
Dingdong ~ Vous avez ťtť touchť par le bien-Ítre! ņ partir de maintenant, "2020 AI Developer Ten Thousand Conference" 299 billets sont gratuits! Accťdez ŗ la page d'inscription [2020 AI Developer Ten Thousand Conference (Online Live Tickets) -IT Training Live-CSDN Academy], cliquez sur "S'inscrire maintenant", utilisez le code de rťduction "AIP1410" lors du rŤglement, le prix deviendra "0" yuan !

Auteur | Wang Jingdong
Finition | Aspirine
Produits | Intelligence artificielle ŗ la une (ID public: AI_Thinker)
Les rťseaux de neurones convolutifs se sont dťveloppťs ŗ pas de gťant au cours des derniŤres annťes et bien que leurs effets sur des t‚ches telles que la reconnaissance d'images s'amťliorent de plus en plus, la complexitť du modŤle continue d'augmenter. Les rťseaux de neurones convolutionnels plus profonds et plus complexes nťcessitent beaucoup de stockage et de ressources informatiques, donc la conception de rťseaux de neurones convolutionnels efficaces est un problŤme trŤs important et fondamental, et l'ťlimination de la redondance de convolution est le problŤme principal de ce problŤme. Une des solutions.
Comment ťliminer la redondance de l'ťlimination de la convolution? Nous avons invitť le Dr Jingdong Wang, chercheur principal du Visual Computing Group du Microsoft Asia Research Institute, pour expliquer la mťthode basťe sur la convolution de groupe entrelacťe publiťe dans ICCV 2017 et CVPR 2018.
Ce qui suit est le contenu de la classe ouverte, organisť par le camp de base de la technologie AI, et lťgŤrement supprimť:

La raison du succŤs de l'apprentissage en profondeur
Un article sur ęScienceĽ en 2006 - Rťduire la dimensionnalitť des donnťes avec les rťseaux de neurones, est un article trŤs important qui promeut le dťveloppement de l'apprentissage en profondeur au cours de la derniŤre dťcennie. Lorsque cet article est sorti, de nombreuses personnes dans le domaine de l'apprentissage automatique prÍtaient attention ŗ ce travail, mais il n'a pas obtenu de trŤs bons rťsultats dans le domaine de la vision par ordinateur, il n'a donc pas attirť l'attention des personnes dans le domaine de la vision par ordinateur.
La mťthode d'apprentissage en profondeur a vraiment attirť l'attention dans le domaine de la vision par ordinateur en raison d'un article 2012-ImageNet Classification avec Deep Convolutional Neural Networks. Cet article a remportť le trŤs important concours ImageNet dans le domaine de la vision par ordinateur en utilisant la mťthode des rťseaux de neurones convolutionnels profonds. Les champions avant 2012 sont basťs sur SVM (support vector machine) ou sur des mťthodes forestiŤres alťatoires.
En 2012, Hinton et son ťquipe ont connu un grand succŤs gr‚ce ŗ des rťseaux profonds, dans quelle mesure ce succŤs? Il sagit dune augmentation de plus dune douzaine de points de pourcentage par rapport au rťsultat de lannťe prťcťdente, ce qui reprťsente une amťlioration trŤs impressionnante et remarquable. En raison du succŤs remportť par le concours ImageNet, le domaine de la vision par ordinateur a commencť ŗ accepter des mťthodes d'apprentissage en profondeur.
En comparant ces deux articles, bien que nous les appelions apprentissage en profondeur, la diffťrence est en fait assez grande. Surtout en 2012, cet article s'intitule ęDeep Convolutional Neural NetworkĽ, abrťgť en ęCNNĽ. CNN n'ťtait pas nouvellement proposť dans cet article en 2012. Dans les annťes 1990, Yann LeCun a utilisť CNN dans la reconnaissance des nombres et a obtenu un grand succŤs, mais pendant longtemps, tout le monde n'a pas utilisť CNN comme ImageNet Le jeu jusqu'ŗ cet article. Aujourd'hui, tout le monde constate que le deep learning a dominť le domaine de la vision par ordinateur.
Pourquoi l'apprentissage en profondeur a-t-il rťussi en 2012? En fait, en plus des mťthodes d'apprentissage en profondeur ou CNN, il y a deux choses, l'une est GPU, et l'autre est ImageNet.
Cette structure de rťseau a ťtť proposťe par Hinton et ses ťtudiants en 2012. En fait, cette structure de rťseau a 8 couches, il semble que ce ne soit pas si profond, mais il ťtait trŤs difficile de former ce rťseau ŗ cette ťpoque, il a fallu une semaine pour le former, et ŗ ce moment-lŗ, d'autres ont voulu le reproduire. Le rťsultat n'est pas si simple.
AprŤs cet article, tout le monde pense que plus le rťseau de neurones est profond, meilleures seront les performances. Voici quelques emplois reprťsentatifs, passez briŤvement en revue.
Deux directions de dťveloppement de la structure du rťseau profond
approfondir

