avant-propos
Cet article décrit l'algorithme d'arbre stimulant pour renforcer et améliorer l'algorithme de gradient (GBDT), l'algorithme GBDT est utilisé pour résoudre la régression et de classification, et la capacité de généralisation est trčs forte, cet article résume l'algorithme GBDT en termes simples.
annuaire
1. arbres de décision simples différents et stimuler l'algorithme d'arbre
Il 3. Soulevez l'algorithme d'arbre
4. GBDT algorithme
5. GBDT fonction de perte commune
6. régularisation GBDT
7. GBDT et comparaison des modčles de AdaBoost
8. Conclusion
Un arbre de décision est un apprenant, en stimulant l'arbre est une méthode pour améliorer l'arbre de décision CART en apprenant de base. Ceci résulte de la section d'angle d'évaluation et l'angle de la fonction de perte pour décrire la différence. En supposant que le modčle d'apprentissage d'arbre de décision est f (x), afin d'améliorer l'arbre un total de K élčves faibles

, I = 1,2, ..., K.
Méthode d'évaluation 1. Résultats:
Pour une donnée entrée xi
Le modčle d'arbre de décision de sortie yi:

Stimuler le modčle arbre de sortie yi:


Oů i désigne un apprenant faible, T représente un modčle de classification (par exemple, régression linéaire logique, ou la fonction de signe)
2. La méthode de construction de modčle
(1) Le procédé de construction d'un modčle d'arbre de décision
L'application de la fonction de perte de l'arbre d'index Gini pour calculer la phase de génération de modčle est la fonction de perte de modčle de profondeur de l'arbre est réduit au minimum, afin de maximiser l'arbre de décision; étape d'élagage de l'arbre est la perte totale de régularisation occupée de la fonction, et enfin par validation croisée méthode pour sélectionner la meilleure sous-arbre;
(2) une méthode pour améliorer les modčles d'arbres
Une pluralité d'arbres de décision est la combinaison de levage d'arbres pour améliorer la capacité de la méthode d'apprendre, la complexité de l'arbre de décision est beaucoup plus faible que chaque arbre de décision unique, l'arbre de décision ne peut pas ętre si profond que pour maximiser l'arbre de décision unique pour minimiser la fonction de perte. Un arbre de décision est un membre de la famille de stimuler, les faibles apprenant généré itérations série pour améliorer la construction modčle d'arbre en réduisant au minimum les faibles apprenant chaque étape fonction de perte.

Parmi eux,

Arbre de décision,

Décision paramčtres Arbre, M est le nombre d'arbres.
Stimuler l'algorithme d'arbre:
algorithme d'arbre pour augmenter l'algorithme de distribution avant, supposons que l'arbre initial stimulant

Le modčle m-étape:

Parmi eux,

En tant que modčle, les paramčtres du modčle de la minimisation des risques actuelle déterminé par l'expérience


Dans lequel L représente une fonction de perte,

et

Il est une constante, un (1) montre que, aussi longtemps que nous savons que la fonction de perte L, on peut obtenir chacun des paramčtres du modčle

Il peut également ętre comprise comme le modčle actuel

Pour tenir sur un modčle de résidus. Par conséquent, le principe de l'algorithme est d'améliorer l'arbre avec l'arbre actuel pour tenir sur un modčle de résidus pour minimiser la perte de valeur de la fonction actuelle.
[Exemple] Si quelqu'un est de 30 ans, nous avons d'abord utilisé pour ajuster le 20 ans a trouvé la perte de âgé de 10 ans, 6 ans lorsque nous avons utilisé pour adapter cette itération se poursuit jusqu'ŕ ce que la fonction de perte pour répondre ŕ nos besoins, ce qui est pensé pour améliorer l'arbre.
Vous avez déjŕ demandé pourquoi on ne va pas directement ŕ l'âgé de 30 ans pour s'adapter, faire correspond ŕ pas ŕ la profondeur de l'arbre de décision afin de maximiser le modčle qui en résulte est pas un classificateur faible, ce qui conduit ŕ posent des problčmes surajustement.
Nous regardons en arričre une fois de plus sur un exemple, si nous avons d'abord équipé d'un enfant de 10 ans ŕ 20 ans constaté que la perte, puis utilisez le 8 ans pour s'adapter ŕ la perte de de 12 ans, cette itération se poursuit, avec la section pour atteindre la męme valeur de la fonction de perte nous avons besoin de plus d'itérations, ce qui est GBDT la pensée de l'algorithme: en utilisant la fonction de perte de résidus d'approximation de gradient négatif, les arbres de régression correspondent ŕ la fonction de perte le plus petit pour obtenir le cycle actuel de gradient négatif. Parce que l'arbre est un résidu d'ajustement de levage directs, afin d'atteindre la męme valeur de fonction de perte, étape d'itération pour améliorer arbre nécessite beaucoup plus petit.
étapes:
(1) avec le gradient de négatif de la fonction de perte des résidus d'approximation, exprimée en tant que:

