Prévision et analyse de la consommation électrique de chauffage sur la base de la plate-forme de données de grande
0 introduction
Ces derničres années, les chercheurs classifient les consommateurs d'électricité, l'électricité et d'autres caractéristiques comportementales d'un certain nombre d'études. Par exemple, le document est divisé en secteurs proposé la classification conventionnelle basée sur le regroupement des utilisateurs; document autre type d'utilisateurs résidentiels d'électricité que l'objet de la recherche, et grâce ŕ une combinaison d'Internet et de nuages K-means maničre algorithme , les clients résidentiels seront divisés en cinq catégories et analyse les différents types de comportement des utilisateurs, la littérature - du point de vue de la charge de l'électricité, l'industrie ou les utilisateurs ŕ domicile de classer, de fournir une référence plus ciblée pour la prise de décisions d'entreprise base, tels que la puissance ordonnée, puissance de cręte, a une certaine signification pratique. Les chercheurs ont d'autres discussions de la formation de la stratégie intelligente d'énergie ŕ améliorer efficacement l'efficacité des utilisateurs d'électricité, de réduire la consommation d'énergie des ménages, l'électricité économique est trčs instructif. En ce qui concerne les ménages, la littérature mis en place un certain nombre d'utilisateurs ŕ la maison, surface, nombre de membres de la famille, la consommation d'électricité, puissance de pointe, les appareils ménagers, tels que le nombre de données chaque jour du modčle dimensionnel, puis utiliser beaucoup d'électricité pour les particuliers pour analyser les données l'exploitation miničre. En tenant compte des charges utilisateur en plus les utilisateurs affectés facteurs directs propres habitudes et revenus économiques, mais aussi étroitement liés aux facteurs indirects des gaz, météo, température minimum local, vacances importantes et attributs géographiques, littérature - considéré séparément ces facteurs, analyse de la différenciation des caractéristiques de comportement de la consommation d'électricité, fournir un soutien efficace pour les données de réponse ŕ la demande, par exemple, le rapport de puissance de cręte, facteur de charge, le coefficient de l'électricité de la vallée, section plane en pourcentage de l'électricité, et analogues.
Sur la base de la plate-forme de données grand, par la méthode de prévision du réseau de neurones BP pour étudier divers facteurs qui influent sur la consommation d'énergie de l'utilisateur du chauffage, le chauffage ŕ établir le modčle de prévision de la demande d'électricité de l'utilisateur et l'application finale ŕ Pékin « le charbon en électricité » l'intelligence du projet service sur la plate-forme. Le présent document examine ŕ fond le grand ensemble de données d'ingénierie, d'identifier les principaux facteurs influant sur la consommation d'électricité pour le chauffage. Ceci est utile pour réduire les coűts de chauffage et d'améliorer la construction des réseaux de distribution d'utilisateurs et les utilisateurs de la configuration de la charge électrique pour fournir un soutien de données, il a un sens positif.
1 Intelligent Services Platform Design Architecture
Dans cet article, l'architecture d'ensemble de la plate-forme de service intelligente est divisée en cinq niveaux suivants: couche de base, la couche d'acquisition de données, l'analyse de la couche de données, la couche application intégrée, la couche de présentation et de stockage unifié, spécifiquement montré sur la figure 1.
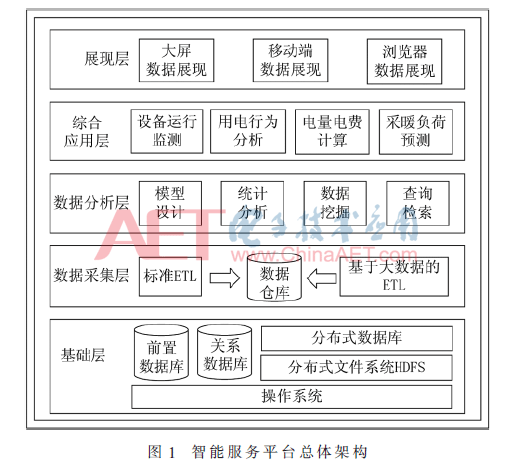
architecture fonctionnelle Internet comme le montre la figure 2.