En 2014 VGG, cette structure de rťseau est trŤs simple, elle est empilťe couche par couche, et les couches sont trŤs similaires.
La mÍme annťe, Google avait une structure de rťseau appelťe "GoogLeNet". Cette structure de rťseau semble un peu plus compliquťe que la structure de VGG. Lorsque cette structure de rťseau est apparue pour la premiŤre fois, elle semblait plus compliquťe et ressemble aujourd'hui ŗ une structure ŗ plusieurs succursales. Au dťbut, l'opinion gťnťrale ťtait que cette structure de rťseau ťtait ajustťe manuellement et n'avait pas une forte promotion. Bien que GoogLeNet soit une structure de rťseau conÁue artificiellement, en fait, il y a beaucoup de choses qui mťritent d'Ítre apprises, y compris une structure multi-branche longue et courte.
En 2015, une structure de rťseau s'appelait Highway. Autoroute Cet article dit principalement que nous pouvons trŤs bien former un rťseau ŗ 100 couches ou mÍme un rťseau ŗ 100 couches. Pourquoi peut-il trŤs bien s'entraÓner? Il existe ici un concept de flux d'informations, qui peut rapidement transmettre des informations de l'avant vers la couche arriŤre via SkipConnection, et peut ťgalement transfťrer rapidement le gradient arriŤre vers l'avant lors de la propagation arriŤre. Il y a un problŤme ici, que cette connexion Skip utilise une fonction de porte, ce qui rend la difficultť de la formation rťseau profonde encore pas vraiment rťsolue.
La mÍme annťe, des collŤgues de Microsoft ont inventť un rťseau appelť "ResNet". Ce rťseau est similaire ŗ Highway dans un certain sens. Oý est-il? Il utilise ťgalement Skip Connection pour passer directement de la sortie d'une certaine couche ŗ la sortie de la couche suivante. Comparť ŗ Highway, il supprime la fonction de porte car la porte n'est pas une chose particuliŤrement bonne dans un rťseau trŤs profond. Gr‚ce ŗ cette conception, il peut trŤs bien former un rťseau de plus de 100 couches. Plus tard, il a ťtť dťcouvert que le rťseau ŗ 1000 couches peut ťgalement Ítre trŤs bien formť gr‚ce ŗ cette astuce, ce qui est trŤs remarquable.
En 2016, aprŤs l'ťmergence de GoogLeNet, Highway, ResNet, nous avons constatť qu'il ťtait trŤs important d'avoir une structure multi-branches longue et courte. Par exemple, notre travail est des filets profondťment fondus. Dans plusieurs branches, la profondeur de chaque branche est diffťrente. L'avantage de ceci est que si nous regardons cette structure sous forme de graphique, nous constatons qu'il existe plusieurs chemins de ce point d'entrťe ŗ ce point de sortie, certains chemins sont longs et certains chemins sont courts. Dans ce sens, nous pensons qu'il y a Des chemins longs et courts peuvent entraÓner des rťseaux de neurones profonds.

