Article co-rédacteur en chef de trois rivičres, Zong, Xiao-Fan.
Lei Feng réseau par AI Technology Review: Go sommet Wuzhen le lendemain, sur les « rapports de recherche AlphaGo, AlphaGo ce que cela signifie, » discours, Demis Hassabis + David Silver pour Ke Jie féroce hier bataille avec le développement de AlphaGo a fait une présentation publique, dans laquelle le principal AlphaGo du programme la recherche des membres clés de David Silver a parlé AlphaGo et le développement dans la présentation de la parole, Lei Feng réseau, Amnesty International Technology triés selon le site ci-dessous les mots d'origine.
Discours Résumé: Avec une forte stratégie de réseau et réseau de valeur, AlphaGo explorer arbre de recherche de base de la taille des mouvements serait grandement réduite. La version précédente AlphaGo Lee a été le « considérer que l'homme peut prendre la position de » moins et le nombre de tours de « l'anticipation Round 50 » pour limiter la taille de la recherche, et maintenant AlphaGo Master est déjŕ considéré comme la position la plus globale de valeur, et aussi de prévoir vous pouvez obtenir une plus grande précision. En conséquence, plus étroit arbre Monte Carlo et plus faible profondeur, sous-endroit pour faire le tour de considérer moins, prédire le nombre de tours moins, l'anticipation repose sur des réseaux plus puissants, seulement quatre TPU, est l'un des AlphaGo Lee puissance de calcul pour atteindre une plus grande résistance de jeu.
AlphaGo Maître de matériel, des algorithmes et des détails de la formation
Commencez avec le monde extérieur a parlé de préoccupations matérielles AlphaGo, en particulier, AlphaGo Lee a utilisé 50 ou si TPU sur le nuage Google. Fiez-vous ŕ une telle puissance de calcul, nous pouvons faire une couche de recherche profonde 50, c'est-ŕ-dire avant Lazi pour toutes les positions sur la carte peut faire 50 étapes ŕ prévoir. Il peut rechercher par 10.000 (dix mille, 1 million) positions. Cela semble beaucoup, mais en fait, il y a 20 ans, bleu foncé par seconde peut chercher 100.000.000 (cent millions, 1 million) positions. Alors, quand en fait AlphaGo penser plus intelligent que Deep Blue, sa stratégie de réseau et la valeur du réseau, ce qui réduit considérablement le nombre de chemins ŕ rechercher.

AlphaGo parler de la nouvelle version, nous l'appelons AlphaGo Maître. C'est la plus forte AlphaGo, il est également la conférence dans le jeu AlphaGo. algorithme AlphaGo maître utilisé dans beaucoup plus efficace, de sorte que seul un dixičme de la quantité de calcul nécessaire Version AlphaGo Lee. Et la formation AlphaGo Maître a aussi beaucoup plus efficace.
AlphaGo Fonctionnement maître (aprčs l'entrevue, AI Technology Review, y compris les médias avec l'argent confirmer personnellement, sont en cours d'exécution sur un seul ordinateur, mais contient quatre TPU) sur une seule (seule machine) ordinateur, mais a plus de AlphaGo Lee, AlphaGo Fan TPU doit ętre puissant.

Pourquoi AlphaGo Maître est si puissant qu'il? La raison derričre cela est parce que nous utilisons les meilleures données pour le former . Nous pouvons obtenir les meilleures données pas de l'homme, mais de leur propre AlphaGo . Nous allons AlphaGo faire leur propre professeur. Nous utilisons les capacités AlphaGo de recherche puissant, générer leurs propres données avec les données générées par la prochaine génération de l'apprentissage AlphaGo. Vous vous enseigner.
De cette façon, nous formons le réseau de valeur et de la stratégie de réseau sera pire que la précédente AlphaGo. Permettez-moi d'expliquer soigneusement les détails de l'algorithme.
Tout d'abord, nous laissons les échecs AlphaGo avec lui-męme. Ceci est basé sur l'apprentissage par renforcement, nous ne prenons plus jeu d'échecs humain pour apprendre. AlphaGo propres eux-męmes la formation, leur apprentissage de son corps. En renforçant les formes d'apprentissage, d'apprendre comment l'améliorer.
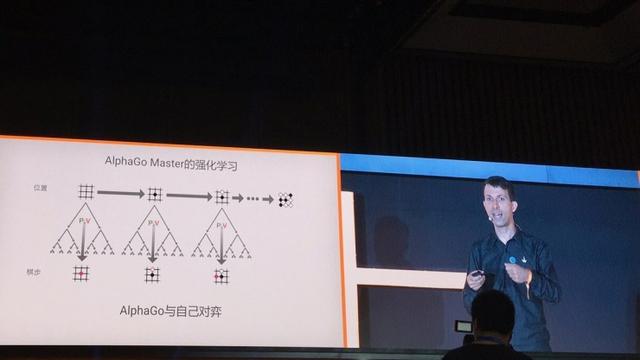
A chaque tour du jeu d'échecs, course AlphaGo a frappé le premier coup (pleine puissance) pour générer une recherche de recommandation Lazi que plan. Quand il a choisi cette étape Lazes, mettre en uvre et ŕ un nouveau cycle, se déroulera ŕ nouveau la recherche, la stratégie de réseau toujours basé et réseau de valeur, ont frappé le premier coup de la recherche, pour générer le prochain plan Lazes, et ainsi de suite, jusqu'ŕ ce qu'un jeu d'échecs a pris fin. Il répétera ce processus plusieurs fois pour générer des données de formation massives. Nous utilisons ensuite ces données pour former le nouveau réseau de neurones.
