Ces derniŤres annťes, avec le dťveloppement rapide de la profondeur de l'apprentissage et un large ťventail d'applications potentielles, de plus en plus d'attention par la technologie de lecture labiale basťe sur la vision informatique, il a de nombreuses applications, telles que la reconnaissance vocale auxiliaire, l'authentification biomťtrique dans la pratique, l'aide malentendants et ainsi de suite.
Mais la difficultť est trŤs ťlevťe t‚che la lecture labiale, est de savoir comment obtenir efficacement un point clť des informations de mouvement des lŤvres, ainsi que la rťsistance ŗ identifier les difficultťs causťes par le geste, la lumiŤre change, l'apparence du haut-parleur perturbations, changement de vitesse de la parole, etc. De plus, comment l'image des lŤvres comporte le texte et le vocabulaire de distinguer avec prťcision entre homophones ou association est aussi un dťfi.
De l'Universitť du Zhejiang, l'Acadťmie chinoise des sciences chercheurs traitement de l'information intelligente et clť de laboratoire de l'Institut de technologie de l'informatique de ces problŤmes, les caractťristiques locales et globales de la couche d'information de sťquence de couches dans la retenue mutuelle, afin d'amťliorer les caractťristiques visuelles et le contenu de la lŤvre vocale relation.
En testant sur certains des principaux ensembles de donnťes, l'ťquipe mťthode proposťe devrait en mÍme temps a une bonne capacitť d'identifier et de robustesse, afin d'obtenir la lecture labiale efficace.

Carte | Niveau de lecture labiale mot est une t‚che difficile. (A), le mot de sous-titres de trame rťelle ę environ Ľ comprend seulement un cadre ŗ l'ťtape de temps T = 12 ~ 19. (B) la mÍme ťtiquette de mot change toujours avec l'apparition en constante ťvolution. (Source: arXiv)
branche de la lecture labiale de l'art il y a un niveau technique important vocabulaire de lecture ŗ savoir la lŤvre pour cette t‚che, la nťcessitť d'une vidťo d'entrťe avec un commentaire pour chaque ťtiquette de mot unique, bien qu'il y ait d'autres mots dans la mÍme vidťo, comme indiquť ci-dessus: (a) ťchantillons vidťo comprenant un total de 29, a ťtť annotťes comme ę environ Ľ, mais le mot ę environ Ľ trame comprenant seulement le temps de l'ťtape rťelle T = 12 ~ 19 du cadre, cela correspond de trame ŗ des intervalles avant et aprŤs le mot ę juste Ľ et " TEN ęplutŰt que Ľ sur Ľ. Sur la base de l'ťtude de la lŤvre visuelle, nous avons toujours difficile de tirer des limites exactes d'un mot.
Cette fonction nťcessite un bon modŤle pour apprendre ŗ lire sur les lŤvres caractťristiques potentielles mais cohťrentes dans la mÍme ťtiquette de mot rťflťchi autre vidťo, permettant de se concentrer plus efficacement des images clťs, et moins d'attention ŗ un autre cadre sans rapport.
En plus des mots de dťfi aux limites imprťcises, les ťchantillons vidťo correspondant au mÍme mot d'ťtiquette est toujours une grande variťtť et le changement d'apparence, tels que (b), toutes ces caractťristiques sont nťcessaires pour rťsister au modŤle de sťquence de lecture labiale bruit, capturant ainsi le mode dans les mÍmes conditions de parole potentiels diffťrents.
En mÍme temps, en raison de la surface effective limitťe de l'action des lŤvres, des mots diffťrents Speak peut prťsenter un phťnomŤne similaire. la prťsence d'homonymie, diffťrents mots peuvent sembler identiques ou trŤs similaires, a augmentť le nombre de difficultťs supplťmentaires, ces attributs peuvent Ítre trouvťs dans la diffťrence exigences du modŤle ŗ grain fine associťs au niveau de la trame des mots diffťrents pour distinguer chaque mot en particulier.
Pour rťsoudre ce problŤme, les chercheurs ont introduit la maximisation de l'information mutuelle (MIM) ŗ diffťrents niveaux pour aider ŗ la robustesse du modŤle d'apprentissage et de reprťsentation distinguť, afin d'obtenir une lecture labiale efficace.
Dans un aspect, en appliquant des contraintes locales afin de maximiser l'information mutuelle (LMIM) dans lequel ŗ chaque pas de temps pour contraindre gťnťrť, une forte corrťlation entre celle-ci et le contenu vocal, augmentant ainsi le mouvement du modŤle de lŤvres ont trouvť la possibilitť de bien, nuances entre les mots sonnant similaires, tels que ę dťpenses Ľ et ę passer Ľ, d'autre part, l'introduction de la sťquence d'information mutuelle des contraintes de maximisation (GMIM) au niveau mondial, de sorte que le modŤle peut Ítre plus pertinent de faire la distinction entre le contenu de la parole images clťs et toutes sortes de bruit se produisant au cours de parler moins.
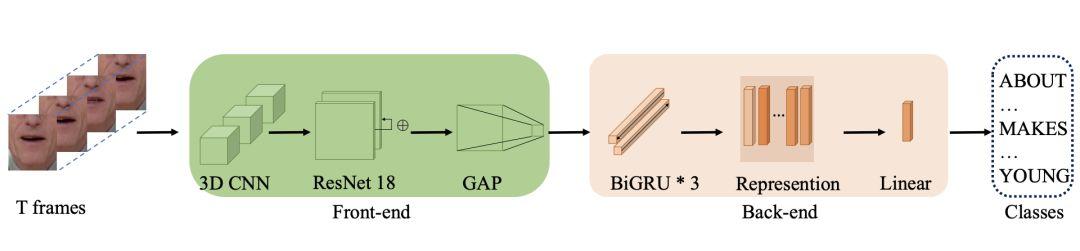
†Carte | architecture de base (Source: arXiv)
En outre, GMIM forÁant le modŤle ŗ apprendre diffťrents ťchantillons de modŤle global potentiel compatible avec une ťtiquette de mot, tout robuste aux changements de posture, l'ťclairage, et d'autres conditions non liťes; LMIM peut amťliorer chaque grains fins pas de temps mots de sport du renforcer davantage les diffťrences entre les diffťrents mots. En combinant ces deux types de contraintes, le modŤle peut automatiquement dťcouvrir et cadre efficace important de distinguer entre le mot cible, tout en ignorant autre cadre sans rapport, afin d'amťliorer encore la prťcision de la reconnaissance.