La mÍme annťe, nous avons trouvť un travail similaire appelť FractalNets, qui est trŤs similaire ŗ nos filets profondťment fondus.
Ce chemin est ŗ approfondir, en espťrant former trŤs bien la structure du rťseau, afin que ses performances soient trŤs bonnes, plus Skip Connection et d'autres formes pour rendre le flux d'informations trŤs bon. Bien que nous ayons trŤs bien formť le rťseau profond via Skip Connection, la profondeur pose toujours quelques problŤmes, c'est-ŗ-dire que la performance n'est pas bien jouťe, il y a donc une autre dimension, tout le monde espŤre devenir plus large.
De plus, les grands rťseaux rencontreront certains problŤmes dans la pratique. Par exemple, lorsqu'il est dťployť sur un tťlťphone mobile, on espŤre que le montant du calcul n'est pas trop grand, le modŤle n'est pas trop grand et les performances sont toujours trŤs bonnes, donc le taux de reconnaissance est trŤs ťlevť mais la trŤs grande structure du rťseau rencontre quelques difficultťs dans les applications pratiques.
Plusieurs mťthodes pour simplifier la structure

Une autre faÁon consiste ŗ simplifier la structure du rťseau et ŗ ťliminer la redondance ŗ l'intťrieur. Parce que tout le monde pense qu'il existe une forte redondance dans la structure du rťseau de neurones profond, l'ťlimination de la redondance est un domaine que j'ai trouvť trŤs intťressant de faire ces derniŤres annťes en raison de son utilisation pratique.
Opťration de convolution
L'opťration de convolution dans CNN correspond en fait ŗ la multiplication des vecteurs matriciels. Ce que tout le monde fait est essentiellement d'ťliminer la redondance dans la convolution.

Passons en revue la convolution. L'image ŗ droite: Il y a plusieurs canaux dans le CNN, chaque canal est en fait un rťseau bidimensionnel, et chaque position a une valeur, que nous appelons la "valeur de rťponse". Il contient quatre canaux, ce qui ťquivaut en fait ŗ un tableau tridimensionnel. En prenant cela (chaque position) comme centre, prenez un petit bloc de 3 ◊ 3, 3 ◊ 34 canaux, puis il y a tellement de valeurs de 3 ◊ 3 ◊ 4, puis nous tirons ces nombreuses valeurs dans un 3 ◊ 3 ◊ 4 = vecteur ŗ 36 dimensions. La convolution a un noyau de convolution. Le noyau de convolution correspond ŗ une quantitť horizontale. Lorsque cette quantitť horizontale est multipliťe par le vecteur de colonne, la valeur de rťponse sera obtenue. Il s'agit du premier noyau de convolution. La deuxiŤme valeur est obtenue par le deuxiŤme noyau de convolution, et les troisiŤme et quatriŤme valeurs sont obtenues de maniŤre similaire.
Pour rťsumer, l'opťration de convolution consiste ŗ multiplier la matrice et le vecteur, la matrice correspond ŗ plusieurs noyaux de convolution et le vecteur correspond ŗ la valeur de rťponse (ResponseValue) des carrťs environnants.
Tout le monde sait que multiplier une matrice par un vecteur demande beaucoup de calculs. L'exemple que j'ai donnť ici n'est pas si grand, mais pensez-y. Si vous entrez et sortez 100 canaux, si le noyau de convolution est 3 ◊ 3 ◊ 100, il est 100 ◊ 900. Ce calcul est trŤs grand. Large, donc la plupart du travail est concentrť sur la rťsolution du problŤme de redondance dans ce (opťration de convolution).
Noyaux de basse prťcision (noyaux de basse prťcision)
Existe-t-il un moyen de rťsoudre le problŤme de la redondance?

