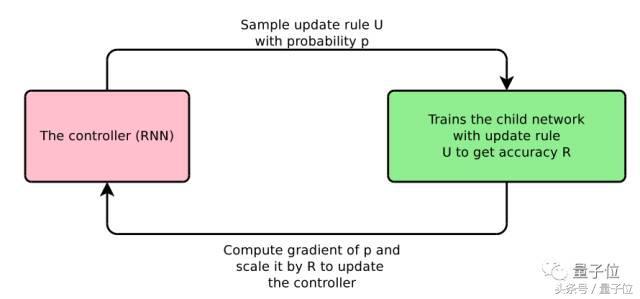
Figure 3: optimisation de la recherche nerveuse
En particulier, ils définit également deux équations de mise ŕ jour, ŕ savoir PowerSign et AddSign. formule de mise ŕ jour PowerSign est la suivante:
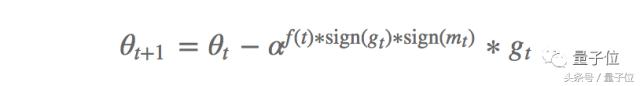
Dans lequel, [alpha] est un hyper-paramčtres sont généralement fixés ŕ e ou 2 f (t) est définie sur 1 ou fonction de décroissance (pas de temps t pour ré-exécuter une chaîne linéaire, cyclique ou atténuation), oů m est la moyenne mobile de gradient passé valeur. En rčgle générale, la mise en = e, et aucune atténuation. Notes, la mise ŕ jour par aF (t) ou 1 / aF (t) est mis ŕ l'échelle gradient et la direction de gradient selon que la moyenne mobile de la męme. Cela montre que la dynamique du passé similaire similitude entre le gradient de courant et le gradient est d'optimiser le modčle d'apprentissage en profondeur des informations critiques.
AddSign défini comme suit:
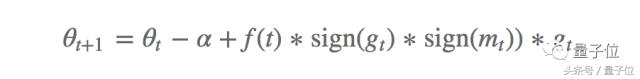
Dans lequel, [alpha] est généralement fixée ŕ 1 ou 2, similaire ŕ ce qui précčde, l'échelle est mise ŕ jour ŕ a + f (t) ou -f (t), en fonction de la consistance de la direction de gradient. Les auteurs notent que, la performance PowerSign et AddSign sur 10 est-ICRA supérieur ŕ Adam, le montant RMSprop de SGD et la méthode de conduite, et peut se traduire ainsi ŕ d'autres tâches, telles que IMAGEnet classification et la traduction automatique.
généralisation comprendre
L'optimisation et la capacité de généralisation sont étroitement liés, car le modčle détermine la valeur minimale de la convergence de la capacité de généralisation du modčle. Par conséquent, le problčme d'optimisation du progrčs et de la compréhension de la généralisation minimum théorique de ces progrčs est étroitement lié, et peut comprendre plus profondément la profondeur de l'apprentissage capacité de généralisation.
Cependant, notre compréhension de la profondeur de la capacité de généralisation du réseau de neurones est encore trčs simple et évidente. Des études récentes montrent que le nombre de valeurs minimales locales peut ętre une fonction du nombre de paramčtres augmente de façon exponentielle . Compte tenu de la structure actuelle étude approfondie d'un grand nombre de paramčtres, tels modčles peuvent converger et une meilleure capacité de généralisation, d'autant plus qu'ils peuvent se rappeler exactement entrée aléatoire , qui semble regarder incroyable .
Keskar et al. est la raison pour laquelle la capacité de généralisation de minimum pauvres, ils ont également fait remarquer que la descente de gradient de lots valeur minimale nette trouvé avec erreur haute généralisation. Ceci est intuitive, parce que nous voulons que cette fonction est lisse généralement, minima pointus semblent montrer une surface trčs irréguličre de l'erreur respective. Cependant, des études récentes ont montré que la netteté ne peut pas ętre un bon indicateur, car il montre que minimum local peut ętre une bonne généralisation , et Eric Jang de Quora répond également discuté du contenu sur le lien suivant:
https://www.quora.com/Why-is-the-paper-%E2%80%9CUnderstanding-Deep-Learning-Requires-Rethinking-Generalization%E2%80%9D-important/answer/Eric-Jang?srid = dWc3
Il y a un affichage RPR 2018 papier (https://openreview.net/forum?id=r1iuQjxCZ), ŕ travers une série d'analyses d'ablation, l'activation a montré dans un espace de modčle a une dépendance sur une seule direction, ŕ savoir, une seule unité ou fonctionnalité carte d'activation il est un bon indicateur de la capacité de généralisation. Ils ont prouvé que ce modčle applique le modčle de formation sur différents ensembles de données, ainsi que divers degrés de dommages ŕ l'étiquette. Ils ont également constaté que l'ajout Dropout n'a pas aidé ŕ résoudre ce problčme, et la normalisation des lots entravés la dépendance unilatérale.
Bien que ces études indiquent qu'il ya encore beaucoup nous ne savons pas la profondeur des connaissances pour optimiser l'apprentissage, mais gardez ŕ l'esprit, et d'assurer la convergence d'un grand nombre de travaux existants et des idées dans l'optimisation convexe, dans une certaine mesure, il peut également ętre appliquée ŕ un problčme d'optimisation non convexe dans. NIPS 2016 beaucoup de tutoriel d'optimisation sur les nombreux domaines de travail théorique a eu une trčs bonne critique.
conclusion
J'espčre que le contenu ci-dessus peut ętre un bon résumé de quelques-uns de l'année écoulée dans le développement de problčmes d'optimisation de la profondeur convaincante. S'il y a d'autres aspects des disparus, ou il y a une erreur dans l'article, s'il vous plaît me contacter.
25 documents mentionnés dans le texte, vous pouvez aller ŕ la fin de la création d'auto-originale: http: //ruder.io/deep-learning-optimization-2017/
recrutement sincčre
Qubits recrutent éditeur / journaliste, basé ŕ Zhongguancun de Beijing. Nous attendons de talent, des étudiants enthousiastes de nous rejoindre! Détails, s'il vous plaît interface de dialogue qubit numéro public (QbitAI), réponse mot "recrutement".
Qubit QbitAI · manchettes sur la signature de
' « suivre les nouvelles technologies AI dynamiques et de produits