

Un grand nombre dans le cadre de la normalisation des lots (ci-aprčs dénommé BN) opérations dans une pratique particuličre est trčs simple, ne fait pas exception ŕ keras, il suffit d'ajouter la couche BN dans le modčle, cela signifie que face ŕ couche en normalisation :
de BatchNormalization d'importation de keras.layers comme BN
BN (epsilon = 0,001, centre = True, échelle = True, beta_initializer = 'zéros', gamma_initializer = 'les')
Ici principalement sur les paramčtres liés au processus de formation. Nous utilisons les réglages des paramčtres par défaut officiels, oů epsilon (

) Est l'écart type estimé au nécessaire d'ajouter un nombre trčs faible de la variance, ne peut pas ętre définie pour éviter gradient:
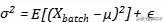
centre (
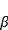
) Et l'échelle (

) Est de deux paramčtres d'apprentissage peuvent ętre mesurés de nouveau, nous avons mis ŕ vrai, cela signifie que nous pouvons apprendre ŕ utiliser ces deux paramčtres.

En particulier l'utilisation de nous, peut ętre retenir sélectivement ou de rejeter certains. Enfin, la méthode peut apprendre l'initialisation des paramčtres, nous pouvons utiliser keras l'initialisation se fait.
Nous avons principalement discuté de plusieurs questions mentionnées dans un article paru dans la théorie:
- En général, BN peut vraiment accélérer la formation elle?
- Ne tenez compte que l'échelle de fonction, sans tenir compte de changement de covariable interne, avec l'augmentation de la couche BN, la formation ne sera pas mieux en mieux?
- Si le poids a changé les paramčtres du problčme des couches coordonnent la mise ŕ jour, puis en l'algorithme d'apprentissage adaptatif de vitesse et de BN vont obtenir de meilleurs résultats, il?
- Nous utilisons un lot différent dans la formation, BN aura un look d'impact comme?
Nous faisons toujours utiliser ensemble de données de formation MNIST, d'utiliser l'ancienne structure (ou de mieux voir l'effet, de sorte que nous pouvons réseau plus profond propre), enregistrer les résultats de la formation, des résultats optimaux ont été observés. Dans certains cas, dans la phase de test, il prend la sortie de chaque couche, les résultats de l'observation.
Nous avons d'abord les données d'importation, faites-le avec le codage d'un chaud, normalisé:
importer numpy comme np
de keras.datasets mnist d'importation
de keras.utils to_categorical d'importation
# Importer des données
(X_train, y_train), (X_test, y_test) = mnist.load_data ()
train_labels = to_categorical (y_train)
test_labels = to_categorical (y_test)
X_train_normal = X_train.reshape (60000,28 * 28)
X_train_normal = X_train_normal.astype ( 'float32') / 255
X_test_normal = X_test.reshape (10000, 28 * 28)
X_test_normal = X_test_normal.astype ( 'float32') / 255
Et en utilisant une fonction sigmoďde comme une unité cachée au commun de construction anticipatrice réseau de neurones:
importer numpy comme np
de keras.datasets mnist d'importation
de keras.models importer séquentielle
de keras.layers Dense d'importation
de optimiseurs d'importation KERAS
de BatchNormalization d'importation de keras.layers comme BN
def normal_model (a):
modčle séquentiel = ()
model.add (Dense (512, activation = a, input_shape = (28 * 28,)))
model.add (Dense (256, activation = a))
model.add (Dense (128, activation = a))
model.add (Dense (64, activation = a))
model.add (Dense (10, activation = 'softmax'))
model.compile (optimiseur = optimizers.SGD (dynamique = 0,9, nesterov = True), \
perte = 'categorical_crossentropy', \
métriques = )
retour (Modčle)
Ajout d'une couche de BN sur la base du modčle ci-dessus, comme un nouveau modčle:
def BN_model (a):
modčle séquentiel = ()
model.add (Dense (512, activation = a, input_shape = (28 * 28,)))
model.add (BN ())
model.add (Dense (256, activation = a))
model.add (Dense (128, activation = a))
model.add (Dense (64, activation = a))
model.add (Dense (10, activation = 'softmax'))
model.compile (optimiseur = optimizers.SGD (dynamique = 0,9, nesterov = True), \
perte = 'categorical_crossentropy', \
métriques = )
retour (Modčle)
Deux modčles de formation ŕ 10 époques, pour observer ses performances:
Modčle_1 = normal_model ( 'sigmoďde')
his_1 = model_1.fit (X_train_normal, train_labels, batch_size = 128, validation_data = (X_test_normal, test_labels), verbeux = 1, époques = 10)
w1 = his_1.history
model_2 = BN_model ( 'sigmoďde')
his_2 = model_2.fit (X_train_normal, train_labels, batch_size = 128, validation_data = (X_test_normal, test_labels), verbeux = 1, époques = 10)
w2 = his_2.history
matplotlib.pyplot importation comme plt
Seaborn d'importation comme sns
sns.set (style = 'whitegrid')
plt.plot (plage (10), w1 , '-.', label = 'Sans BN)
plt.plot (plage (10), w2 , '-.', label = 'Avec BN_1')
plt.title ( 'sigmoďde')
plt.xlabel ( 'époques')
plt.ylabel ( 'perte')
plt.legend ()