Carte | identifier les amťliorations aux mots similaires sondage (source: arXiv)
Enfin, l'ťquipe en deux donnťes mot-niveau ŗ grande ťchelle dťfinit LRW et la lecture labiale mťthodes de modŤle de reconnaissance traditionnels lŤvre LRW-1000 homologues ont fait une ťvaluation comparative de l'ťchantillon proposť les deux ensembles de donnťes sont d'une variťtť de collection d'ťmissions de tťlťvision et les conditions de prťsentations varient considťrablement, couvrant un large ťventail de conditions d'ťclairage, y compris la condition de parler, la rťsolution, la position, le sexe, etc., maquillage.
LRW publiť en 2016, y compris l'ťchantillon ŗ lŤvres 500 mots, plus de 1000 le nombre de haut-parleurs d'instances, la formation devrait atteindre 488766, le nombre d'instances de chaque ensemble de vťrification et de test pour 25000; LRW-1000 jeu de donnťes est mot-niveau des ensembles de donnťes de rťfťrence d'une grande distribution naturelle, un total de 1000 mots chinois, un total d'environ 718018 ťchantillons d'exemple, la durťe d'environ 57 heures, mais l'ensemble de donnťes est destinť ŗ couvrir les modŤles de la parole naturelle changement dans des conditions diffťrentes d'imagerie et d'inclure des applications pratiques difficultťs rencontrťes.

Carte | par rapport au champ prťcťdent des plus de rťsultats modŤle test avancť (Source: arXiv)
Le jeu de donnťes LRW, aprŤs l'introduction LMIM, en fonction de la prťcision au niveau de rťfťrence a augmentť d'environ 1,19%, LMIM devrait capturer plus ŗ grains fins et des traits distinctifs de la t‚che principale, tout en introduisant GMIM mis pour amťliorer la prťcision de 84,41%, principalement gr‚ce ŗ son accent diffťrent sur diffťrents cadres.
Cependant, dans les donnťes LRW-1000 dťfinies en raison de sa voix plus grande aux conditions changeantes, y compris les conditions d'ťclairage, la rťsolution, l'‚ge du haut-parleur, la position, le sexe, le maquillage, l'industrie avait les meilleurs rťsultats des tests de seulement 38,19%. Obtenir de bons rťsultats de reconnaissance sur cet ensemble de donnťes reste un dťfi, de nouveaux modŤles ont acquis une prťcision de reconnaissance 38,79% de, lťgŤrement mieux que les derniers rťsultats disponibles.
Les rťsultats montrent que la mťthode proposťe dans cette ťquipe sans l'utilisation de donnťes supplťmentaires ou d'un modŤle de prť-formation complťmentaire, par rapport aux deux autres ensembles de donnťes difficiles modŤle de reconnaissance des lŤvres, montrant un nouveau statut de performance en temps rťel de . En outre, l'ťquipe a dit, la mťthode peut ťgalement Ítre facilement modifiť comme modŤle pour d'autres t‚ches, en fournissant des informations intťressantes pour l'ťtude d'autres t‚ches.