
@ Source Vision Chine
Voix doute l'importance de l'interaction homme-ordinateur, les entreprises nationales et étrangčres, les deux ŕ la vitesse de reconnaissance vocale, les aspects de précision et en plusieurs langues de l'innovation continue, mais quand la machine face ŕ ceux qui ont des accents, il semble pas sensibles: l'accent sera mis non seulement de se concentrer, ne répond pas, ou męme de devenir une entité distincte, aucune réponse. Comment résoudre le problčme de la reconnaissance d'accent, il est devenu le centre de la concurrence dans la prochaine étape de la voix intelligente, mais ce n'est pas seulement une simple augmentation du corpus sera en mesure de mettre ŕ niveau, mais heureusement il y a quelques entreprises ont commencé par la construction d'un nouveau modčle de voix, pour résoudre l'accent problčme .
Depuis Shoebox d'IBM et de mondes merveilles avčnement Julie Doll de la technologie de reconnaissance vocale a fait de grands progrčs. Il y a des rapports męme que, d'ici la fin de 2018, Google Google adjoint soutiendra plus de 30 langues. En outre, Qualcomm a mis au point un peut reconnaître les mots et les phrases d'un dispositif de reconnaissance vocale, jusqu'ŕ taux de précision de 95%. Et Microsoft a surpassés ses solutions de centre d'appels (service vocal intelligent) est plus précis que les humains ont élargi les services d'appel et plus efficace.
Mais il convient de noter que, bien que sous la bénédiction de l'apprentissage automatique, la technologie de reconnaissance vocale a fait de grands progrčs, mais maintenant le systčme de reconnaissance vocale est pas parfait. Par exemple, l'accent différents domaines, de sorte que cette technologie a une forte « région discriminatoire ». En rčgle générale, l'accent pour l'homme ne sont pas un gros problčme, et parfois les gens se sentent une sorte de charme exotique, mais la machine, c'est un écart insurmontable, nous pourrions ętre confrontés dans le processus de son développement le plus grand défi.
Des études ont montré que l'accent est l'un des défis de la technologie de reconnaissance vocale
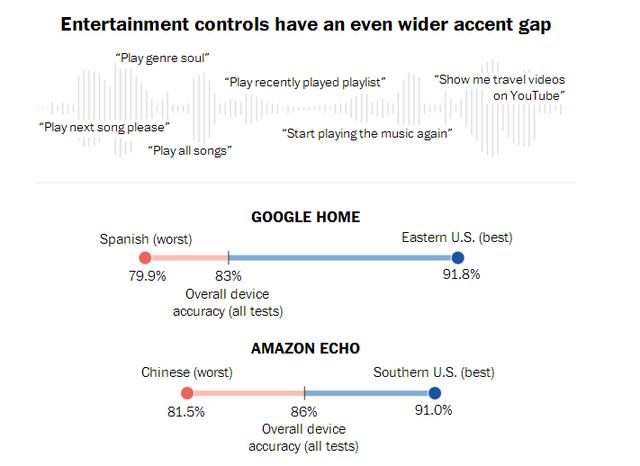
Récemment, le Washington Post en collaboration avec Globalme deux langues et Pulse société de recherche Labs, équipé d'un problčme d'accent de la technologie de reconnaissance vocale intelligente du haut-parleur de l'appareil a été étudié, la gamme étudiée de prčs de 20 villes aux États-Unis, plus de 100 participants émis des milliers de commandes vocales, les résultats ont montré des différences significatives dans ces systčmes existent dans la compréhension des gens de différentes parties de la langue.
Par exemple, la précision de Google Accueil Google identifie la reconnaissance intelligente accent haut-parleur Cisjordanie est supérieure ŕ 3% l'accent du Sud, l'accent et la précision de l'assistant de reconnaissance vocale Alexa accent Amazon Middle West de 2% inférieure de la côte est. Mais face au plus gros problčme est de maintenir l'accent non natif: Dans une étude, le contenu et les mots réels du groupe de test Alexa identifiés et les résultats ont montré aucun taux de précision allant jusqu'ŕ 30%. De plus, le visage de l'espagnol et le chinois comme premičre langue que les gens parlent anglais, ou si Google Accueil Amazon Echo, son taux de reconnaissance est le plus bas, vous le savez, Latino-américain et chinois sont les deux groupes d'immigrants .