…tant donnť que le noyau de convolution est gťnťralement un nombre ŗ virgule flottante, la complexitť de calcul du nombre ŗ virgule flottante est un peu plus grande et prend ťgalement un peu plus d'espace. Quelle est l'astuce la plus simple? En supposant que le noyau de convolution devienne binaire, tel que 1, -1, voyons quels sont les avantages de la conversion de 1, -1 dans le futur? Ce vecteur 1, -1 (fait) l'opťration de multiplication d'origine devient l'addition et la soustraction, de sorte que la quantitť de calcul est beaucoup rťduite. En outre, la quantitť de modŤles et de stockage est ťgalement considťrablement rťduite.

Il existe un travail similaire similaire, qui consiste ŗ convertir un type ŗ virgule flottante en type entier. Par exemple, un nombre ŗ virgule flottante 32 bits ťtait auparavant un nombre entier 16 bits, la capacitť de stockage sera ťgalement petite ou le modŤle sera petit. En plus de la binarisation ou de l'intťgrisation du noyau de convolution, vous pouvez ťgalement transformer Response en un nombre binaire ou un entier.

Il existe un autre type de recherche plus quantitatif. Par exemple, en regroupant cette matrice, telle que 2.91, 3.06 et 3.21, dans une classe, quel avantage utiliser 3 au lieu de quantifier? Tout d'abord, votre capacitť de stockage est rťduite, vous n'avez pas besoin de stocker la valeur d'origine, il vous suffit de stocker la valeur d'index de chaque centre aprŤs quantification. De plus, la quantitť de calcul est ťgalement rťduite, vous pouvez trouver un moyen de rťduire le nombre de multiplications, de sorte que la taille du modŤle sera rťduite.
Grains de bas rang


Une autre faÁon, que faire si la matrice est grande? Rendre la matrice plus petite, tant de gens ont fait cette chose, 100 canaux (de sortie), je l'ai changť en 50, c'est une astuce. Une autre astuce est qu'il y a beaucoup d'entrťes, 100 canaux et 50 canaux.
Combinaison de noyaux de convolution de bas rang

La rťduction des canaux rťduira-t-elle les performances? Alors quelqu'un a fait ceci: multipliez cette matrice en deux petites matrices. Si cette matrice est 100 ◊ 100, je vais la multiplier en deux matrices de 100 ◊ 10 et 10 ◊ 100, (multipliez La matrice rťsultante) devient ťgalement une matrice 100 ◊ 100, qui se rapproche de la matrice 100 ◊ 100 d'origine. Pensez-y de cette faÁon, 100 ◊ 100 devient 100 ◊ 10 et 10 ◊ 100, ťvidemment le modŤle devient plus petit et devient un cinquiŤme. De plus, le montant du calcul est rťduit ŗ un cinquiŤme.
Noyau de convolution ťparse


Une autre faÁon, comment multiplier la matrice et le vecteur plus rapidement et les paramŤtres du modŤle est moindre? Vous pouvez changer certains des nombres en 0, par exemple, 2,91 devient 0, 3,06 devient 0 et devient 0. AprŤs Ítre devenu 0, il devient une matrice clairsemťe. La capacitť de stockage de cette matrice clairsemťe deviendra plus petite. Petit, car il n'est pas nťcessaire de multiplier directement 0. Il existe ťgalement une structure clairsemťe (structurťe clairsemťe), telle que cette forme diagonale, la matrice est multipliťe par un vecteur, qui peut trŤs bien Ítre optimisť. Structurť clairsemť ici correspond ŗ la convolution de groupe dont je parlerai plus tard.
Combinaison de noyaux de convolution clairsemťs

Voyons si cette matrice peut Ítre approchťe en multipliant plusieurs matrices clairsemťes. C'est le sujet dont je veux parler aujourd'hui. Notre travail avance ťgalement sur ce point. Avant de prendre cette direction, nous ne savions pas qu'une matrice peut Ítre multipliťe par deux matrices ťparses ou mÍme plusieurs matrices ťparses pour atteindre l'objectif d'un petit modŤle et d'une petite quantitť de calcul.
De IGCV1 ŗ IGCV3
IGCV1