Tout d'abord, quand AlphaGo et ses propres échecs de jeu avec ces données de formation pour former une nouvelle stratégie de réseau. Avant le fait, AlphaGo recherche d'exécution, sélectionnez un programme Laz, qui sont les plus élevées de qualité des données que nous avons obtenus.
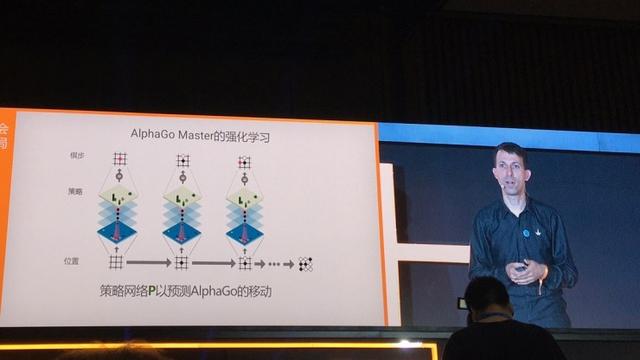
Ensuite, laissez le réseau politique en utilisant uniquement son propre, sans aucune recherche, pour voir si elle peut produire le męme programme d'ouvertures de élargi. L'idée est ici: sans parler de sa propre stratégie de réseau, en essayant de travailler et a frappé le premier coup des résultats de recherche comme tout un programme AlphaGo Lazi. En conséquence, un tel réseau de stratégie que la version précédente du AlphaGo bien pire.
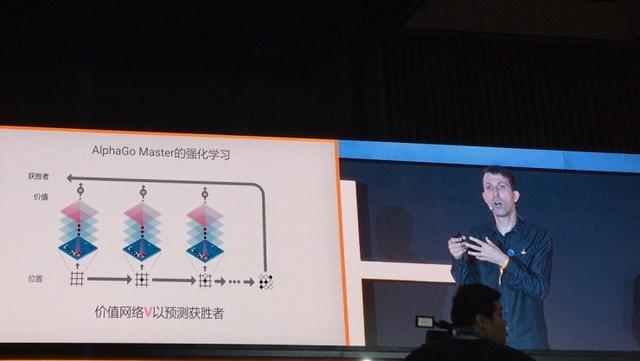
Nous apprécions également le réseau de formation d'une maničre similaire. Il utilise la meilleure stratégie pour former les données, et ces données sont pour lui-męme et son AlphaGo d'échecs lorsque le vainqueur de la version complčte des données. Comme vous pouvez l'imaginer, AlphaGo lui-męme et son jeu vers le bas beaucoup. L'un des plus gagnant du jeu d'échecs représentatif est sélectionné ŕ partir des données extraites. Par conséquent, ces données sont trčs élevés gagnants de qualité jeu d'échecs au début de l'évaluation des tours.
nous voulons connaître la situation dans le 10e tour, comment faire, par exemple, dans un jeu d'échecs,? Nous ré-exécuter ŕ nouveau ŕ partir de zéro ce jeu d'échecs, et a finalement trouvé gagné noir, oů vous pouvez faire une estimation raisonnable: Noir a dominé le 10e tour.
Vous avez donc besoin de données de formation de haute qualité pour former le réseau de valeur. Ensuite, la valeur du réseau pour prédire ces AlphaGo lui-męme et son jeu d'échecs d'échecs, de quel côté est le gagnant. Ces données, chaque tour du jeu d'échecs, nous avons laissé la valeur du réseau pour prédire le vainqueur final.
Enfin, nous réitérons le processus de fois, enfin obtenir la nouvelle stratégie et la valeur du réseau. Par rapport ŕ l'ancienne version, ils sont beaucoup plus forts. Ensuite, mettre la nouvelle version de la politique, la valeur de l'intégration du réseau ŕ l'intérieur AlphaGo, obtenir la nouvelle version, plus puissante que la précédente AlphaGo. Cela conduit ŕ une meilleure prise de décision dans l'arborescence de recherche, les résultats de meilleure qualité et des données, le recyclage obtenir une nouvelle stratégie plus puissante, la valeur du réseau, ce qui AlphaGo plus puissant encore, et a donc augmenté.