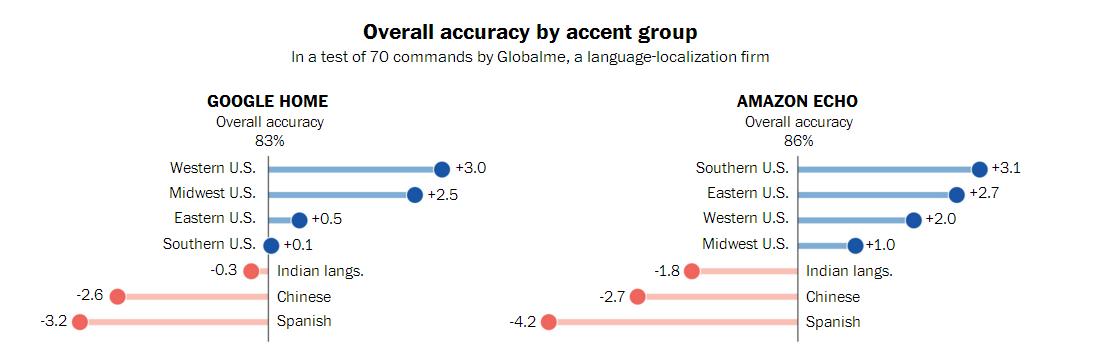
Bien que cette étude est informelle, il y a des restrictions, mais les résultats montrent encore que l'accent est toujours l'un des principaux défis auxquels sont confrontées les technologies de reconnaissance vocale. Ŕ cet égard, Amazon dit dans une déclaration, « Comme de plus en plus d'échanges de personnes ont des accents différents et Alexa, sera améliorée Alexa compréhension. » Dans le męme temps, Google a également dit que « dans l'expansion de l'ensemble de données en męme temps, nous continuerons d'améliorer les capacités de reconnaissance vocale de Google Home ".
En fait, pas seulement une partie du bas Amazon Echo et Google Home, l'adoption Cortana Microsoft et Apple Siri est également vrai qu'ils ont besoin en temps opportun pour améliorer sa propre technologie de reconnaissance vocale pour permettre aux utilisateurs de se sentir satisfaits en męme temps, mais aussi dans le monde ŕ portée étendre leur influence.
Męme corpus augmenté ne peut pas résoudre le problčme de la reconnaissance d'accent
Avec le développement de l'intelligence artificielle, la voix est devenue l'une des façons de base les gens interagissent avec l'ordinateur, de sorte que męme avec la compréhension de trčs faibles écarts, cela pourrait signifier un énorme obstacle. En d'autres termes, les différences linguistiques peuvent donner ŕ ceux du systčme de base scientifique et technologique moderne pour apporter des pičges potentiels, aprčs tout, en plus de la cuisine et salon, haut-parleur intelligente au lieu de travail de l'utilisateur, les écoles, les banques, les hôpitaux et les hôtels et autres lieux supporter un rôle plus important, en plus du dispositif de commande, mais aussi ŕ l'information de transmission, et faire des travaux de recherche et de réservation.
Afin d'améliorer les circonstances d'accent assistant de reconnaissance vocale, comme Amazon et Google investissent des ressources, avec un nouveau systčme de test de formation linguistique et l'accent, y compris la création du jeu afin d'encourager l'utilisation des dialectes dans les différentes parties d'une conversation. Et comme des sociétés comme IBM et Microsoft, il sera de réduire le taux d'erreur par assistant vocal corpus Switchboard. Mais il se trouve, le corpus ne peut pas résoudre complčtement le problčme de l'assistant accent de reconnaissance vocale.
Ŕ cet égard, la responsabilité globale d'Accenture supervision AI Rumman Chowdhury a déclaré: « les données sont source de confusion, car les données reflčtent l'humanité de l'algorithme fait le mieux: la recherche de modčles de comportement humain. »
Cette situation est appelée algorithme « écart de l'algorithme », le degré de biais pour la réaction des modčles d'apprentissage de la machine ou les données de conception générés. Par exemple, il existe de nombreux rapports montrent que la sensibilité de la technologie de reconnaissance faciale - en particulier la technologie de reconnaissance d'images Amazon AWS Rekognition-- ont une grande tendance ŕ des préjugés. De plus, l'écart de l'algorithme apparaît dans d'autres domaines, comme le défendeur de prédire si les algorithmes de recommandation de contenu dans des applications telles que Google Nouvelles et la criminalité derričre l'avenir.
Construire le modčle de reconnaissance vocale pour améliorer le dialecte taux de reconnaissance
Bien qu'il y ait eu de nombreux préjugés de l'algorithme proposé géant contre des solutions telles que Microsoft, IBM, Facebook, Qualcomm et Accenture ont développé des outils automatisés pour la détection de biais d'Amnesty International, mais peu d'entreprises pour la technologie de reconnaissance vocale problčmes d'accent rencontrés proposent des solutions spécifiques. Ŕ cet égard, Speechmatics Nuance et il est devenu l'un des rares personnes.
Speechmetrics est une entreprise spécialisée dans les logiciels de reconnaissance vocale société de technologie Cambridge, a lancé a commencé il y a 12 ans un ambitieux programme visant ŕ développer plus précis que tout autre produit sur le marché, pack de langue plus complet. Il est entendu que le début de l'étude, l'emploi principal de l'entreprise circule la modélisation du langage statistique et des réseaux de neurones, et donc mis au point un modčle d'apprentissage de la machine peut gérer la séquence de sortie de mémoire.
2014, Speechmetrics ŕ travers un corpus de 10 giga-octets pour accélérer les progrčs de la modélisation statistique du langage, 2017 avec l'Institut du Qatar recherche (QCRI) pour développer le service de conversion de texte en langue arabe est calculé, on peut dire que c'est la société acquise un progrčs marquant.

