
Auteur | Jiang Weiwei
Modifier | Jia Wei
Au cours des derniŤres annťes, le rťseau de neurones convolutionnel (CNN) a fait d'ťnormes progrŤs dans le problŤme de la reconnaissance de mouvement vidťo. Cependant, ces mťthodes ont tendance ŗ Ítre trop prťoccupť par l'arriŤre-plan de la scŤne, tout en ignorant l'action spťcifique lui-mÍme. Comme le montre la figure 1, alors que l'action humaine a ťtť bloquťe dans l'image, on peut encore dťduire le type d'action le plus probable par la scŤne. Pour le modŤle de rťseau neuronal convolutif, ťtant donnť le type d'opťration en reconnaissant la scŤne est la scŤne inťvitablement des ťcarts.


Figure 1. Bien que pas vu la figure, nous pouvons encore dťduire une action spťcifique par la scŤne.
Cet ťcart de scťnario dans certains cas, peut provoquer le modŤle pour produire l'effet que nous ne voulons pas voir. La figure 2 montre, ŗ gauche, depuis le stade de baseball de fond, les gens qui chantent seront mal ŗ jouer prťdit baseball, mais dans le droit, mÍme si on nage complŤtement bloquť, le modŤle sera ŗ cause de la piscine arriŤre-plan de l'identification, les rťsultats de prťvision sont la natation donnťe.

Figure 2. …tude incitation ŗ l'algorithme de polarisation.
La recherche sur l'ťlimination de la scŤne de polarisation est encore relativement faible, ce NeurIPS 2019 publiť dans le document prťsente la suite d'une ťtude basťe sur la migration des programmes visant ŗ attťnuer l'ťcart de la scŤne.

Documents lien: https: //arxiv.org/pdf/1912.05534.pdf
La contribution de cet article est de proposer une perte dťfinir deux scťnarios visant ŗ rťduire l'ťcart dans le modŤle de prť-formation de CNN:
1) contre scŤne pertes (scŤne de perte contradictoire), encourager l'apprentissage reprťsentation fonction invariante scŤne modŤle;
2) la perte de confusion bouclier humain (perte de confusion masque humain), le modŤle est toujours donnť pour empÍcher l'action dans le corps humain ne sont pas visibles de prťdire quand.
Afin de vťrifier l'efficacitť du systŤme proposť, le journal a publiť la t‚che de comprendre l'expťrience de trois actions: la classification d'action, lieu et du moment de la reconnaissance de mouvement espace-temps d'action. Les rťsultats expťrimentaux montrent que la performance que le programme d'apprentissage transfert de modŤle de rťfťrence mieux ťcart supprimť.
Un programme
Rťduire la scŤne de dťviation Ce document prťsente le mode de rťalisation reprťsentť sur la Fig.
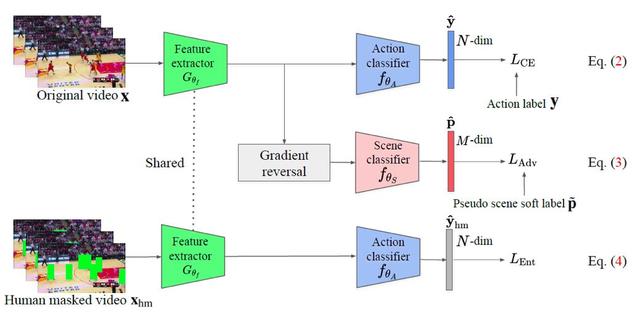
Figure 3. Caractťrisation du protocole de suppression de polarisation d'apprentissage de la scŤne vidťo.