Tout d'abord, permettez-moi de vous prťsenter notre article lors de la confťrence ICCV 2017 de l'annťe derniŤre, la mťthode de convolution de groupe entrelacťe.
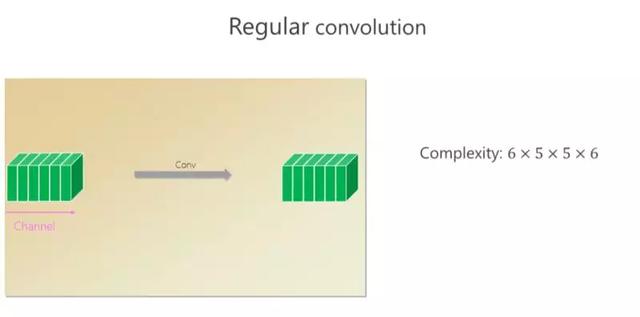
Il y a six canaux dans cette convolution, et six petits carrťs (canaux) sortent par la convolution. Si la taille du noyau spatial est de 5 ◊ 5, pour chaque position, son calcul est de 6 ◊ 5 ◊ 5 ◊ 6.

Je viens de mentionner une forme (structurťe) clairsemťe, qui correspond ŗ la forme de convolution de groupe. J'ai divisť ces 6 canaux en 3 canaux supťrieurs et les 3 canaux infťrieurs, et les ai convoluťs sťparťment.AprŤs avoir terminť, je les ai assemblťs et j'ai finalement obtenu 6 canaux. En ce qui concerne le montant du calcul, ce qui prťcŤde est de 3 ◊ 5 ◊ 5 ◊ 3, et le suivant est ťgalement le mÍme. Toute la complexitť du calcul est la moitiť de celle du 6 ◊ 5 ◊ 5 ◊ 6 prťcťdent, mais le problŤme est que l'utilisation des paramŤtres peut ne pas Ítre suffisante.
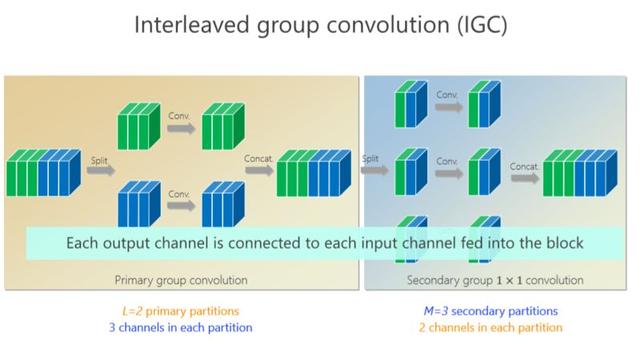
†Notre travail est basť sur la convolution de groupe. Je viens de mentionner que les trois canaux ci-dessus ne sont pas liťs ŗ ces trois canaux. Y a-t-il un moyen de les relier? Nous avons donc introduit un deuxiŤme groupe de convolutions, nous avons rťorganisť les 6 canaux, 1, 4 sont placťs ici (premiŤre branche), 2, 5 sont placťs ici (deuxiŤme branche), 3 , 6 y est placť (la troisiŤme branche), de sorte que chaque branche effectue ŗ nouveau une convolution 1 ◊ 1, rťsultant en deux nouveaux canaux, deux canaux, deux canaux, ensemble. Par entrelacement, nous espťrons que chaque canal de sortie (canal vert ou canal bleu) est connectť aux 6 premiers canaux.

quel est l'avantage? Gr‚ce ŗ la convolution de groupe du deuxiŤme groupe, des conditions complťmentaires peuvent Ítre atteintes ou n'importe quelle sortie (canal de sortie) peut Ítre connectťe ŗ n'importe quelle entrťe (canal d'entrťe).