En Juillet de cette année, la société a une nouvelle fois dépassé - développé avec succčs un systčme de reconnaissance vocale mondial anglais, y compris des milliers d'heures de plus de 40 pays de données vocales dans le monde entier et plusieurs dizaines de milliards de mots, que le soutien « tous les grands « accent anglais conversion de texte vocal. De plus, ce systčme est basé sur automatique Linguiste de Speechmatic, c'est un cadre AI pour apprendre une nouvelle langue en fonction de la langue en utilisant un mode de reconnaissance de la langue connue.
Dans l'essai d'accent particulier, Global English surperformé Discours API Cloud de Google et le pack de langue Cloud IBM anglais. Speechmatic selon que ŕ l'extrémité supérieure, la précision du systčme est plus élevée que les autres produits de 23% ŕ 55%.
Mais Speechmatics pas la seule entreprise qui essaie de résoudre le problčme de l'identification des accents.
Nuance a son sičge dans le Massachusetts, il a dit que la compagnie utilise une variété de méthodes pour faire en sorte que son modčle de reconnaissance vocale avec la męme précision peut ętre identifié environ 80 langues.
Par exemple, dans son modčle de reconnaissance vocale en anglais, la société collecte des données vocales et de texte 20 régions dialectaux de spécifiques, comprenant chacun un mot unique et son dialecte de prononciation. Ainsi, le systčme de reconnaissance vocale Nuance peut reconnaître que le mot « Heathrow » de 52 variantes différentes.
Récemment systčme de reconnaissance vocale Nuance a également été grandement améliorée. Les nouvelles versions du Dragon est la société a publié une suite logicielle voix-texte personnalisé, modčle d'apprentissage de la machine utilisée, peut basculer automatiquement entre plusieurs dialectes différents modčles en fonction de l'accent de l'utilisateur. En outre, par rapport ŕ l'ancienne version est pas de fonction de commutation automatique, la nouvelle version de la précision de reconnaissance anglais avec l'accent espagnol ŕ 22,5% pour le dialecte du sud des États-Unis, le taux de précision ŕ 16,5% pour l'accent anglais Asie du Sud le taux de précision plus élevé de 17,4%.
En fait, les chercheurs ont découvert depuis longtemps il y a les problčmes de reconnaissance vocale d'accent rencontrés. Ŕ cet égard, les ingénieurs et linguistes AI ont dit que la formation linguistique non autochtone est souvent difficile, parce que le modčle entre la langue ŕ plus d'une sorte de façons différentes pour passer. En męme temps, le contexte est également important, męme si les deux parties modifient également les nuances du dialogue. Mais ce qui est certain est que le manque de diversité des données vocales peuvent finir par inadvertance des « discrimination régionale ». En d'autres termes, Plus le nombre d'échantillons de parole de corpus et de la diversité, plus précis que le modčle a été - au moins en théorie .
Bien sűr, ce problčme ne sont pas seulement les entreprises américaines doivent ętre pris en compte. Baidu senior fellow au bureau de la Silicon Valley de Gregory Diamos a déclaré que la société fait face ŕ ses propres défis, ŕ savoir le développement d'une intelligence artificielle de peut ętre compris dans de nombreux dialectes chinois. En outre, de nombreux ingénieurs ont également dit que pour développer le genre d'accent non seulement répondre ŕ des questions, mais aussi libre de société de logiciels de conversation naturelle, est l'un des plus sérieux défis.
En mai de cette année, Google a introduit un systčme appelé le Duplex, le ton réaliste de la voix peut ętre appelée réservations complčtes restaurant, tout le processus est « pas lisse voix, » parce que le milieu sera mélangé, « ah », « euh » et le ton mot. Dans une certaine mesure, ce peuple de la technologie ont un tel sentiment: cette machine écoute mes paroles. Un utilisateur, il semble pris au pičge dans une zone grise, bien que l'on peut comprendre, mais il semble hors de l'air avec le robot.
Selon le cabinet d'études de marché Canalys, en 2019, il y aura prčs de 100 millions d'unités dans les ventes mondiales de haut-parleurs intelligents, et en 2022, environ 55 pour cent des ménages américains auront un systčme vocal intelligent. Dans la petite vue Zhijun, en étudiant un grand nombre de données vocales et modčles vocaux, la compréhension de la formation d'un lien clair entre les différents mots, des phrases et des sons, l'intelligence artificielle sera capable de mieux comprendre les différents accents, pour améliorer la reconnaissance.
Mais ne vous attendez pas une « solution miracle », aprčs tout, conformément au développement de la technologie maintenant, nous ne pouvons nous attendre ŕ bientôt ętre en mesure de développer un taux de précision trčs élevé, mais peut ętre appliqué ŕ un systčme de reconnaissance vocale pour tous les utilisateurs de la langue. Aujourd'hui, les utilisateurs peuvent répondre aux besoins des accents utilisés, fera.
Plus de contenu passionnant, l'attention des médias titane signal de micro (ID: taimeiti), titane ou télécharger les médias App