Les utilisateurs par le biais de l'équipement de chauffage surveillance en temps réel intelligente de chauffage APP maison, équipement d'acquisition, d'avertissement de situations anormales, tout en chauffant APP contrôle intelligent par l'équipement de chauffage intelligent, l'équipement de chauffage et de la quantité d'informations sur les frais, les subventions et la recherche d'informations pratiques, pour améliorer la qualité des services d'alimentation.
Entreprise par l'acquisition, l'exploitation et l'analyse des informations utilisateur sur le « charbon ŕ l'électricité » projet, le fonctionnement des équipements de chauffage, la température intérieure, des informations météorologiques et d'autres données pour comprendre les habitudes de chauffage préférences de l'utilisateur, afin d'améliorer la précision de la prévision de chauffage électrique données utilisateur , la zone de données de charges combinées, afin d'améliorer les données de construction de réseau de distribution de charge et l'utilisateur fournit une configuration de support.
Il convient de noter que, dans la plate-forme sous-jacente utilise le moteur de calcul et la mémoire de stockage de données sur Hadoop HDFS Spark des technologies Big Data. HDFS stockage distribué pour les applications Hadoop est principalement utilisé pour répondre ŕ la faible coűt, haute tolérance de panne, les données ŕ haut débit de traitement et d'autres grandes caractéristiques de la demande. Spark architecture avancée, l'efficacité opérationnelle, la facilité d'utilisation, etc., mais il peut ętre connecté de façon transparente avec Hadoop, fournissant la solution globale. Aussi dans Spark apprentissage machine a un avantage naturel, en termes de processus itératif de calcul 100 fois plus rapide que Hadoop, le systčme a une bonne évolutivité.
la collecte de données d'échantillon, des capteurs de courant et de tension, en fonction de la fréquence par un capteur de température d'humidité intervalle de 15 min pour l'acquisition de données installé dans la maison d'un utilisateur typique pour sélectionner l'ensemble de la saison de chauffage capturé ŕ 1000 les données de surveillance de dix mille dispositifs fournissent la plate-forme de service de données météorologiques les données météorologiques historiques données saison chauffage, ŕ condition de l'acquisition par les fournisseurs d'outils ETL pour pré-Hive base de données lit plate-forme de services de données sur l'entrepôt de données grand intelligente.
NN formation de modčle et un procédé de prédiction représenté dans la figure 3. La principale étape d'analyse est la suivante:
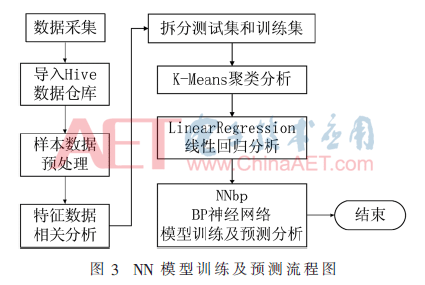
(1) préparés par les procédures de nettoyage des données d'emploi Task pySpark, les anomalies recueillies, des deletions, des données duplications des données de prétraitement, et la consommation de puissance pour chaque statistiques de segments de temps;
(2) effectuée par l'analyse de corrélation caractéristique des données collectées, en supprimant les données caractéristiques ŕ faible corrélation et les données caractéristiques finales retenu cinq corrélation est supérieur ŕ 0,5;
(3) la normalisation des données traite des données caractéristiques, et l'ensemble de données est divisé en deux apprentissage et de test;
(4) fournit des K-means algorithme bibliothčque apprentissage automatique MLlib pour les données de jeu de formation ont été analysées ŕ l'aide modčle de cluster moteur Spark;
(5) fournit des bibliothčques algorithme de régression linéaire régression linéaire analyse de régression linéaire apprentissage automatique MLlib en utilisant le moteur d'allumage;
(6) fournit BP algorithme de réseau neuronal NNbp bibliothčque d'apprentissage automatique MLlib pour former le modčle et l'utilisation du moteur d'allumage d'analyse prédictive.
