Technologie AI Revue de presse La profondeur de l'apprentissage de renforcement (RL) technologie peut ętre utilisée pour des tâches complexes d'apprentissage politique d'entrée visuelle, et a été utilisé avec succčs dans le jeu classique Atari 2600. Des recherches récentes dans ce domaine montre que, męme en contestant explorer des mécanismes tels que le jeu de vengeance de Moctezuma montré, il est également possible d'obtenir des performances surhumaines. Cependant, l'une des limites de la plupart des méthodes les plus avancées est qu'ils exigent beaucoup d'interaction avec l'environnement de jeu, et ceux-ci sont généralement interactifs que les humains d'apprendre ŕ bien jouer beaucoup plus.
Récemment, Google a publié un blog post AI, a discuté du modčle de simulation de stratégie d'apprentissage leur modčle vidéo, Lei Feng réseau compilé AI Technology Review résumé suit comme.
Une hypothčse pour expliquer pourquoi les gens peuvent apprendre plus efficacement ces tâches est qu'ils peuvent prédire l'effet de leurs actions, ainsi apprendre implicitement un modčle qui séquence d'actions se traduira par les résultats souhaités. On pense généralement que la mise en place du modčle de jeu que l'on appelle et l'utiliser pour apprendre un bon comportement de choix stratégique, c'est l'apprentissage de renforcement ŕ base de modčles (MBRL) la prémisse principale.
Dans l'algorithme « l'apprentissage de renforcement ŕ base de modčle Atari », nous présentons une étude de simulation de stratégie (SIMPLES), qui est un cadre MBRL pour la formation des agents consoles Atari, son efficacité est nettement plus élevé que la technologie la plus avancée qui exige seulement utiliser l'environnement de jeu interactif d'environ 100K (équivalent ŕ deux heures de temps de jeu en direct) peut montrer des résultats compétitifs. De plus, nous avons le code correspondant sera open source dans le cadre de la base de code open source Tensor2Tensor. Cette version contient le monde un modčle de pré-formation, vous pouvez utiliser une simple opération de ligne de commande, vous pouvez utiliser pour jouer une interface similaire ŕ Atari.
Apprendre modčle mondial SIMPLES
Dans l'ensemble, l'idée derričre le comportement modčle alternatif d'apprentissage du jeu SIMPLES mondial, et utiliser la stratégie d'optimisation du modčle dans un environnement de jeu simulé (en utilisant un apprentissage de renforcement sans modčle). Le principe de base de l'algorithme a été bien établi et de nombreuses applications ŕ base de modčles d'apprentissage de renforcement get.

La boucle principale SIMPLES: 1) commencer ŕ agir en interaction avec l'environnement réel. 2) les données d'observation recueillies pour la mise ŕ jour du modčle mondial actuel. 3) Agent stratégie de mise ŕ jour par l'apprentissage modčle mondial.
Afin de former un modčle de jeu Atari, nous avons d'abord besoin de générer un avenir raisonnable du monde dans l'espace de pixels. En d'autres termes, nous essayons de prévoir l'image suivante en entrant une série d'images qui ont été observées ainsi qu'une commande du jeu émis (comme « gauche », « droite », etc.) ressemblera. Dans l'espace de visualisation est une raison importante pour le monde du train de modčle est qu'il est en fait une forme d'autorégulation, dans lequel le pixel observé forment un signal de surveillance dense et riche dans notre exemple.
Si le modčle d'une formation réussie telle (comme facteur prédictif vidéo), puis une personne a été essentiellement un environnement d'apprentissage jeu de simulation, vous pouvez choisir une série d'actions qui maximisent l'agent de jeu de rendement ŕ long terme. En d'autres termes, nous passons la séquence de simulateur de stratégie modčle mondial / apprentissage pour la formation, plutôt que des séquences du jeu sera une véritable formation de la stratégie, parce que ce dernier en termes de temps et de coűt de calcul est trčs grande.
Notre modčle mondial est un réseau convolutionnel anticipatrice, qui accepte quatre données, prédit image suivante ainsi que des commentaires (voir ci-dessus). Cependant, Atari, l'avenir est incertain, puisque seulement connaître les quatre derničres données. Dans certains cas, par exemple, suspendu au-dessus quatre fois dans le jeu lorsque le tennis de table disparaît du cadre, peut conduire ŕ un modčle de réussite ne peut pas prédire l'image suivante. Nous utilisons une nouvelle architecture de modčle vidéo pour traiter le caractčre aléatoire du problčme, cette architecture mieux dans cet environnement, qui est inspiré par des travaux antérieurs.

