Wen Wu 1,2, 1 Qiaolong Hui, Peng 1
(Chongqing Université des Postes et Télécommunications, Chongqing 400065, Chine; 2. lettre Chongqing by Design Co., Ltd, Chongqing 400065)
Pour l'algorithme de reconnaissance actuelle de la plaque d'immatriculation en présence de taux de précision de reconnaissance lente formation de modčle, de caractčre et d'autres questions, a étudié un algorithme de reconnaissance de plaque d'immatriculation basée sur Adaptive Differential Evolution Extreme Machine Learning. Utilisation avantage détection de bord et de l'enregistrement des couleurs est détectée plaque d'immatriculation, la zone de plaque d'immatriculation et ensuite divisées par la projection verticale de la méthode améliorée, le ELM évolution différentielle adaptative finale pour la reconnaissance de caractčres. Les résultats montrent que l'algorithme proposé a une vitesse de formation rapide, le taux de reconnaissance de caractčres, etc., il peut ętre appliqué ŕ des scénarios de trafic complexes.
Plaque de positionnement; segmentation de caractčres; projection verticale, la reconnaissance de caractčres; Adaptive Differential Evolution
CLC: TP391
Code de document: A
DOI: 10,16157 / j.issn.0258-7998.2017.01.035
format de citation chinois: Chiang, Qiaolong Hui, algorithme évolutionnaire Peng reconnaissance de plaque d'immatriculation ELM sur la base de différentiel adaptatif Technologie électronique, 2017,43 (1): 133-136,140.
Anglais format de citation: Wen Wu, Qiao Longhui, il Peng. Reconnaissance de plaque d'immatriculation basée sur l'apprentissage machine extręme évolutive auto-adaptatif .Application Technique électronique, 2017,43 (1): 133-136,140.
0 introduction
Comme une partie importante des systčmes de transport intelligents, systčme de reconnaissance de plaques d'immatriculation utilisés pour surveiller les conditions de circulation, le comportement du véhicule de surveillance, il peut également ętre utilisé pour le contrôle d'accčs au parking. Alors que dans la licence derničre décennie, la technologie de reconnaissance des plaques minéralogiques a fait de grandes réalisations, et est utilisé dans de nombreuses occasions pratiques, mais l'image d'une scčne complexe pour identifier la plaque d'immatriculation est encore une tâche ardue .
Plaque d'immatriculation de reconnaissance se compose généralement de trois parties: la localisation de la plaque, la segmentation de caractčres et de reconnaissance de caractčres. Plaque positionnée pour atteindre deux façons principales: une est basée sur les informations de couleur de la plaque d'immatriculation, la plaque d'immatriculation selon la combinaison spécifique des informations de couleur de la plaque d'immatriculation , et l'autre repose sur le bord ou les informations de texture, en fonction de la plaque d'immatriculation région de bord des informations plus claires que d'autres régions pour détecter la plaque d'immatriculation . Une premičre méthode est fournie, et une caméra sensible aux conditions d'éclairage, le second procédé, lorsque la plaque grave décoloration, un bord n'a pas été détecté en raison d'une défaillance causée positionné. Méthode de projection , Méthode domaine de communication et adaptation de modčle est le principal moyen pour réaliser une segmentation de caractčres. méthode de projection de caractčres nécessite l'écriture complčte et pas de bruit, la lumičre sensible ŕ l'influence. domaine des communications méthode de la plaque inclinée est pas sensible, mais ne peut pas ętre utilisé pour les caractčres de processus et de rupture d'adhérence de caractčres. Couramment utilisé des procédés de reconnaissance de caractčres sont: les réseaux de neurones (réseaux neuronaux rétropropagateurs et CNN), SVM et adaptation de modčle. Une plus grande précision lors d'un réseau neuronal classique pour la reconnaissance de caractčres et SVM, mais si le paramčtre sélectionné apparaît apprentissage inapproprié lentement, sur une installation locale de défauts optimale et . Modčle de méthode d'appariement est simple et pratique, mais est apparu caractčre conduira ŕ une réduction de taux de reconnaissance de correspondance de modčle Lorsque la déformation, adhérences et d'autres problčmes.
Comparé ŕ d'autres algorithmes de reconnaissance de plaque d'immatriculation classique, tel qu'il est utilisé ici, le procédé amélioré fait les points suivants: les avantages de (1) le positionnement de l'utilisation de la couleur et la détection de bord, qui surmonte les inconvénients de l'utilisation d'un seul type de procédé, (2) Vertical l'amélioration de maquillage de projection, la premičre segmentation grossičre, précise re-segmentation, une solution efficace pour le caractčre d'adhérences, fracture et ainsi de suite, (3) le modčle Sae-ELM est formé, le temps de formation est raccourci pour améliorer le taux de reconnaissance de caractčres.