Comme le montre, vous pouvez voir juste ajouter une couche de BN, le taux de convergence devient plus élevé que le modčle sans ajouter beaucoup plus rapide.
Nous avions « communs unités cachées » ŕ l'aide Relu au lieu de sigmoďde, le taux de convergence devient plus rapide, alors nous serons si la couche BN Relu a démontré si bien les unités cachées pour accélérer encore? Nous allons utiliser Relu, pour observer ses effets:

Comme on le voit, comme Relu ętre soulagées par l'intermédiaire d'un gradient approximativement linéaire de disparaissant sigmoďde, mais BN est dépendant des actes en affaiblissant entre les couches, le BN peut en outre accélérer la convergence sur la base Relu.
Sur la base de notre compréhension du BN si elle est vraiment d'accélérer la convergence en affaiblissant la dépendance entre les couches (ou affaiblir le shfit covariable interne dans le processus de représentation) pour nos modčles 4 couches, puis ajoutez seulement une couche de BN, est indépendante du sous-jacent avec les trois autres au large, trois couches d'optimisation est une influence encore les uns des autres. Par conséquent, il est prévu que, si l'on ajoute la couche BN, la vitesse de convergence devient plus rapide.
La pratique spécifique, nous nous tournons pour construire quatre modčles, chacun avec différentes couches de BN et ont été formés pour donner perte Avec le changement de la carte époques:


Comme représenté, le modčle en utilisant la fonction d'activation sigmoďde, et l'effet de la vitesse de convergence augmente ŕ mesure que le nombre de couches augmente, l'utilisation du modčle ne semble pas numéro RELU sensible de couches de BN, en utilisant une couche d'un empilement sans différence significative, cela est trčs probablement parce que le réseau est assez profond, Relu ajouter une couche de BN semble avoir atteint les limites de cette optimisation du modčle.
Notre prochain code ne traitera pas Relu, parce que la fonction d'activation du modčle semble avoir un plus grand espace d'accord, nous sommes également facile de voir son effet. Pour ce faire relativement simple, nous changeons l'algorithme algorithme SGD Adam, d'une part, nous pouvons ajouter le modčle d'algorithme d'optimisation des taux d'apprentissage adaptatif n'utilise pas la couche BN, d'autre part, nous pouvons ajouter le modčle ŕ utiliser la couche BN adapter l'algorithme d'optimisation de taux d'apprentissage pour voir si accélérer la convergence.
Selon la connaissance, BN et le taux d'apprentissage adaptatif est de changer l'amplitude de la mise ŕ jour des paramčtres des deux moyens, dans la mesure du possible de conserver les paramčtres sont mis ŕ jour l'ampleur dans un ordre de grandeur, et il n'y a pas hiérarchique.
La pratique spécifique, nous définissons deux nouveaux modčles basés sur le modčle ci-dessus, celui-ci n'utilise pas BN, mais avec Adam, et l'autre en utilisant BN, également utiliser l'algorithme Adam, et par rapport au début des deux modčles, doivent faire attention nous gardons Adam et le taux d'apprentissage SGD devraient ętre les męmes, sont de 0,01, les paramčtres par défaut dans les deux keras pas le męme, régler manuellement:

Comme le montre, nous avons trouvé ajouter le modčle d'algorithme Adam basé sur l'utilisation du BN, de sorte que d'accélérer encore le modčle de convergence, sans utiliser le modčle BN, ajoutez algorithme Adam, et BN a également fait le męme effet.
On peut voir en théorie, la normalisation est effectuée sur la base du lot, le lot est un sous-ensemble de l'ensemble de la formation, sa taille influera directement sur le calcul de la moyenne et la variance de BN, il est probable que chaque lot a une autre moyenne et la variance.
On suppose que pour la détermination du lot, les paramčtres normalisés sont fixés. variance réduite (variance non BN) entre les lots taille de lot augmente, ce qui rend le réseau ont une volatilité plus grande. Notez, cependant, męme sans l'utilisation de BN, la taille des lots affectera encore le lot gradient estimé d'itérations plus rapides, mais facile ŕ tomber dans minimum local, plus petit caractčre aléatoire de lots, mais un besoin de déplacement des époques plus de temps. Donc, aprčs avoir changé la taille du lot, ne peut pas déterminer efficacement l'effet de la convergence ŕ la fin parce que la couche BN ou parce que l'estimation du gradient.
Mais nous pouvons utiliser ce problčme dans un autre problčme, ŕ savoir, le modčle et le modčle ajouté BN BN n'a pas été ajouté, et comparer leurs performances sur les différents lots, si sur un petit lot, ajouter le modčle par rapport ŕ la non-BN Ajouter modčle BN n'a pas donné de bons résultats, il montre, dans un petit lot, la couche BN ne fonctionne pas.
Selon cette idée, nous utilisons 4,64,256,1024 quatre types de taille de lot, respectivement modčle BN BN et le modčle n'ajoute pas la formation, vous pouvez obtenir:

Comme le montre, nous pouvons trouver beaucoup d'informations, pour ajouter le modčle de la couche BN (ligne en pointillés), lorsque la taille du lot de 64 et 4, l'effet de la convergence et de la vitesse sont les meilleurs pour le modčle BN (ligne solide) n'est pas ajouté, le lot 4 lorsque l'effet est aussi le meilleur. Mais dans un petit lot, BN d'utilisation devrait ętre peu d'impact sur les performances, petit lot, mais la couche BN fait des performances médiocres.