Lorsque le modčle SIMPLES au maître de kung fu qui va voir un exemple de problčmes causés par hasard. Dans l'animation, la gauche est la sortie du modčle, le milieu est le fait que le panneau de droite est la différence de pixels entre les deux.
Dans chaque itération, le modčle dans le monde, aprčs la formation, nous avons appris ŕ utiliser ce modčle pour générer l'action, et d'observer les résultats de la séquence d'échantillons, en utilisant l'algorithme pour améliorer la stratégie de jeu d'optimisation de la stratégie proximale (PPO). Un détail important est que les données d'échantillonnage trame de départ de l'ensemble de données réelles. SIMPLES seul ensemble de données de longueur moyenne, qui est due ŕ des erreurs habituellement prévues superposées au fil du temps, ce qui rend trčs difficile de prédire ŕ long terme. Heureusement, l'algorithme PPO peut également apprendre une relation ŕ long terme entre l'action et le retour d'information ŕ partir de sa fonction de valeur interne, la longueur de données donc limitée est suffisante pour écrire des jeux rares (tels que l'autoroute) est.
efficacité sIMPLES
Une mesure du succčs est de prouver que le modčle est efficace. Ŕ cette fin, nous avons évalué la sortie de la politique sur le modčle et l'environnement interagissent 100.000 fois, 100.000 fois cette interaction est équivalente ŕ une personne sur deux heures de jeux en temps réel. Nous avons comparé nos deux SIMPLES des méthodes les plus avancées et le modčle sans méthode RL modčles --Rainbow et PPO dans 26 jeux différents. Dans la plupart des cas, l'efficacité d'échantillonnage est supérieure ŕ d'autres méthodes Méthode 2 fois SIMPLES ou plus.

Aucun algorithme ne modčle ŕ deux (gauche: Rainbow droite: PPO) nombre d'interactions nécessaires, ainsi que fractionnelle nos méthodes de formation disponibles SIMPLES. Les spectacles de ligne rouge le nombre d'interactions, nous avons utilisé la méthode.
succčs sIMPLES
Les résultats de la méthode de Simplé d'encourager: pour lequel deux jeux, Pong et Freeway, dans une formation de l'environnement simulé des agents pour obtenir le meilleur score.
Pour Freeway, Pong et Breakout il peut générer jusqu'ŕ 50 étapes simples au niveau des pixels de prédiction ŕ proximité parfaite, comme le montre la figure.
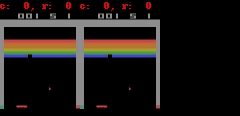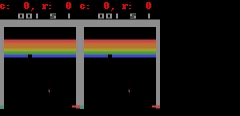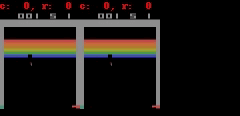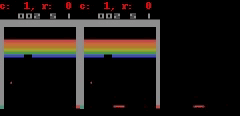

SIMPLES peut faire la prédiction parfaite plus proche du pixel. Dans chacun de l'animation, le côté gauche est la sortie du modčle, l'intermédiaire est une donnée de base, le panneau de droite est la différence de pixels entre les deux animations.
surprise, sIMPLES
Cependant, SIMPLES pas toujours de la prédiction ŕ droite. Le plus commun est l'échec en raison du modčle mondial ne peut pas capturer de prédire avec précision ou de petits objets, mais trčs liés. Par exemple, dans le théâtre Atlantis, les balles sont si petits qu'ils ont tendance ŕ disparaître.

Sur le champ de bataille, nous avons constaté que la partie pertinente du modčle est difficile ŕ prévoir petits, comme des balles.
conclusion
Basé sur le modčle d'apprentissage de renforcement est principalement utilisé dans les coűts élevés d'interaction, lents ou besoin d'environnements d'étiquette manuellement, par exemple dans la tâche multi-robots. Dans un tel environnement, ŕ travers l'étude de simulation afin de mieux comprendre l'environnement de l'agence, et la capacité de renforcer l'apprentissage multi-tâche de fournir des mises ŕ jour, bien meilleur et plus rapide. Bien que SIMPLES pas encore atteint les exigences de performance de la méthode RL sans modčle, mais il est en fait plus efficace, nous espérons améliorer encore les performances du modčle technologique.
Si vous souhaitez développer vos propres modčles et expériences, le lieu et notre base de connaissances et colab, oů vous pouvez trouver des informations sur la façon d'utiliser le modčle mondial préalablement formé avec des instructions pour reproduire notre travail.
documents connexes traitent:
https://arxiv.org/abs/1903.00374
via:
https://ai.googleblog.com/2019/03/simulated-policy-learning-in-video.html

Cliquez sur Lire l'original , vue Google open source d'apprentissage pour renforcer la profondeur du réseau de planification PlaNet