1 emplacement de la plaque d'immatriculation
L'article de la zone de fonction multiple de la plaque, la texture, la couleur, l'aspect ratio, etc. ensemble, un algorithme amélioré est proposé emplacement de la plaque d'immatriculation, les étapes de mise en uvre spécifiques sont les suivantes:
(1) une plaque d'image en couleurs d'entrée, aprčs. La figure 1 (A), de préconditionnement (flou gaussien et niveaux de gris) pour donner en niveaux de gris, l'image sous-plaque verticale de bord d'opérateur de Sobel obtenu (en raison des fentes avant, véhicule effet standard ou analogue, la détection d'un bord horizontal peut affecter le résultat final de la connexion), puis la détection de bord dans la figure procédé de binarisation utilisant Otsu et rendre la fermeture morphologique. A cette époque, le numéro de la plaque d'immatriculation des régions candidates peuvent ętre obtenues, comme le montre la figure 1 (b) représenté sur la figure.
(2) Carte Couleur de l'image d'entrée transformé en HSV, si le pixel courant est H, S, composants v satisfont H, S, composantes V indiquées dans le tableau 1 correspondant ŕ la couleur bleue, la valeur de tonalité ensemble ŕ 255. De męme, si la composante jaune se rencontrent chaque valeur de gris est réglé ŕ 200, chaque composant satisfait le blanc, la valeur de gris est réglé ŕ 150; se rencontrent chaque composant de noir, de gris est fixée ŕ 100, et 0 sinon. Construit de cinq niveaux de gris la figure 1 (c) représenté sur la figure. prenant chaque niveau de gris de Séquentiellement niveau, respectivement fermé et faire opération arithmétique binaire. Dans la composante bleue, par exemple, la valeur de seuil est 255, la valeur de gradation ne soit pas mis ŕ 0. 255, un composant bleu des régions candidates peuvent ętre obtenues, comme représenté sur la figure 1 (d), l'autre élément du processus et ainsi de suite.

(3) La figure 1 (b) et la Fig. 1 (d) faire « et » opération peut ętre obtenue sur la Fig. 1 (e), ce qui réduit considérablement le nombre de régions candidates, puis au moyen de la zone de la plaque d'immatriculation, le rapport d'aspect et d'autres caractéristiques peuvent faire partie de l'écran pour la plaque de mannequin, et, enfin, fait par chaque classifieur SVM candidat pour plaque de commande de détermination de classification pour obtenir une véritable plaque d'immatriculation,. la figure 1 (f) représenté sur la figure. Pour une plaque de scénario générique, aprčs les étapes ci-dessus 3 pour localiser la zone de la plaque d'immatriculation. Cependant, pour certains scénarios spéciaux, l'étape (1) ou ŕ l'étape (2) peuvent ętre différents degrés d'échec, ce qui en mauvais effet de positionnement final. Cette solution est déterminée ŕ la plaque de SVM candidate, si le résultat de détermination est supérieur ŕ 1 SVM, les extrémités de positionnement. Dans le cas contraire, le positionnement ou le repositionnement d'une détection de bord de couleur.
Lors de la fermeture des opérations arithmétiques, il peut ętre erroné plaque divisée en deux régions. En effet, la présence de certains caractčres de la plaque d'immatriculation du bord vertical est pas évidente pour une deuxičme ou troisičme position (tel que « E », « 1 », etc.), la solution est de prolonger la plaque d'immatriculation, puis encore une fois zone d'extension détection de bord. Pour une image de faible luminosité, problčme d'extraction de bord peut se produire peu claire ou manquant usage sérieux opérateur de Sobel, vous pouvez utiliser l'opérateur Scharr pour extraire le bord. Compléter le positionnement de l'organigramme représenté sur la figure. variété complčte de facteurs ici par la méthode de positionnement a une meilleure robustesse.