Il peut rapidement traiter et analyser les données ŕ travers la plate-forme, afin d'améliorer l'analyse des données et l'efficacité de prise de décision.
2 BP conception du modčle et de la configuration
Dans cet article, le réseau BP (Réseau rétropropagation) pour former le modčle et l'analyse prédictive. Le réseau BP se compose d'une couche d'entrée, une couche cachée et une couche de sortie. Cette étude a utilisé m × k × n modčle de réseau BP ŕ trois couches, la sélection du réseau d'une fonction de transfert de type S f (x) = 1 / (1 + ex), selon la fonction d'erreur de rétropropagation E = i (Ti + Oi) 2 / 2 (Ti est la sortie désirée, la sortie Oi de calculer le réseau), et d'ajuster en permanence les poids du réseau de sorte que la valeur de seuil E atteint une fonction d'erreur minimum.
BP méthode de prédiction de réseau de neurones en fonction de la « température extérieure, l'humidité extérieure, température intérieure, la zone des locaux de l'abonné, la population » comme variables indépendantes, en ajustant de maničre itérative les paramčtres du modčle, construire des modčles prédictifs. Ainsi, le nombre de noeuds de la couche d'entrée 5, le nombre de noeuds de la couche de sortie est 1. Dans le processus de conception du réseau, déterminer les neurones de la couche cachée est trčs important. Trop de neurones cachés augmentera la quantité de réseau informatique, sujette ŕ problčme surajustement, le nombre trop faible de neurones peut affecter les performances du réseau, ne peut pas obtenir l'effet désiré. Le réseau est directement lié au nombre et ŕ la complexité des neurones de couche cachée de problčmes pratiques, ŕ condition que le nombre souhaité de neurones, et les erreurs des couches d'entrée et de sortie. L'expérience sur le problčme du nombre de neurones de couche cachée sélectionnée en référence ŕ la formule empirique suivante:
Dans laquelle, n est le nombre de neurones dans la couche d'entrée, m est le nombre de neurones dans la couche de sortie, a est une constante comprise entre .
La formule empirique, le calcul du nombre de neurones est de préférence compris entre 4 et 13, sélectionner le nombre de neurones dans la couche cachée 6 dans cette expérience. fonction sigmoďde fonction différentiable linéaire et réseau de neurones BP est généralement utilisé en tant que réseau de fonction d'activation. Etant donné que la sortie du réseau est normalisée ŕ la gamme de , ce modčle de prédiction sélection tansig S Type fonction logarithmique en tant que couche de sortie fonction d'activation des neurones. Le modčle de prédiction est sélectionné réseau de 5000 époques, un objectif d'erreur devrait 0,000, 0,01 le taux d'apprentissage lr.
3 résultats et analyse expérimentale
Dans cet article, en 2017 et 2018 mis en uvre le projet « charbon ŕ l'électricité » d'un utilisateur ŕ Pékin des données mesurées pour analyser l'ensemble de données sélectionnée comprend: température extérieure, l'humidité extérieure, température intérieure, la zone des locaux de l'abonné, la population et la consommation d'énergie pour le chauffage montant. les données d'utilisateur de papier est plus grande que l'utilisation réelle de chauffage électrique ŕ 40 jours, soumis ŕ un traitement de données et lavage, les heures de consommation d'énergie de chauffage prévus. Les données normalisées pour donner un total de 24150 données efficaces. La consommation d'énergie de chauffage résultant calculé par le modčle utilisateur, prédicteur 16 des données d'apprentissage 180 comme montré sur la Fig.