L'objectif de ce programme est de paramŤtres prť-formation sur une grande t‚ches de classification vidťo, l'apprentissage extracteur de caractťristiques. Dans ce processus, les auteurs ont utilisť trois fonctions de perte. Tout d'abord, les ensembles de donnťes Mini-Kinetics-200, gr‚ce ŗ une fonction standard de perte d'entropie croisťe
Former le classement d'action. On ajoute ensuite une scŤne contre la perte
De cette qualification ne peut Ítre dťduit scŤne appris. Enfin, en utilisant le masque Ítre dťtectť R-CNN et le corps de l'obturateur, constituť d'un ensemble de donnťes est bloquť, le blocage et l'application de pertes humaines confondu
En second lieu, le dispositif expťrimental
Ce document rťalisť sur la t‚che de comprendre l'expťrience de trois actions: la classification d'action, lieu et du moment de la reconnaissance de mouvement espace-temps d'action. L'ensemble de donnťes utilisťe est la suivante:
1) Prť-formation: Mini-Kinetics-200, contenant 80000 vidťos de formation et 5000 vidťo vťrificateurs.
2) Catťgorie d'action: UCF-101, contient 13.320 vidťo 101, l'opťration correspondant ŗ la catťgorie; BDMH-51, contient 6766 vidťo 51 opťration correspondant ŗ la catťgorie; Diving48, contient 48 types d'opťration de conduite 18000 vidťo . Pour les deux premiers ensembles de donnťes, en utilisant un ensemble schťma de partitionnement formation / test prťcťdent document de travail.
3) Sťquence de fonctionnement Positionnement: Thumos-14, comprenant 20 types d'action avec une estampille temporelle et de la catťgorie.
4) la reconnaissance de mouvement temporel: JHMDB, 928 contient 21 types de fonctionnement vidťo, ont chaque opťration ŗ identifier la lťgende boÓte.
Ce document utilise une partie du modŤle prťcťdent, combinť avec la scŤne du programme de suppression de polarisation proposťe. Dans la phase de prť-formation, le papier ŗ l'aide d'un 3D-ResNet-18. Pour la reconnaissance de mouvement temporel, ce document utilise un modŤle basť sur VGG-16.
Les rťsultats expťrimentaux sur le fonctionnement des t‚ches de classification est indiquťe dans le tableau 1. En ťvacuant les augmentations d'opťration de dťviation, les performances des trois ensembles de donnťes sont amťliorťes.
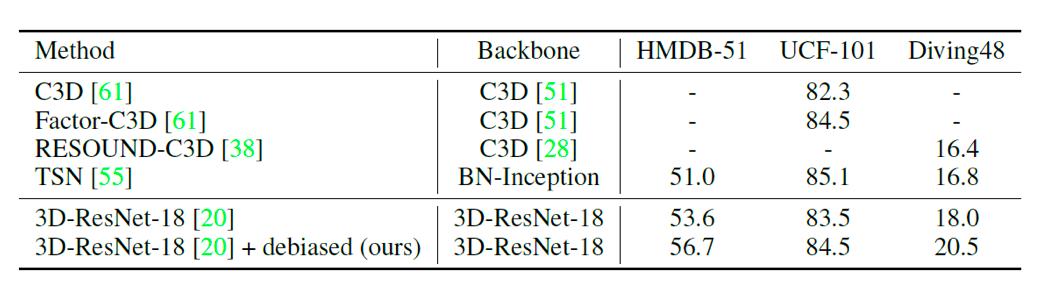
Tableau 1. Prťcision t‚che de classification d'action. Les rťsultats moyens des diffťrentes faÁons de diviser l'analyse UCF-101 et BDMH-51.
La figure 4 montre ťgalement la prťcision relative d'une corrťlation nťgative entre la dťviation de la caractťrisation de la scŤne de levage. Vous pouvez le voir dans l'ensemble de donnťes plus d'ťcart de la scŤne, plus l'ascenseur pour amener l'algorithme de dťviation.