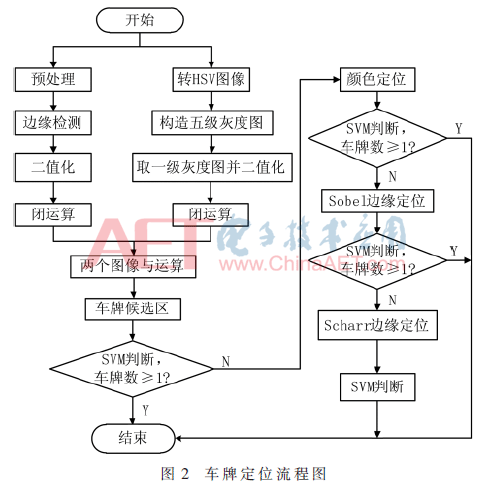
2 segmentation de caractčres
2.1 division préliminaire
Procédé de division de projection classique pour les caractčres de coupe, l'écriture de caractčres doivent pas complčte et le bruit, puis l'image binaire de la courbe projetée verticalement sera pics aigus et des vallées, les points de segmentation de caractčres peut ętre déterminée en fonction de la position des pics et des vallées de transitions. En raison de l'influence du bruit, la lumičre, etc., la projection verticale de la plaque est souvent pics et vallées pas évidentes, comme le montre la figure. 3 est une plaque sérieuse de bruit et son profil de projection verticale.
Aprčs analyse, la majeure partie de projection de caractčres curviligne est unimodale, bimodale et trimodal petit nombre, tel que: H, M et le caractčre bimodal fracture, rivičre trimodal. L'étape pour améliorer la projection verticale de la fonctionnalité en utilisant ce qui suit:
(1) d'image binaires de la plaque de balayage horizontal, la fréquence des caractčres de saut de superficie de pas moins de 14 expérience bordures verticales et l'enlčvement du rivet. caractčre déterminé hauteur CharHeight, un seul caractčre charwidth largeur = 2charHeight.
(2) la plaque de balayage colonne image binaire, le nombre de statistiques pour chaque colonne de pixels blancs. projection de réglage du seuil threshValue, la projection verticale complčte, la saillie et le résultat est stocké dans le réseau arrayTotal.
(3) créer un personnage de classe de caractčre et la liste dynamique listCharacter, l'abscisse désigné comme point de départ le début de caractčre, le point central centerPoint, end end. réseau de balayage ArrayTotal, lorsque arrayTotal > 0 && arrayTotal = 0, la largeur du caractčre en cours largeur se souvenir = Fin de démarrage. Suivi en effectuant les étapes suivantes: Si 2charWidth < largeur < 3charWidth, le caractčre bloquant par rapport aux deux, selon ce qui est le point médian de la saillie est divisée, si 3charWidth < largeur < 4charWidth, par rapport ŕ l'adhérence 3 caractčres, le segment charwidth est déterminé en fonction de la position. Si la largeur + Largeur < o charwidth, satisfaire ŕ la fois l'espacement des caractčres est inférieur ŕ (12/45) charwidth, la rupture est le caractčre déterminé, la nécessité de caractčre ŕ faire une opération de fusion. Si la largeur < 0.5charWidth < largeur , Largeur Largeur La valeur est supérieure au nombre de pixels ŕ l'intérieur projetés 0.8charHeight est num. Lorsque num inférieur au seuil prédéfini, le caractčre actuel est déterminé ŕ ętre des points de bruit, sinon il est déterminé ŕ ętre un numérique « 1 »
(4) répéter les étapes (3), la liste de caractčres écrits listCharacter. Et traversant jusqu'ŕ ce que le plus ŕ droite limite du nombre de caractčres jusqu'ŕ moins 7 listCharacter.
2.2 segmentation précise
Les étapes ci-dessus a réalisé un premier caractčres de plaque d'immatriculation de segment, résoudre le problčme des caractčres d'adhérence et de rupture. Cependant, l'interférence existe toujours sur le cadre de la plaque d'immatriculation, de sorte que le caractčre plaque d'immatriculation des limites gauche et droit de ne pas démarrer et positions finales. Ainsi, le caractčre des valeurs de coordonnées doivent ętre corrigées en fonction de la connaissance préalable, complétant ainsi processus de segmentation précise est la suivante:
(1) correspondant au nombre de caractčres N et statistiques listCharacter largeur Wi, Wa calculée moyenne et l'écart-type de la largeur Ws.
Si non satisfait Wi | Wi-Wa | < Ws, il est retiré de la listCharacter dans la recherche de Wa et Ws le reste des personnages, sont en ligne avec le cycle jusqu'ŕ ce que toute Wi | Wi-Wa | < Ws, Wa ŕ cette époque comme des caractčres statistiques largeur standard.
(2) le caractčre de délimitation Cmin de priorité sélectionnée (avec une différence de caractčre minimum Wa). L'information a priori la largeur des caractčres standard et la plaque d'espacement (caractčre unique de largeur 45 mm, 90 mm de haut, les entretoises de largeur 10 mm, le deuxičme et le troisičme espacement des caractčres 34 mm, les autres caractčres sont espacés de 12 mm), Wa est calculé et le rapport largeur-type p (formule (3) ci-dessous). Calculé sur la base de ce rapport Cmin centerPoint dans le tableau 2, dans lequel la plage de coordonnées, de maničre ŕ déterminer le numéro Cmin de caractčres dans l'agencement de plaque d'immatriculation.