Ici, nous introduisons une condition complťmentaire stricte: intuitivement, s'il y a deux canaux dans le premier groupe de convolutions, ils tombent dans la mÍme branche, et j'espŤre tomber dans des branches diffťrentes dans le deuxiŤme groupe. (Branche). Plusieurs canaux du deuxiŤme groupe, comme une branche, doivent provenir de toutes les branches de la convolution du premier groupe, ce qui est appelť une condition complťmentaire. Qu'apporte cette condition complťmentaire? Il amŤnera (existe entre n'importe quelle paire de canaux d'entrťe et de sortie) un chemin, ce qui signifie que la matrice de multiplication est une matrice dense. Pourquoi est-il appelť "strict"? Autrement dit, il existe un chemin entre n'importe quelle entrťe et sortie, et il n'y a qu'un seul chemin.

AprŤs l'introduction de critŤres stricts, la quantitť de paramŤtres devient plus petite et le modŤle devient plus petit. Quels avantages apporte-t-il? Ici, je donne une conclusion, L est le nombre de partitions ou de branches dans le (premier) groupe de convolution, M est le nombre de convolutions de convolution dans le deuxiŤme groupe, et S est la taille du noyau de convolution, Habituellement supťrieur ŗ 1. Une telle inťgalitť est presque toujours ťtablie. Que signifie cette inťgalitť? La conclusion est: si on la compare ŗ la convolution standard standard, nous pouvons ťlargir le rťseau par notre mťthode de conception. Par rapport ŗ l'approfondissement du rťseau, l'ťlargissement du rťseau est une autre dimension. Quels sont les avantages de l'ťlargissement? Cela amťliorera-t-il les rťsultats? Nous avons fait quelques expťriences.

Cette expťrience est comparťe ŗ la convolution standard. Regardons le tableau dans le coin infťrieur gauche. Ce tableau est la quantitť de paramŤtres. Le rťseau que nous avons conÁu reprťsente presque la moitiť de la quantitť de paramŤtres standard (convolution). Regardez ensuite le rťseau dans le coin infťrieur droit, notre calcul est presque la moitiť. Dans l'ensemble de donnťes de classification d'images standard CIFAR-10 (tableau ci-dessus), nos rťsultats sont meilleurs que les prťcťdents. Nous pouvons mÍme constater que plus la profondeur est meilleure, une certaine amťlioration au niveau 20 n'est pas si ťvidente, mais lorsqu'elle est profonde, elle peut atteindre une augmentation de 1,43.

Plus tard, nous avons fait la mÍme expťrience pour CIFRA-100, et avons constatť que notre amťlioration est toujours cohťrente, et mÍme plus grande que la prťcťdente, car il est un peu plus difficile de la diviser en 100 catťgories que 10 catťgories, indiquant que les t‚ches les plus difficiles, nos avantages Le plus ťvident. Une fois cela ťlargi (les performances) s'amťliorent. Avec IGC, l'ťlargissement de la structure du rťseau apporte des avantages.

Ce sont deux petits ensembles de donnťes. En fait, dans le domaine de la vision par ordinateur, les rťsultats sur de petits ensembles de donnťes ne peuvent pas (complŤtement) expliquer le problŤme, et de trŤs grands ensembles de donnťes doivent Ítre effectuťs. Nous avons donc ťgalement crťť le jeu de donnťes ImageNet ŗ ce moment-lŗ. Par rapport ŗ ResNet, la quantitť de paramŤtres a ťtť rťduite de prŤs des deux cinquiŤmes, la quantitť de calcul a ťtť rťduite de prŤs de moitiť et le taux d'erreur a ťgalement ťtť rťduit. Cela prouve que la mise en uvre d'IGC modifie le modŤle. Large, avec de trŤs bons rťsultats sur les grands modŤles de rťseau.