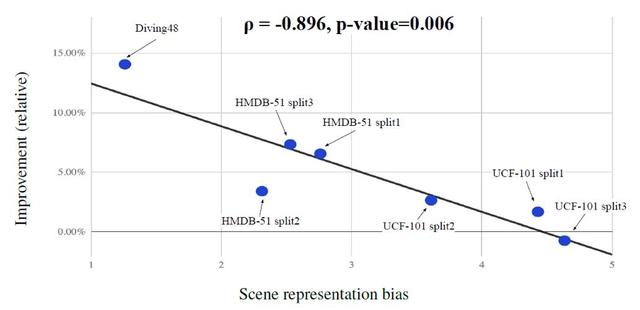
4. La figure amťliorer la prťcision de la caractťrisation de la scŤne est relativement corrťlation nťgative entre l'ťcart. UCF-101 de maniŤre diffťrente division BDMH-51 aura des rťsultats diffťrents.
Les tableaux 2 et 3 sont donnťs les rťsultats expťrimentaux sur l'opťration de positionnement et de synchronisation des t‚ches de reconnaissance de mouvement temporels. Sur les deux t‚ches, scŤne Ce programme de suppression prťsente en papier des ťcarts peut amťliorer les performances du modŤle de rťfťrence.
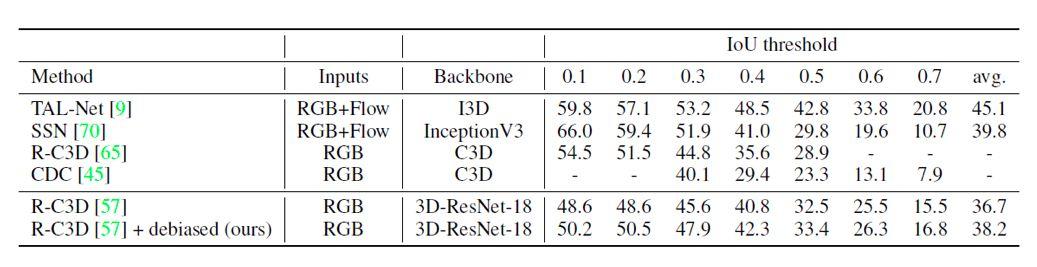
Tableau 2. Rťsultats expťrimentaux Le calendrier de positionnement.

Tableau 3. Rťsultats expťrimentaux reconnaissance de mouvement temporel.
BDMH-51 dans l'ensemble de donnťes, pour amťliorer encore les ťtiquettes en papier et les diffťrents scťnarios oý les combinaisons de fonctions de perte de mannequin. Le tableau 4 dťmontrent la faÁon dont l'utilisation de la scŤne soft label peut mieux amťliorer les performances, tandis que le tableau 5 montrent les scťnarios d'utilisation contre la perte et la perte peut confondre le corps obscurci la plus grande amťlioration de la performance.
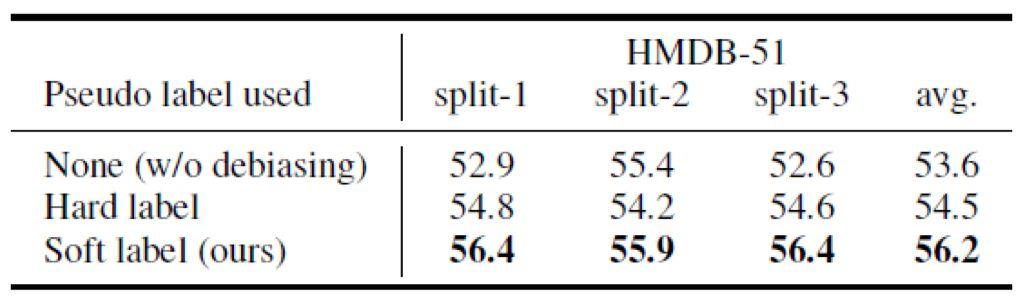
Tableau 4. Effet de diffťrents scťnarios tags.