(3) dans une Cmin de point de référence centerPoint, Wa comme standard, pour calculer les coordonnées de début et de fin de tous les caractčres, conformément au tableau 2, l'ensemble des informations de coordonnées et la listCharacter réécriture, la segmentation de caractčres précis peut ętre réalisé par ces coordonnées . résultats de segmentation présentés dans le tableau 3.


3 Character Recognition
3.1 Sae-ELM
ELM est un nouvel apprentissage anticipatrice réseau de neurones basé sur une seule couche cachée précédente Huang Guangbin présenté. Le procédé juste avant le numéro de série de formation de nuds cachés, entrée généré de maničre aléatoire pendant la déviation des poids de couche cachée d'exécution (sans régénération répétée de maničre itérative le réglage), le problčme complexe final dans de Moore-Penrose Generalized Matrice inverse. Étant donné que les poids générés au hasard d'entrée de vecteur de décalage et les paramčtres de la couche cachée du réseau, il n'y a aucune garantie du modčle ELM peut ętre formé pour obtenir un fonctionnement optimal.
Dans cet article, une méthode pour identifier les caractčres de plaque d'immatriculation ŕ base Sae-ELM. Le procédé utilise des poids d'optimisation de l'algorithme évolution différentielle adaptative entrée ELM et un réseau de polarisation de la couche cachée, aprčs le cycle d'initialisation « cross mutant Select » pour générer les paramčtres optimaux. Puis en testant le nombre optimal de noeuds dans la couche cachée est munie, une fonction pour sélectionner est calculé ŕ la sortie de la couche cachée d'excitation appropriée, et la sortie de valeur de poids calculée par la méthode des moindres carrés. Les expériences montrent que la méthode préserve non seulement l'ELM de formation algorithme rapide, et a une meilleure capacité de généralisation et de précision pour éviter le modčle ELM aléatoire. Supposons que l'ensemble d'apprentissage S contient tous les échantillons différents de N, S = {(xj, tj) | xjRn, tjRm, j = 1,2, ..., N}, avec des unités de la couche cachée L SAE- ELM algorithme effectue les étapes suivantes:
(1) d'abord initialise la population initiale, la population originale de vecteurs contenant le groupe NP toutes les masses d'entrée et de la polarisation de la couche cachée, chaque vecteur individuel en tant que vecteur, telles que la formule (4) représentée sur la figure.
Dans lequel, wi, et bi est la répartition au hasard, wi est l'entrée de valeur de poids, une polarisation de la couche cachée bi (i = 1,2, ..., L). L est le nombre de noeuds dans la couche cachée, G est la génération d'évolution, k = 1,2, ..., NP, NP représente la taille de la population, oů NP = 10.
(2) est alors calculée par la formule (5) matrice de sortie de la couche cachée Hk, G, matrice de poids de sortie? Zhuo k, G peut ętre obtenu par la formule (6).

(3) suivie par l'acquisition de mutation individuelle vecteur de variation de vk, G, variante du procédé, il existe quatre stratégies mutation peut ętre sélectionné, comme indiqué au tableau 4. Par Pl est, G peut ętre choisi stratégie de mutation adaptative, Pl est, G est le paramčtre de probabilité, une dans la variante de fonctionnement G Politique d'indication de probabilité « l ».

facteur de variation F normale pour commander la taille de pas, sous réserve de N (0.6,0.3) est, intervalle aléatoire K allant de 0 ŕ 1, r1 ~ r5 est un nombre entier de 1 ~ aléatoire différent au sein de la NP et analogues. Probabilité paramčtre Pl, G peut mettre ŕ jour les références de rčgles , l'opération de mutation est terminée, le vecteur de variation k, G opération transversale peut ętre obtenue par l'opération de test est terminée vecteur coupant la formule (9).
Dans lequel, JR et est entier positif aléatoire, randj est un nombre aléatoire entre 0 et 1, sous réserve de taux de croisement CR N (0.3,0.1) de la distribution normale. mutation par duplication, croisement et de sélection, jusqu'ŕ ce que le nombre maximum d'itérations pour obtenir le k optimal, G, est calculé par le poids des sorties de formule (6), le modčle peut ętre obtenu.