(2) l'arbre de régression en forme de gradient négatif, les nuds feuilles envoyer régions Rmj, j = 1,2, ..., J. Dans lequel J est un numéro de noeud feuille, m est les morceaux de m arbres de régression.
(3) pour chaque noeud de feuille dans l'échantillon, on a calculé la fonction ŕ minimiser les pertes, résultant en une valeur de sortie du meilleur nud feuille Cmj de forme, comme suit:

(4) modčle d'arbre de régression de mise ŕ jour:

(5) pour obtenir le modčle d'arbre de régression final:

Il peut ętre difficile de comprendre que la troisičme étape, nous pouvons comprendre dans le modčle de reprise de la demande afin de minimiser la direction du gradient de négatif. direction du gradient négatif est entendu ŕ la division arbre de régression rčgle gradient négatif de fonction de perte, la rčgle de chercher ŕ minimiser la fonction de perte.

Dans lequel, m représente le nombre d'itérations,

M représente un modčle d'apprentissage itérative arrondit au total,

Le modčle perte fonction, vu des principes pour améliorer l'arbre, la perte de la fonction du modčle avec l'augmentation du nombre d'itérations augmente. Au-dessus de, respectivement, le gradient et le gradient de négatif des fils verts et rouges, lorsque nous utilisons le modčle actuel d'apprentissage
Augmente dans le sens du gradient négatif, la perte de la fonction est la plus forte baisse, donc, idée GBDT de l'algorithme est possible.
PS: Li Accrocher professeur P152 « méthodes d'apprentissage statistique » d'expression de l'algorithme GBDT:

Personnellement, je pense que la formule pourrait ętre une meilleure représentation du modčle:

Deux sections en vue de dessus, pour améliorer l'arbre de décision d'arbre est équipé d'une fonction de perte, arbre de décision GBDT est monté sur un gradient de la fonction de perte. Par conséquent, comme conscient depuis longtemps du modčle de fonction de perte, les paramčtres peuvent ętre calculés avant chaque tour de l'algorithme faible modčle de distribution de l'apprenant, Cette section résume la fonction de perte commune GBDT.
(1) algorithme de classification
a) la fonction de perte exponentielle:

Correspondant gradient négatif:

b) Nombre de perte de fonction

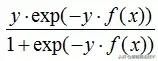
(2) l'algorithme de régression
Ici, ne pas discuter les plus couramment utilisés fonction de perte, comme l'erreur quadratique moyenne et la fonction de perte absolue. Cette section a une bonne robuste perte de Huber et la perte de valeurs aberrantes quantile.



Parmi eux,


modčle Régularisation afin d'éviter surajustement, régularisation GBDT Il existe trois façons principales:


v gammes: 0 < v 1. La formation ensemble pour atteindre le męme effet d'apprentissage, (2) la nécessité de nombre d'itérations, ŕ savoir (2) moins le modčle de type complexe.
(2) sans remplacement du rapport de consigne de la formation d'échantillonnage du v (0 d'échantillonnage < v 1). Montage prendre quelques échantillons font arbre de décision GBDT peut réduire la variance, mais l'écart augmente.
(3) la fonction de perte pour adapter la taille des arbres de régression de gradient rond, élagage algorithme processus élagage CART de référence.
En supposant que l'initialisation



Comparer ces style deux, vous ne trouverez pas le poids du modčle GBDT i, parce que: AdaBoost chaque fois pour différentes distributions (poids) des ensembles de données d'origine ont été formés pour donner une série d'apprenants faibles, puis combiné avec le droit ŕ la valeur finale modčle, GBDT modčle ne poids parce que le faible apprenant est monté sur un résidu, avec l'augmentation du nombre d'arbres de régression, les résidus plus en plus petits, et ne nécessite donc pas les poids faibles de l'apprenant.
Cet article décrit la levée des algorithmes stimulant algorithme et aromatiques arbre GBDT pour améliorer l'algorithme d'arbre pour s'adapter autour de l'apprenant est faible générée sur un résidu, autour de la faible apprenant GBDT équipons algorithme sur une fonction de perte le gradient de négatif généré. Stimuler l'algorithme d'arbre et GBDT par des algorithmes d'arbres de régression CART sont les apprenants faibles, assurez-vous que la perte de modčle de fonction, stimuler arbre et GBDT peut ętre construit pour il y a l'algorithme de distribution.
référence: https://www.cnblogs.com/pinard/p/6140514.html
Source: algorithmes d'apprentissage machine ŕ ces choses