Nous avons commencť ŗ faire cela en aoŻt et septembre de l'annťe prťcťdente. En octobre, nous avons constatť que Google avait un travail appelť Xception. Voici son diagramme de structure. Ce formulaire est trŤs proche (notre structure). Il est trŤs similaire ŗ la soi-disant structure IGC. En fait, c'est un cas particulier de nous. ņ ce moment-lŗ, nous pensions que ce cas spťcial pourrait avoir le meilleur rťsultat, nous avons donc fait quelques vťrifications et, dans l'ensemble, nous avons une meilleure structure.

Il peut y avoir des variations d'IGC. Par exemple, si je transforme ce canal en convolution de groupe, le second est 1 ◊ 1, que se passera-t-il ainsi? Nous avons fait des expťriences similaires et avons toujours trouvť que notre mťthode ťtait la meilleure.

Lorsque nous l'avons fait ŗ l'ťpoque, nous espťrions le comparer avec la mťthode de pointe sur la structure du rťseau. Nous avons obtenu de trŤs bons rťsultats. ņ l'ťpoque, notre travail consistait ŗ amťliorer les performances ou la prťcision du modŤle en ťliminant la redondance.
IGCV2

†Plus tard, nous avons essayť d'utiliser les avantages de l'ťlimination de la redondance pour dťployer ce modŤle sur les tťlťphones mobiles. L'annťe derniŤre, nous avons continuť d'avancer dans cette direction pour mieux comprendre cette question et espťrons ťliminer davantage les redondances.

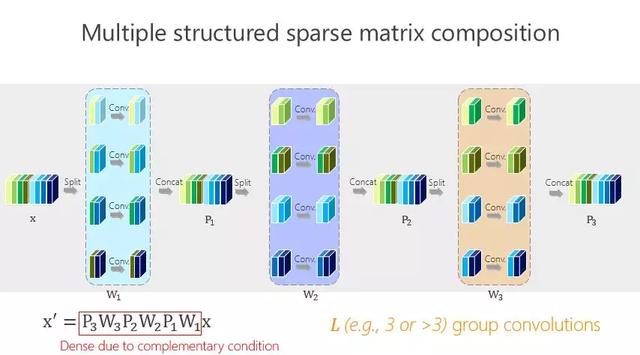
C'est plus simple ou plus simple. La structure de rťseau prťcťdente est obtenue par convolution de deux groupes ou multiplication de deux matrices. Y a-t-il un moyen de devenir un peu plus? C'est en fait trŤs simple, comme le montre l'image ci-dessus.

Les avantages apportťs par cette mťthode sont trŤs simples, c'est-ŗ-dire que vous voulez que la quantitť de paramŤtre soit aussi petite que possible, alors comment pouvez-vous rendre la quantitť de paramŤtre aussi petite que possible? Nous avons introduit les conditions dites d'ťquilibre. Bien que nous ayons ici des convolutions de groupe L-11 ◊ 1, y a-t-il une diffťrence entre les convolutions de groupe L-11 ◊ 1? Qui est le plus important et qui ne l'est pas? En fait, nous ne savons pas. Je ne sais pas quoi faire? Faites comme Áa. AprŤs la mÍme chose, nous obtiendrons les rťsultats mathťmatiques ci-dessus gr‚ce ŗ une dťrivation mathťmatique simple.
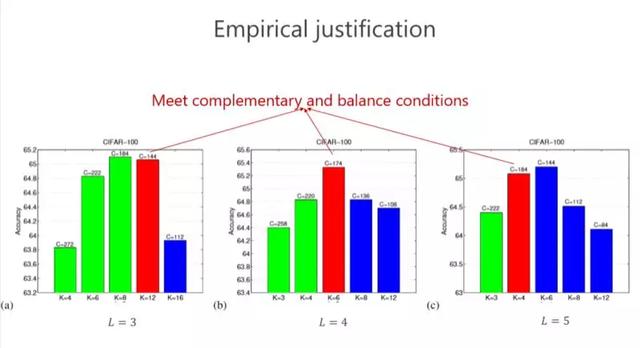
Vťrifions-le ŗ nouveau. Les conditions de complťmentaritť et d'ťquilibre ont ťtť discutťes plus haut. Est-ce le meilleur rťsultat? Ou y a-t-il un avantage suffisant? Nous avons fait quelques expťriences, les rouges correspondent ŗ celles qui satisfont nos conditions et nous avons trouvť que le rťsultat (L = 4) est le meilleur dans ce cas. En fait, est-ce toujours le meilleur? Pas nťcessairement, car le problŤme rťel est encore un peu loin de l'analyse thťorique. Mais nous avons gťnťralement constatť que les rouges ne sont pas les meilleurs et ťgalement classťs au deuxiŤme rang, ce qui indique que cette conception nous donne au moins de bonnes directives pour aider ŗ concevoir la structure du rťseau. Bien que ce ne soit pas toujours le meilleur, il est similaire au meilleur.