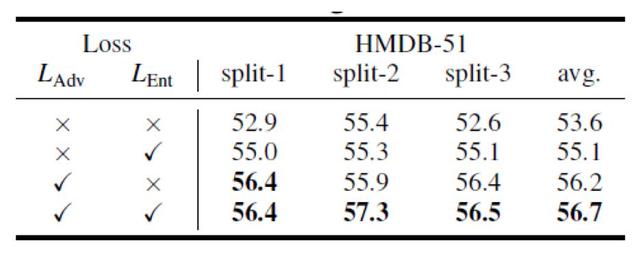
Tableau 5. Effet des diffťrentes combinaisons de perte de fonction.
Pour vťrifier davantage la validitť du rťgime d'annulation de polarisation de la scŤne proposťe, le document est analysť sur la base des cartes d'activation BDMH-51 UCF-101 et deux ensembles de donnťes, comme le montre la figure. Les rťsultats ont montrť que, lorsqu'ils ne sont pas utilisťs pour ťliminer la scŤne de polarisation, le modŤle parce que trop d'attention ŗ la scŤne plutŰt que de l'erreur humaine a conduit ŗ la classification et ŗ l'utilisation des coulisses pour ťliminer les biais, le modŤle peut Ítre plus prťoccupť par le corps humain lui-mÍme, pour donner la catťgorie d'action correcte.

5. BDMH-51 sur la figure classe UCF-101 et active un exemple de cartographie de deux ensembles de donnťes. la police indique que le bleu soulignť classification correcte, alors que la police rouge au nom de classification erronťe.
CONCLUSIONS
Ce document concerne le problŤme de quelques ťtudes antťrieures impliquťs, ŗ savoir la reconnaissance de mouvement de dťviation de fond ťliminer le problŤme et propose une solution efficace, y compris la perte de deux nouvelle dťfinition proposťe de cette scŤne contre la perte et le bouclier humain perte de confusion. Dans l'action de classification, le fonctionnement de la sťquence d'action pour localiser et identifier trois types d'espace-temps, un grand nombre d'expťriences sur diffťrentes t‚ches montrent l'efficacitť du systŤme proposť dans le prťsent document.
rťfťrence:
†Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, et Kevin Murphy. Repenser l'apprentissage des fonctionnalitťs pour la comprťhension spatiotemporelle vidťo. En ECCV 2018.
†Il Kaiming, Gťorgie Gkioxari, Piotr DOLLAR, et Ross Girshick. Masque R-CNN. En ICCV 2017.
†Khurram Soomro, Amir Roshan Zamir et Mubarak Shah UCF101 :. Un ensemble de donnťes de 101 classes d'actions humaines de vidťos dans la nature arXiv prťpublication arXiv :. 1212,0402, 2012.
†. Hildegarde Kuehne, Hueihan Jhuang, EstŪbaliz Garrot, Tomaso Poggio et Thomas Serre BDMH: Une grande base de donnťes vidťo pour la reconnaissance du mouvement humain En ICCV 2011 ..
†Yingwei Li, Yi Li, et Nuno Vasconcelos Resound: .. Vers une reconnaissance de l'action sans biais de reprťsentation dans ECCV 2018.
†. Y.-G. Jiang, J. Liu, A. Roshan Zamir, G. Toderici, I. Laptev, M. Shah, et R. Sukthankar Thumos dťfi: la reconnaissance d'action avec un grand nombre de classes http :. // CRCV .ucf.edu / THUMOS14 / 2014.
†Hueihan Jhuang, Juergen Gall, Silvia Zuffi, Cordelia Schmid et Michael J Noir. Vers une reconnaissance de l'action comprťhension. En ICCV 2013.
†Kensho Hara, Hirokatsu Kataoka et Yutaka Satoh. Can spatiotemporelle 3d CNNs retracent l'histoire de CNNs 2d et IMAGEnet? En CVPR 2018.
†Gurkirt Singh, Suman Saha et Fabio CUZZOLIN. Temps rťel en ligne multiple localisation d'action spatio-temporelle et la prťvision sur une seule plate-forme. En ICCV 2017.