La figure 4 montre la valeur prédite et la valeur réelle de la charge de chauffage sur la base des caractéristiques de l'acquisition de données calculé. La formule de calcul de l'erreur relative moyenne et l'erreur, l'erreur quadratique moyenne de l'ensemble d'apprentissage a été calculé ŕ 0,82194. Comme on peut le voir sur la figure, les données réelles et les courbes de données prédites ayant une consistance dans les charges de l'utilisateur les données en temps réel locaux complets et exacts, modčle prédictif utilisé dans cette étude peut prédire l'utilisateur 24 heures de consommation d'électricité. Avec l'accumulation et d'améliorer la précision de la formation du modčle de données réelles, et, finalement, permettre la prédiction des données d'utilisateur réel.
4 Conclusion
Dans cet article, la plate-forme de service intelligente basée sur l'analyse de grands volumes de données, et le modčle d'utilisateur et prévoir l'utilisation de la puissance réelle par le réseau BP, la cohérence des données prévues et réelles. Bien sűr, la précision de la prévision réelle non seulement liée ŕ la température ambiante, mais aussi liée aux caractéristiques de la population utilisateur le nombre de ménages, tels que la taille des chambres et des préférences. Par conséquent, le manque actuel d'une quantité efficace des données, nous pouvons réaliser la modélisation et la prévision ciblée grâce ŕ des données supplémentaires suivantes pour améliorer encore la précision du modčle, laissez le systčme jouer une valeur plus grande. Établi dans ce systčme de papier a été utilisé ŕ Beijing projet « charbon ŕ l'électricité », la configuration a une valeur importante pour améliorer la construction du réseau de distribution et les utilisateurs de la charge d'électricité.
références
Feng Xiao Po. Selon la classification de l'utilisateur courbe de puissance de charge réelle Baoding: Chine du Nord électrique Power University, 2011.
Zhang Su Hong, Liu Jianming, ville de propylčne Zhao. Recherche et analyse sur le comportement des résidents de l'électricité du modčle de nuage . Power System Technology, 2013 (6): 65-69.
Wangbing Xin, Hou Yan Fang Hongwang oriented "déplacement de la charge" de la puissance d'analyse du comportement des clients électrique Sciences Télécommunications, 2017,33 (5): 164-170.
Zhangtie Feng, Gu Mindy. L'application d'extraction et le mode charge utilisateur PUISSANCE Sommaire . Power System Technology, 2016,40 (3): 804-811.
Sun Yi, Liu Di, Li Bin, etc. stratégie d'optimisation en temps réel basé sur la corrélation de la charge électrique des ménages . Power System Technology, 2016,40 (6): 1825-1829.
Sun Yi, Feng Yun, Chan Choi puissance sur la base de charge du consommateur comportement dynamique adaptatif codant pour une analyse de clustering K-means Puissance Science et technologie, 2017,32 (3): 3-8.
Zhao Li, Xing attente Zhe, Hu juin électricité basée sur la masse de l'intelligence algorithme k-moyens d'analyse de données améliorée . Power System Technology, 2014 (10): 104-109.
Lee, Xin Jiang, Rural Pékin « le charbon en électricité » analyse la charge de l'utilisateur et politique de l'offre China Power Enterprise Management, 2017 (10): 56-58.
Liu Xu, Luo Diansheng conception logique. La charge ŕ court terme et la charge en direct les facteurs de prévision du temps de résolution . Power System Technology, 2009 (12): 98-104.
Su approprié, Li Kangping, Yan Yuting. Algorithmes de recherche ŕ base de regroupement spatial Densité de la population et la charge de gravité modčle de classification de modčle d'utilisation de puissance Power Automation Equipment, 2018 (1): 129-136.
Informations sur l'auteur:
Yang Shuo, Sun Qin Fei, Zhu Jie, Chen Ping
(State Grid Electric Power Research Institute, Beijing Electric Power Company, Beijing 100075)