La deuxiŤme question, combien de convolutions de groupe devrions-nous concevoir (combien de L est fixť)? De mÍme, notre critŤre est ťgalement analysť par la quantitť minimale de paramŤtres. Dans le passť, deux groupes de convolutions ťtaient utilisťs. Nous pouvons obtenir une quantitť de paramŤtres plus petite de 3 ou 4, mais en fait, la conclusion finale a rťvťlť qu'il ne s'agit pas de la quantitť optimale de paramŤtres. La prochaine performance est la meilleure.
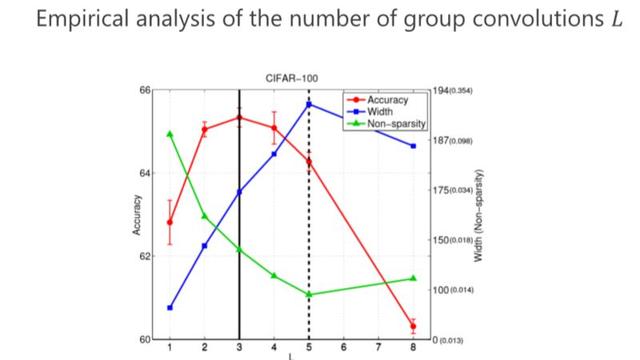
IGCV3

Plus tard, nous avons constatť que si des conditions complťmentaires strictes sont respectťes, la structure du modŤle devient trŤs clairsemťe et trŤs large, et le rťsultat peut ne pas Ítre le meilleur. Nous sommes donc devenus Loose. Que signifie Loose? Auparavant, il n'y avait qu'un seul chemin entre la sortie (canal de sortie) et l'entrťe (canal d'entrťe). Nous l'avons modifiť trŤs simplement. Pouvons-nous avoir plusieurs chemins? Les chemins multiples ne sont pas si clairsemťs, son avantage est que chaque sortie (canal de sortie) peut obtenir des informations de l'entrťe (canal d'entrťe) dans plusieurs chemins, nous avons donc conÁu la condition Loose.

En fait, c'est trŤs simple, nous dťfinissons deux super-canaux (super-canaux) qui ne peuvent apparaÓtre que dans une seule branche en mÍme temps, ne peuvent pas apparaÓtre dans deux branches en mÍme temps, pour atteindre la condition Loose.

Plus tard, nous sommes allťs plus loin et avons regroupť des structures clairsemťes et de faible rang. Nous comparons sur ImageNet, et comparons avec MobileV2 en mÍme temps, notre avantage est de plus en plus ťvident dans le petit modŤle. Pour les rťsultats de comparaison, voir la figure ci-dessous.



C'est le contenu principal d'aujourd'hui. J'ai fait ce travail avec de nombreux ťtudiants et collŤgues. Les cinq premiers sont mes ťtudiants. Ting Zhang travaille maintenant au Microsoft Research Institute. Bin Xiao est mon collŤgue. Guojun Qi est amťricain. Professeur, nous avons collaborť ŗ cet article ensemble.