Enfin, comment la performance AlphaGo? Allez au point de vue de la note, avant ZEN, le logiciel CrazyStone jusqu'ŕ environ 2000 points, Fan Hui édition AlphaGo prčs de 3000 points, en hausse de 3 sous LiShiShi la version AlphaGo portée 3500 points ou plus, AlphaGo Maître a augmenté trois sous-portée de 4500 points ou plus .

Aprčs le discours d'ouverture, Demis Hassabis + David Silver a accepté Lei Feng réseau AI Technology Review, y compris un certain nombre d'entrevues dans les médias, quelques-uns des endroits que nous sommes plus intéressés, ętre accompagnés ici:

1. La nouvelle version de AlphaGo ne ont pas besoin d'apprendre de tuteur humain?
Oui, il ne dépend pas du monde extérieur a été un mentor, et maintenant nous voulons ŕ la direction générale de l'IAG du développement de l'intelligence artificielle.
2. Réalisations Actuellement DeepMind effectuées sur le Go a demandé d'étendre l'autre sens? DeepMind d'étendre ŕ nouveau dans l'autre sens sur ce résultat?
Sur l'application spécifique, encore aux premiers stades de nos applications d'exploration, y compris des applications telles que le développement de nouveaux médicaments viennent d'ętre mentionnés dans son discours qu'il est seulement celui du milieu de la technologie.
3. parler juste, vous avez mentionné AlphaGo commence déjŕ ŕ avoir au cours d'échecs une « intuition », comme l'homme, si l'on peut dire qu'il se dirige vers une forte scčne AI? Des moyens ayant la conscience de soi?
Je pense qu'il faut le dire, continuer ŕ renforcer la formation dans un domaine spécifique, il ne peut réaliser cette intuition ou sentiment d'appartenance dans ce domaine est déterminé, et un résultat direct de la conscience de soi humaine sont différents. De ce fait, la possibilité de l'utiliser non seulement dans le domaine Go, mais inclut d'autres domaines.
4. Il est calculé par le montant que vous avez mentionné hier, l'année derničre, ce qui équivaut ŕ un dixičme du calcul du montant de la guerre homme-machine, il ne peut pas dire encore plus clair?
Oui, nous l'avons dit hier, il utilise TPU, unités de traitement de dix, représentent seulement un dixičme de la quantité de calcul, de souligner ici, fait référence ŕ la fois ŕ un dixičme des comptes consommation d'énergie pour seulement un dixičme du précédent Tout d'abord, l'opération se réfčre également ŕ un dixičme des ressources que d'appeler avant.
5. Would vous mentionnez AlphaGo Lee a utilisé 50 ou si TPU sur le nuage Google, moins quantité de temps de calcul de sa puissance de calcul, ŕ la fin est combien de TPU?
Est un seul (une seule machine), il y a quatre serveurs physiques au-dessus du TPU.
6. AlphaGo hier moitié du jeu, devrait logiquement ętre inférieure au temps précédent, pourquoi vous continuez ŕ jouer Lazi vitesse uniforme, l'algorithme derričre ce fait quels paramčtres?
Nous calculons chaque étape est continue et stable, il est temps d'élaborer une stratégie Qiuwen par les pairs pour parvenir ŕ une utilisation maximale du temps, nous pensons donc que l'uniforme est le meilleur.
7. Pourquoi AlphaGo en se faisant passer le temps droit Master60 avait battu Jie Ke, pourquoi tenir ce concours?
M. David Silver, chercheur principal de déclaration AlphaGo:
La nouvelle version de AlphaGo, l'auto-formation a quelques millions de fois, et dans la détection des faiblesses dans les anciennes versions de performances exceptionnelles. En conséquence, la nouvelle version de l'ancienne version AlphaGo peut faire trois sous. Mais quand jeu d'échecs AlphaGo et n'a jamais eu des joueurs humains, cet avantage cessera d'exister, surtout dans un maître d'échecs Ke propre, il pourrait nous aider ŕ découvrir de nouvelles vulnérabilités Alphago jamais montrer. Une telle mesure n'est pas comparable. Pour la deuxičme tour de jeu et troisičme tour de cette semaine, nous verrons.
La nouvelle version de AlphaGo a formé contre lui-męme des millions de fois, et a appris ŕ devenir trčs bon ŕ exploiter les faiblesses dans les versions précédentes. Voilŕ pourquoi il est âgé d'environ trois pierres plus forte dans Mais les jeux en tęte-ŕ-tęte contre son ancienne auto. Qui doesn « ai rien moyenne quand il se heurte ŕ un joueur humain avec qui AlphaGo n'a jamais formé -. en particulier un grand maître comme Ke Jie, qui peuvent découvrir de nouvelles faiblesses, nous ne savons pas sur les échelles ne sont tout simplement pas comparables nous sommes trčs enthousiastes. pour les deuxičme et troisičme jeux cette semaine - David Silver, chercheur principal AlphaGo
Ping Lu Lei Feng réseau de la couverture exclusive de la technologie AI, sans autorisation, a refusé de réimpression.