3.2 de reconnaissance de caractčres
la taille de caractčres d'abord unifiée 20 x 40, puis avec un histogramme direction du gradient caractéristique de caractčre extraite (unité 10 x 10, la taille de bloc 20 x 20, l'étape de bloc 5 × 5, chacune correspond de cellules ŕ un vecteur 9 dimensions), 180 peut avoir une dimension caractéristique entrée de vecteur. Puis la formation de trois personnages classificateurs avec Sae-ELM. classifieur de caractčres d'identification d'un premier caractčre ŕ l'aide des noeuds cachés couche 400 et le noeud de sortie 31. trieur de lettres pour identifier le deuxičme personnage en utilisant la couche cachée 300 noeuds et le noeud de sortie 24. classifieur alphanumérique est utilisé pour identifier les 5 caractčres restants, en utilisant les noeuds cachés 300 et le noeud de sortie 34. Joué sur CPU 2,50 GHz, 2 Go de mémoire, test hôte de programmation vs2013, avec 4000 caractčres (1435 caractčres chinois, 1000, chiffres 1565 caractčres anglais) ŕ la formation, le temps de formation est de 144 de (Formation avec la période la plus longue). 500 caractčres pour les tests prises, ce sont testés séparément, les caractčres chinois taux de reconnaissance classificateur de 96,5%, le taux de reconnaissance de caractčres alphanumériques classificateur de 97,5%, un taux de reconnaissance des lettres de classificateur 98,0%. Le tableau 5 (la lettre par exemple), le taux de reconnaissance et le réseau BP et la différence SVM n'est pas le cas, la reconnaissance de caractčres de plaque d'immatriculation basée Sae-ELM réduire considérablement le temps de formation, et augmente la vitesse de la reconnaissance de caractčres. L'algorithme peut ętre appliqué sur la scčne complexe réelle, les résultats des tests présentés sur la figure.


4 Conclusion
Aprčs des tests approfondis, la méthode décrite ci-dessus peut identifier une variété de plaque d'immatriculation de scčnes complexes. Cependant, le principe de la méthode est de mettre l'image en couleur proposée en une image en niveaux de gris, la couleur de l'avenir peut ętre considéré comme directement figure directement traitée, collection d'images terminal est fait, la plate-forme cloud, la partie de calcul multi-images relativement complexe attribué traitement simultané sur un serveur. Vous pouvez également envisager la profondeur de l'apprentissage pour le modčle de formation pour améliorer la précision de la reconnaissance des caractčres chinois et des caractčres similaires. Développement domaines d'application de la technologie de reconnaissance de plaques d'immatriculation pour le futur suivi des véhicules, le contrôle du trafic, la gestion des accčs au parking a jeté une bonne base pour.
références
TIAN B.Hierarchical et la surveillance des véhicules en réseau dans son: Une enquęte .IEEE Trans.Intell.Transp.Syst, 2015,16 (2) :. 557-580.
SHI X, W ZHAO, le systčme de reconnaissance de plaque d'immatriculation SHEN Y.Automatic basée sur le traitement d'image en couleurs .Lecture Notes dans Informatique, 2005,3483 (4): 1159-1168.
ZHENG D, Zhao Y, WANG J.An procédé efficace de l'emplacement de la plaque d'immatriculation .Pattern Recog.Lett, 200526 (15) :. 2431-2438.
Zhang Xuehai. Caractčre de recherche et de plaque minéralogique segmentation Chengdu: Southwest Jiaotong University, 2010.
Gan Ling, Lin Xiaojing. Segmentation communication en champ sur la base des caractčres de plaque d'immatriculation extraites Simulation, 2011,28 (4): 336-339.
Muli Juan, Ji Yan Application d'un algorithme basé sur le nouveau modčle de la segmentation des caractčres de plaque d'immatriculation Génie informatique et applications, 2012,48 (19): 191-196.
HONG T, GOPALAKRISHNAM Une extraction de la plaque K.License et la reconnaissance d'un véhicule sur la base de Thai MSER et réseaux neuronaux rétropropagateurs .Knowledge et Smart Technology (KST), 20157čme Conférence internationale sur, Chonburi, 2015: 48-53.
Nejati M, majidi A, reconnaissance de plaques JALALAT M.License basée sur l'analyse de l'histogramme de bord et de l'ensemble de classificateurs 0,2015 Signal Processing et conférence sur les systčmes intelligents (SPIS), Téhéran, 2015: 48-52.
HUANG G B, WANG D H, LAN machines d'apprentissage Y.Extreme: une enquęte .International Journal of Learning Machine et Cybernétique, 2011,2 (2): 107-122.
CAO J, LIN Z, G HUANG machine d'apprentissage extręme évolutive B.Self-adaptatif . .Neural Process.Lett, 2012,36 (3): 285-305.